 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGloss2Text: Sign Language Gloss translation using LLMs and Semantically Aware Label Smoothing
Jul 01, 2024



Sign language translation from video to spoken text presents unique challenges owing to the distinct grammar, expression nuances, and high variation of visual appearance across different speakers and contexts. The intermediate gloss annotations of videos aim to guide the translation process. In our work, we focus on {\em Gloss2Text} translation stage and propose several advances by leveraging pre-trained large language models (LLMs), data augmentation, and novel label-smoothing loss function exploiting gloss translation ambiguities improving significantly the performance of state-of-the-art approaches. Through extensive experiments and ablation studies on the PHOENIX Weather 2014T dataset, our approach surpasses state-of-the-art performance in {\em Gloss2Text} translation, indicating its efficacy in addressing sign language translation and suggesting promising avenues for future research and development.
Fingerspelling PoseNet: Enhancing Fingerspelling Translation with Pose-Based Transformer Models
Nov 20, 2023We address the task of American Sign Language fingerspelling translation using videos in the wild. We exploit advances in more accurate hand pose estimation and propose a novel architecture that leverages the transformer based encoder-decoder model enabling seamless contextual word translation. The translation model is augmented by a novel loss term that accurately predicts the length of the finger-spelled word, benefiting both training and inference. We also propose a novel two-stage inference approach that re-ranks the hypotheses using the language model capabilities of the decoder. Through extensive experiments, we demonstrate that our proposed method outperforms the state-of-the-art models on ChicagoFSWild and ChicagoFSWild+ achieving more than 10% relative improvement in performance. Our findings highlight the effectiveness of our approach and its potential to advance fingerspelling recognition in sign language translation. Code is also available at https://github.com/pooyafayyaz/Fingerspelling-PoseNet.
U2RLE: Uncertainty-Guided 2-Stage Room Layout Estimation
Apr 17, 2023



While the existing deep learning-based room layout estimation techniques demonstrate good overall accuracy, they are less effective for distant floor-wall boundary. To tackle this problem, we propose a novel uncertainty-guided approach for layout boundary estimation introducing new two-stage CNN architecture termed U2RLE. The initial stage predicts both floor-wall boundary and its uncertainty and is followed by the refinement of boundaries with high positional uncertainty using a different, distance-aware loss. Finally, outputs from the two stages are merged to produce the room layout. Experiments using ZInD and Structure3D datasets show that U2RLE improves over current state-of-the-art, being able to handle both near and far walls better. In particular, U2RLE outperforms current state-of-the-art techniques for the most distant walls.
Review on 6D Object Pose Estimation with the focus on Indoor Scene Understanding
Dec 04, 2022



6D object pose estimation problem has been extensively studied in the field of Computer Vision and Robotics. It has wide range of applications such as robot manipulation, augmented reality, and 3D scene understanding. With the advent of Deep Learning, many breakthroughs have been made; however, approaches continue to struggle when they encounter unseen instances, new categories, or real-world challenges such as cluttered backgrounds and occlusions. In this study, we will explore the available methods based on input modality, problem formulation, and whether it is a category-level or instance-level approach. As a part of our discussion, we will focus on how 6D object pose estimation can be used for understanding 3D scenes.
Deep representation learning: Fundamentals, Perspectives, Applications, and Open Challenges
Nov 27, 2022
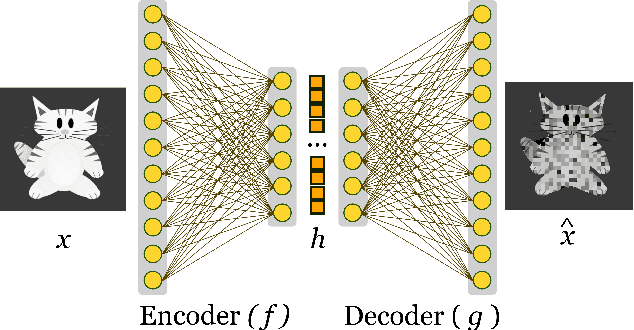
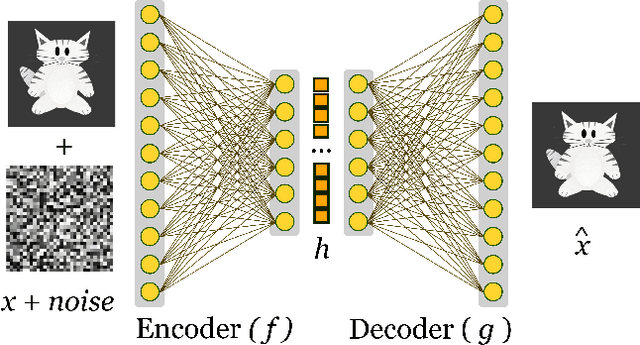
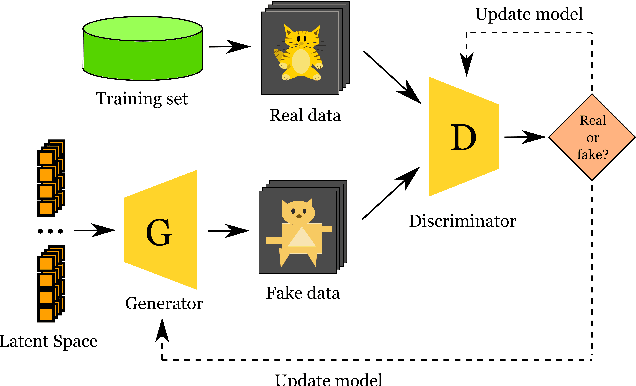
Machine Learning algorithms have had a profound impact on the field of computer science over the past few decades. These algorithms performance is greatly influenced by the representations that are derived from the data in the learning process. The representations learned in a successful learning process should be concise, discrete, meaningful, and able to be applied across a variety of tasks. A recent effort has been directed toward developing Deep Learning models, which have proven to be particularly effective at capturing high-dimensional, non-linear, and multi-modal characteristics. In this work, we discuss the principles and developments that have been made in the process of learning representations, and converting them into desirable applications. In addition, for each framework or model, the key issues and open challenges, as well as the advantages, are examined.
Object Pose Estimation using Mid-level Visual Representations
Mar 02, 2022
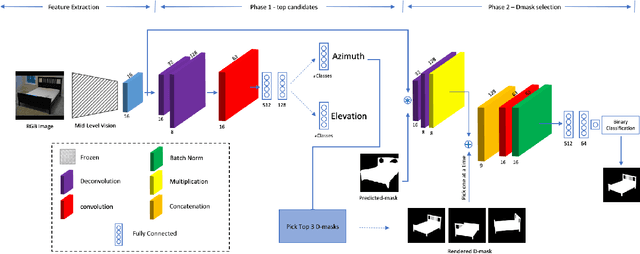

This work proposes a novel pose estimation model for object categories that can be effectively transferred to previously unseen environments. The deep convolutional network models (CNN) for pose estimation are typically trained and evaluated on datasets specifically curated for object detection, pose estimation, or 3D reconstruction, which requires large amounts of training data. In this work, we propose a model for pose estimation that can be trained with small amount of data and is built on the top of generic mid-level representations \cite{taskonomy2018} (e.g. surface normal estimation and re-shading). These representations are trained on a large dataset without requiring pose and object annotations. Later on, the predictions are refined with a small CNN neural network that exploits object masks and silhouette retrieval. The presented approach achieves superior performance on the Pix3D dataset \cite{pix3d} and shows nearly 35\% improvement over the existing models when only 25\% of the training data is available. We show that the approach is favorable when it comes to generalization and transfer to novel environments. Towards this end, we introduce a new pose estimation benchmark for commonly encountered furniture categories on challenging Active Vision Dataset \cite{Ammirato2017ADF} and evaluated the models trained on the Pix3D dataset.