 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Generation via Latent Factor Simulation for Fairness-aware Re-ranking
Sep 21, 2024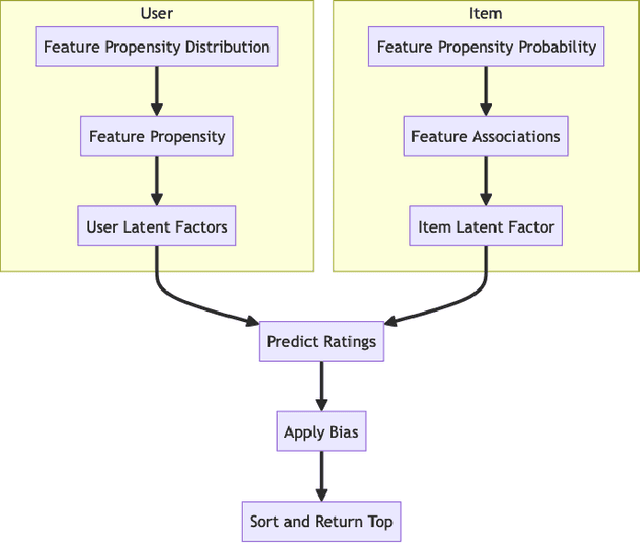

Synthetic data is a useful resource for algorithmic research. It allows for the evaluation of systems under a range of conditions that might be difficult to achieve in real world settings. In recommender systems, the use of synthetic data is somewhat limited; some work has concentrated on building user-item interaction data at large scale. We believe that fairness-aware recommendation research can benefit from simulated data as it allows the study of protected groups and their interactions without depending on sensitive data that needs privacy protection. In this paper, we propose a novel type of data for fairness-aware recommendation: synthetic recommender system outputs that can be used to study re-ranking algorithms.
Exploring Social Choice Mechanisms for Recommendation Fairness in SCRUF
Sep 10, 2023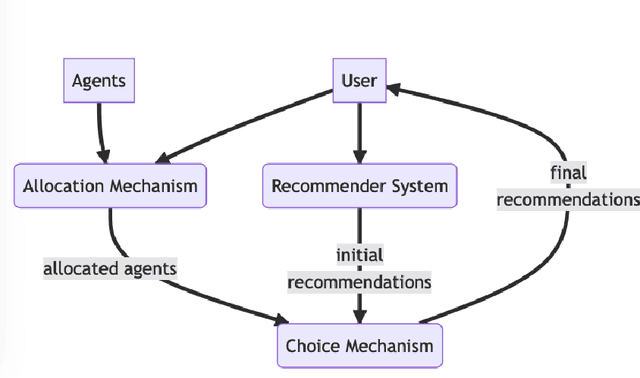
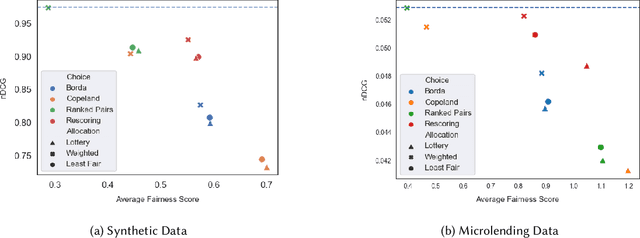
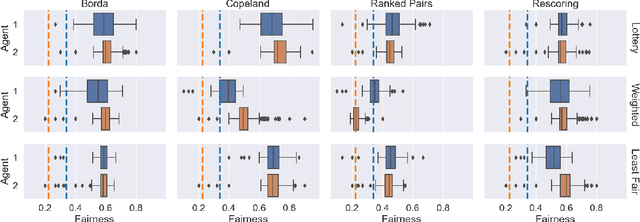
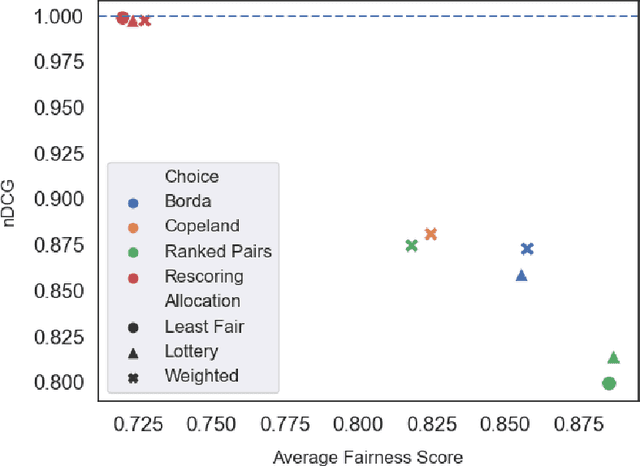
Fairness problems in recommender systems often have a complexity in practice that is not adequately captured in simplified research formulations. A social choice formulation of the fairness problem, operating within a multi-agent architecture of fairness concerns, offers a flexible and multi-aspect alternative to fairness-aware recommendation approaches. Leveraging social choice allows for increased generality and the possibility of tapping into well-studied social choice algorithms for resolving the tension between multiple, competing fairness concerns. This paper explores a range of options for choice mechanisms in multi-aspect fairness applications using both real and synthetic data and shows that different classes of choice and allocation mechanisms yield different but consistent fairness / accuracy tradeoffs. We also show that a multi-agent formulation offers flexibility in adapting to user population dynamics.
Auditing YouTube's Recommendation Algorithm for Misinformation Filter Bubbles
Oct 18, 2022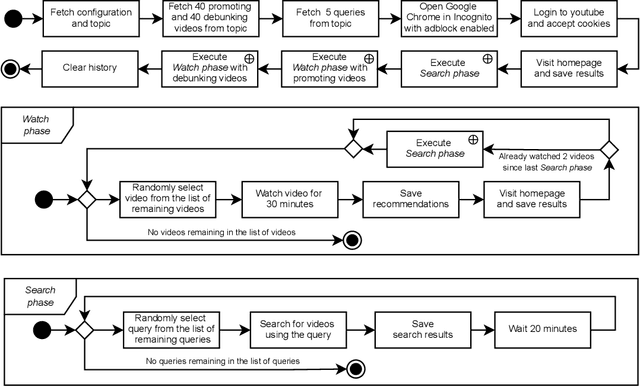
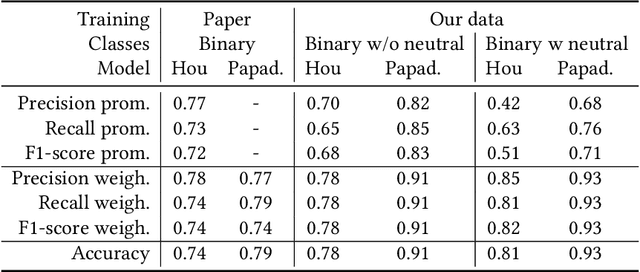
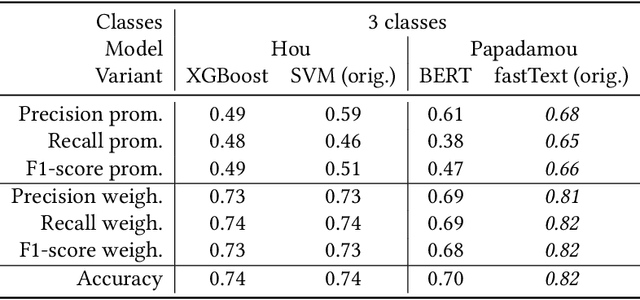
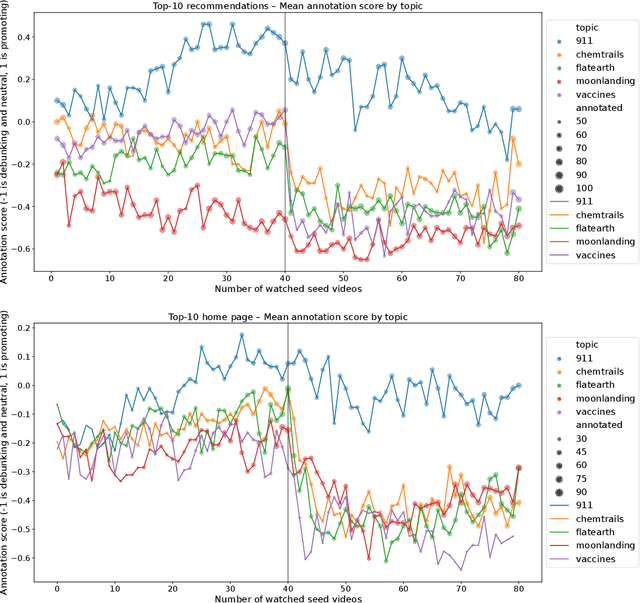
In this paper, we present results of an auditing study performed over YouTube aimed at investigating how fast a user can get into a misinformation filter bubble, but also what it takes to "burst the bubble", i.e., revert the bubble enclosure. We employ a sock puppet audit methodology, in which pre-programmed agents (acting as YouTube users) delve into misinformation filter bubbles by watching misinformation promoting content. Then they try to burst the bubbles and reach more balanced recommendations by watching misinformation debunking content. We record search results, home page results, and recommendations for the watched videos. Overall, we recorded 17,405 unique videos, out of which we manually annotated 2,914 for the presence of misinformation. The labeled data was used to train a machine learning model classifying videos into three classes (promoting, debunking, neutral) with the accuracy of 0.82. We use the trained model to classify the remaining videos that would not be feasible to annotate manually. Using both the manually and automatically annotated data, we observe the misinformation bubble dynamics for a range of audited topics. Our key finding is that even though filter bubbles do not appear in some situations, when they do, it is possible to burst them by watching misinformation debunking content (albeit it manifests differently from topic to topic). We also observe a sudden decrease of misinformation filter bubble effect when misinformation debunking videos are watched after misinformation promoting videos, suggesting a strong contextuality of recommendations. Finally, when comparing our results with a previous similar study, we do not observe significant improvements in the overall quantity of recommended misinformation content.
Monant Medical Misinformation Dataset: Mapping Articles to Fact-Checked Claims
Apr 26, 2022
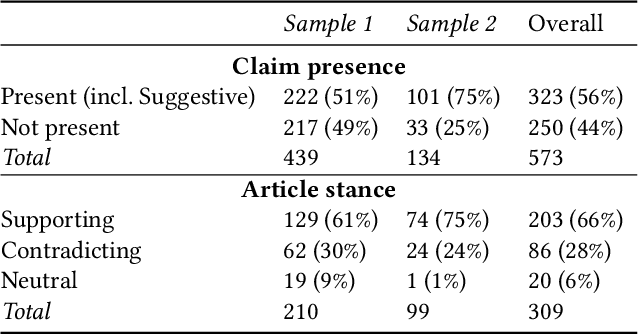
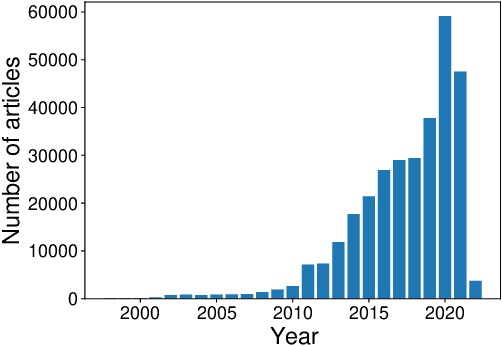

False information has a significant negative influence on individuals as well as on the whole society. Especially in the current COVID-19 era, we witness an unprecedented growth of medical misinformation. To help tackle this problem with machine learning approaches, we are publishing a feature-rich dataset of approx. 317k medical news articles/blogs and 3.5k fact-checked claims. It also contains 573 manually and more than 51k automatically labelled mappings between claims and articles. Mappings consist of claim presence, i.e., whether a claim is contained in a given article, and article stance towards the claim. We provide several baselines for these two tasks and evaluate them on the manually labelled part of the dataset. The dataset enables a number of additional tasks related to medical misinformation, such as misinformation characterisation studies or studies of misinformation diffusion between sources.
* 11 pages, 4 figures, SIGIR 2022 Resource paper track
An Audit of Misinformation Filter Bubbles on YouTube: Bubble Bursting and Recent Behavior Changes
Mar 25, 2022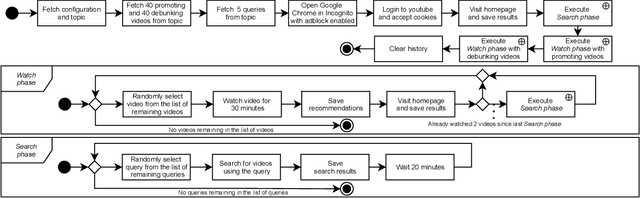


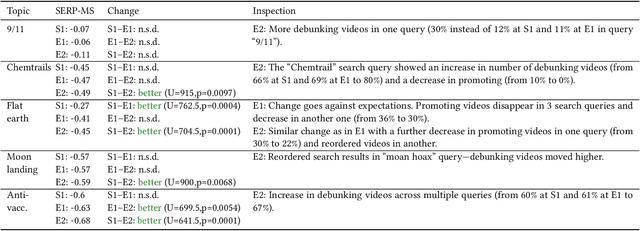
The negative effects of misinformation filter bubbles in adaptive systems have been known to researchers for some time. Several studies investigated, most prominently on YouTube, how fast a user can get into a misinformation filter bubble simply by selecting wrong choices from the items offered. Yet, no studies so far have investigated what it takes to burst the bubble, i.e., revert the bubble enclosure. We present a study in which pre-programmed agents (acting as YouTube users) delve into misinformation filter bubbles by watching misinformation promoting content (for various topics). Then, by watching misinformation debunking content, the agents try to burst the bubbles and reach more balanced recommendation mixes. We recorded the search results and recommendations, which the agents encountered, and analyzed them for the presence of misinformation. Our key finding is that bursting of a filter bubble is possible, albeit it manifests differently from topic to topic. Moreover, we observe that filter bubbles do not truly appear in some situations. We also draw a direct comparison with a previous study. Sadly, we did not find much improvements in misinformation occurrences, despite recent pledges by YouTube.
* RecSys '21: Fifteenth ACM Conference on Recommender System