 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Spatial Reasoning with Open Vocabulary Object Detectors
Oct 09, 2024
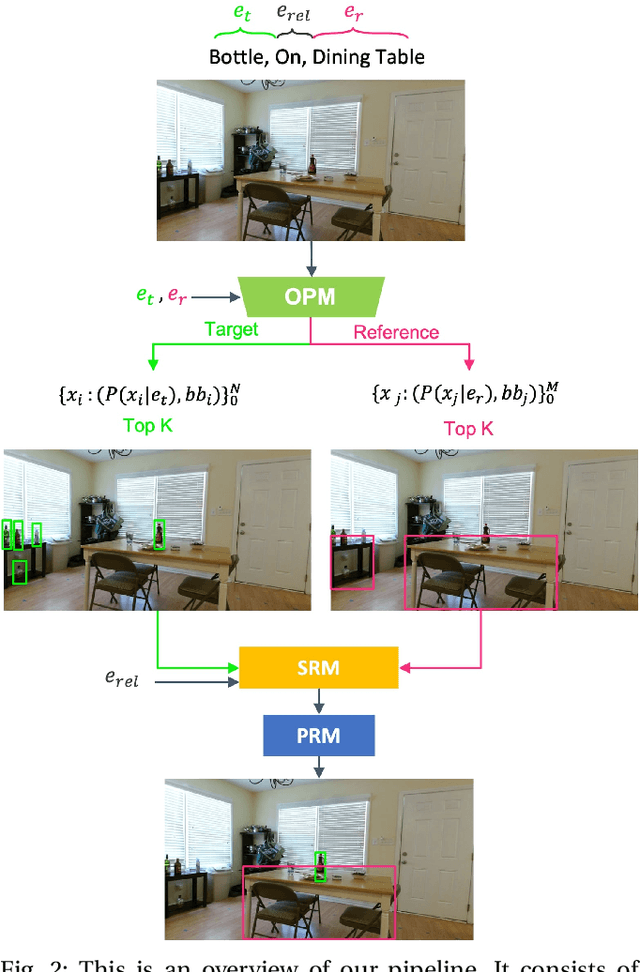
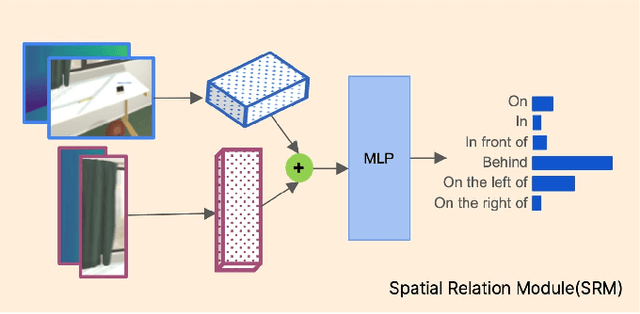

Reasoning about spatial relationships between objects is essential for many real-world robotic tasks, such as fetch-and-delivery, object rearrangement, and object search. The ability to detect and disambiguate different objects and identify their location is key to successful completion of these tasks. Several recent works have used powerful Vision and Language Models (VLMs) to unlock this capability in robotic agents. In this paper we introduce a structured probabilistic approach that integrates rich 3D geometric features with state-of-the-art open-vocabulary object detectors to enhance spatial reasoning for robotic perception. The approach is evaluated and compared against zero-shot performance of the state-of-the-art Vision and Language Models (VLMs) on spatial reasoning tasks. To enable this comparison, we annotate spatial clauses in real-world RGB-D Active Vision Dataset [1] and conduct experiments on this and the synthetic Semantic Abstraction [2] dataset. Results demonstrate the effectiveness of the proposed method, showing superior performance of grounding spatial relations over state of the art open-source VLMs by more than 20%.
Fingerspelling PoseNet: Enhancing Fingerspelling Translation with Pose-Based Transformer Models
Nov 20, 2023We address the task of American Sign Language fingerspelling translation using videos in the wild. We exploit advances in more accurate hand pose estimation and propose a novel architecture that leverages the transformer based encoder-decoder model enabling seamless contextual word translation. The translation model is augmented by a novel loss term that accurately predicts the length of the finger-spelled word, benefiting both training and inference. We also propose a novel two-stage inference approach that re-ranks the hypotheses using the language model capabilities of the decoder. Through extensive experiments, we demonstrate that our proposed method outperforms the state-of-the-art models on ChicagoFSWild and ChicagoFSWild+ achieving more than 10% relative improvement in performance. Our findings highlight the effectiveness of our approach and its potential to advance fingerspelling recognition in sign language translation. Code is also available at https://github.com/pooyafayyaz/Fingerspelling-PoseNet.
Graph-CoVis: GNN-based Multi-view Panorama Global Pose Estimation
Apr 26, 2023



In this paper, we address the problem of wide-baseline camera pose estimation from a group of 360$^\circ$ panoramas under upright-camera assumption. Recent work has demonstrated the merit of deep-learning for end-to-end direct relative pose regression in 360$^\circ$ panorama pairs [11]. To exploit the benefits of multi-view logic in a learning-based framework, we introduce Graph-CoVis, which non-trivially extends CoVisPose [11] from relative two-view to global multi-view spherical camera pose estimation. Graph-CoVis is a novel Graph Neural Network based architecture that jointly learns the co-visible structure and global motion in an end-to-end and fully-supervised approach. Using the ZInD [4] dataset, which features real homes presenting wide-baselines, occlusion, and limited visual overlap, we show that our model performs competitively to state-of-the-art approaches.
Review on 6D Object Pose Estimation with the focus on Indoor Scene Understanding
Dec 04, 2022



6D object pose estimation problem has been extensively studied in the field of Computer Vision and Robotics. It has wide range of applications such as robot manipulation, augmented reality, and 3D scene understanding. With the advent of Deep Learning, many breakthroughs have been made; however, approaches continue to struggle when they encounter unseen instances, new categories, or real-world challenges such as cluttered backgrounds and occlusions. In this study, we will explore the available methods based on input modality, problem formulation, and whether it is a category-level or instance-level approach. As a part of our discussion, we will focus on how 6D object pose estimation can be used for understanding 3D scenes.
Object Pose Estimation using Mid-level Visual Representations
Mar 02, 2022
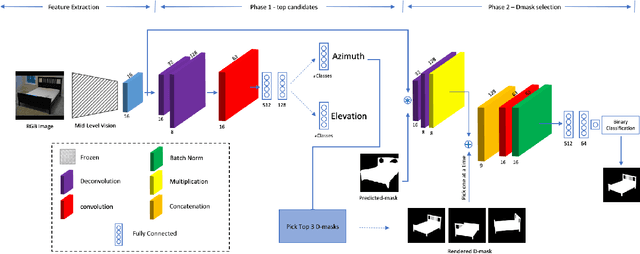

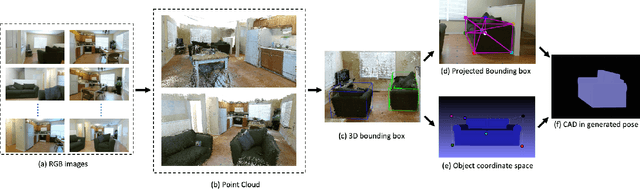
This work proposes a novel pose estimation model for object categories that can be effectively transferred to previously unseen environments. The deep convolutional network models (CNN) for pose estimation are typically trained and evaluated on datasets specifically curated for object detection, pose estimation, or 3D reconstruction, which requires large amounts of training data. In this work, we propose a model for pose estimation that can be trained with small amount of data and is built on the top of generic mid-level representations \cite{taskonomy2018} (e.g. surface normal estimation and re-shading). These representations are trained on a large dataset without requiring pose and object annotations. Later on, the predictions are refined with a small CNN neural network that exploits object masks and silhouette retrieval. The presented approach achieves superior performance on the Pix3D dataset \cite{pix3d} and shows nearly 35\% improvement over the existing models when only 25\% of the training data is available. We show that the approach is favorable when it comes to generalization and transfer to novel environments. Towards this end, we introduce a new pose estimation benchmark for commonly encountered furniture categories on challenging Active Vision Dataset \cite{Ammirato2017ADF} and evaluated the models trained on the Pix3D dataset.