 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Image-Text Matching and Retrieval by Grounding Entities
May 04, 2025

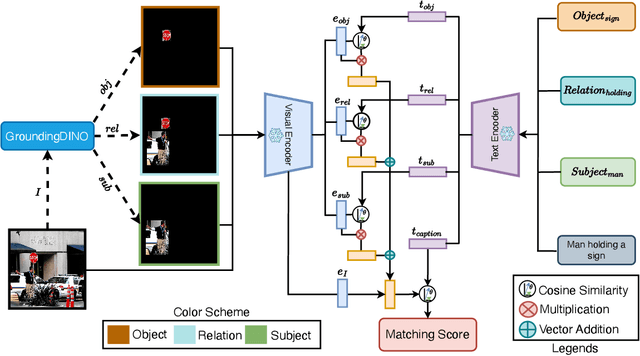
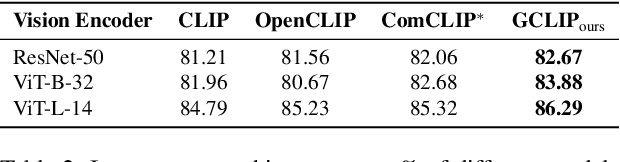
Vision-language pretraining on large datasets of images-text pairs is one of the main building blocks of current Vision-Language Models. While with additional training, these models excel in various downstream tasks, including visual question answering, image captioning, and visual commonsense reasoning. However, a notable weakness of pretrained models like CLIP, is their inability to perform entity grounding and compositional image and text matching~\cite{Jiang2024ComCLIP, yang2023amc, Rajabi2023GroundedVSR, learninglocalizeCVPR24}. In this work we propose a novel learning-free zero-shot augmentation of CLIP embeddings that has favorable compositional properties. We compute separate embeddings of sub-images of object entities and relations that are localized by the state of the art open vocabulary detectors and dynamically adjust the baseline global image embedding. % The final embedding is obtained by computing a weighted combination of the sub-image embeddings. The resulting embedding is then utilized for similarity computation with text embedding, resulting in a average 1.5\% improvement in image-text matching accuracy on the Visual Genome and SVO Probes datasets~\cite{krishna2017visualgenome, svo}. Notably, the enhanced embeddings demonstrate superior retrieval performance, thus achieving significant gains on the Flickr30K and MS-COCO retrieval benchmarks~\cite{flickr30ke, mscoco}, improving the state-of-the-art Recall@1 by 12\% and 0.4\%, respectively. Our code is available at https://github.com/madhukarreddyvongala/GroundingCLIP.
Structured Spatial Reasoning with Open Vocabulary Object Detectors
Oct 09, 2024
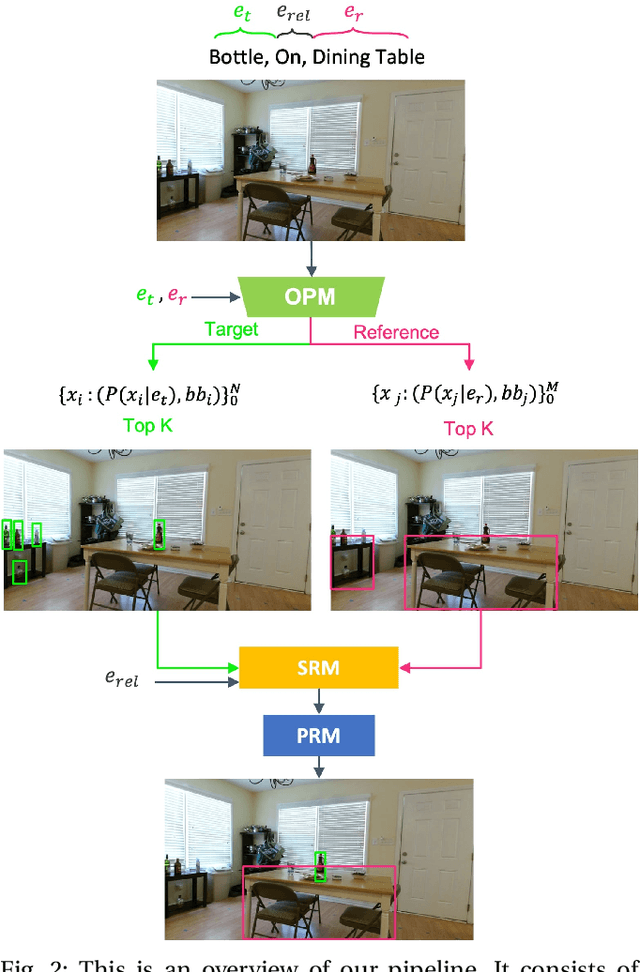
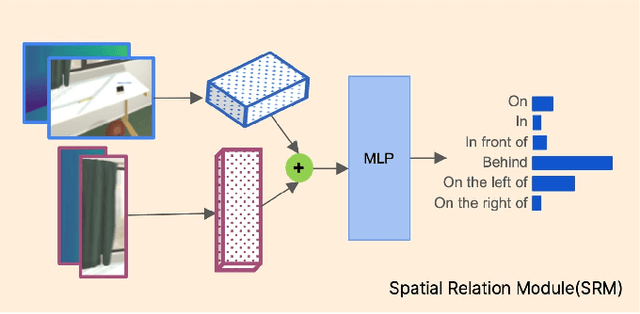

Reasoning about spatial relationships between objects is essential for many real-world robotic tasks, such as fetch-and-delivery, object rearrangement, and object search. The ability to detect and disambiguate different objects and identify their location is key to successful completion of these tasks. Several recent works have used powerful Vision and Language Models (VLMs) to unlock this capability in robotic agents. In this paper we introduce a structured probabilistic approach that integrates rich 3D geometric features with state-of-the-art open-vocabulary object detectors to enhance spatial reasoning for robotic perception. The approach is evaluated and compared against zero-shot performance of the state-of-the-art Vision and Language Models (VLMs) on spatial reasoning tasks. To enable this comparison, we annotate spatial clauses in real-world RGB-D Active Vision Dataset [1] and conduct experiments on this and the synthetic Semantic Abstraction [2] dataset. Results demonstrate the effectiveness of the proposed method, showing superior performance of grounding spatial relations over state of the art open-source VLMs by more than 20%.