 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Pose Estimation using Mid-level Visual Representations
Paper and Code

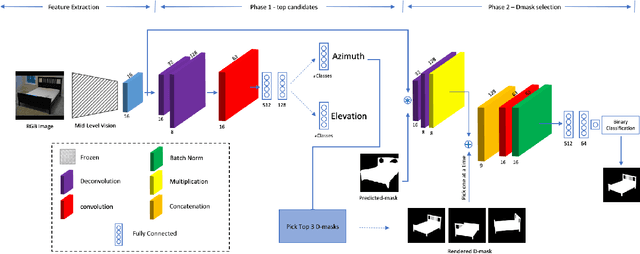

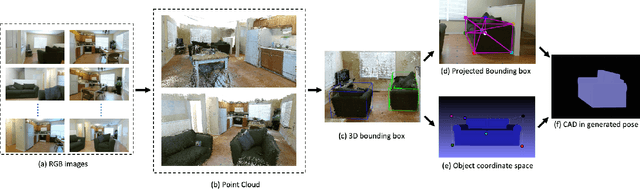
This work proposes a novel pose estimation model for object categories that can be effectively transferred to previously unseen environments. The deep convolutional network models (CNN) for pose estimation are typically trained and evaluated on datasets specifically curated for object detection, pose estimation, or 3D reconstruction, which requires large amounts of training data. In this work, we propose a model for pose estimation that can be trained with small amount of data and is built on the top of generic mid-level representations \cite{taskonomy2018} (e.g. surface normal estimation and re-shading). These representations are trained on a large dataset without requiring pose and object annotations. Later on, the predictions are refined with a small CNN neural network that exploits object masks and silhouette retrieval. The presented approach achieves superior performance on the Pix3D dataset \cite{pix3d} and shows nearly 35\% improvement over the existing models when only 25\% of the training data is available. We show that the approach is favorable when it comes to generalization and transfer to novel environments. Towards this end, we introduce a new pose estimation benchmark for commonly encountered furniture categories on challenging Active Vision Dataset \cite{Ammirato2017ADF} and evaluated the models trained on the Pix3D dataset.