 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussFusion: Improving 3D Reconstruction in the Wild with A Geometry-Informed Video Generator
Mar 26, 2026We present GaussFusion, a novel approach for improving 3D Gaussian splatting (3DGS) reconstructions in the wild through geometry-informed video generation. GaussFusion mitigates common 3DGS artifacts, including floaters, flickering, and blur caused by camera pose errors, incomplete coverage, and noisy geometry initialization. Unlike prior RGB-based approaches limited to a single reconstruction pipeline, our method introduces a geometry-informed video-to-video generator that refines 3DGS renderings across both optimization-based and feed-forward methods. Given an existing reconstruction, we render a Gaussian primitive video buffer encoding depth, normals, opacity, and covariance, which the generator refines to produce temporally coherent, artifact-free frames. We further introduce an artifact synthesis pipeline that simulates diverse degradation patterns, ensuring robustness and generalization. GaussFusion achieves state-of-the-art performance on novel-view synthesis benchmarks, and an efficient variant runs in real time at 21 FPS while maintaining similar performance, enabling interactive 3D applications.
SALVe: Semantic Alignment Verification for Floorplan Reconstruction from Sparse Panoramas
Jun 27, 2024We propose a new system for automatic 2D floorplan reconstruction that is enabled by SALVe, our novel pairwise learned alignment verifier. The inputs to our system are sparsely located 360$^\circ$ panoramas, whose semantic features (windows, doors, and openings) are inferred and used to hypothesize pairwise room adjacency or overlap. SALVe initializes a pose graph, which is subsequently optimized using GTSAM. Once the room poses are computed, room layouts are inferred using HorizonNet, and the floorplan is constructed by stitching the most confident layout boundaries. We validate our system qualitatively and quantitatively as well as through ablation studies, showing that it outperforms state-of-the-art SfM systems in completeness by over 200%, without sacrificing accuracy. Our results point to the significance of our work: poses of 81% of panoramas are localized in the first 2 connected components (CCs), and 89% in the first 3 CCs. Code and models are publicly available at https://github.com/zillow/salve.
Graph-CoVis: GNN-based Multi-view Panorama Global Pose Estimation
Apr 26, 2023



In this paper, we address the problem of wide-baseline camera pose estimation from a group of 360$^\circ$ panoramas under upright-camera assumption. Recent work has demonstrated the merit of deep-learning for end-to-end direct relative pose regression in 360$^\circ$ panorama pairs [11]. To exploit the benefits of multi-view logic in a learning-based framework, we introduce Graph-CoVis, which non-trivially extends CoVisPose [11] from relative two-view to global multi-view spherical camera pose estimation. Graph-CoVis is a novel Graph Neural Network based architecture that jointly learns the co-visible structure and global motion in an end-to-end and fully-supervised approach. Using the ZInD [4] dataset, which features real homes presenting wide-baselines, occlusion, and limited visual overlap, we show that our model performs competitively to state-of-the-art approaches.
LASER: LAtent SpacE Rendering for 2D Visual Localization
Apr 01, 2022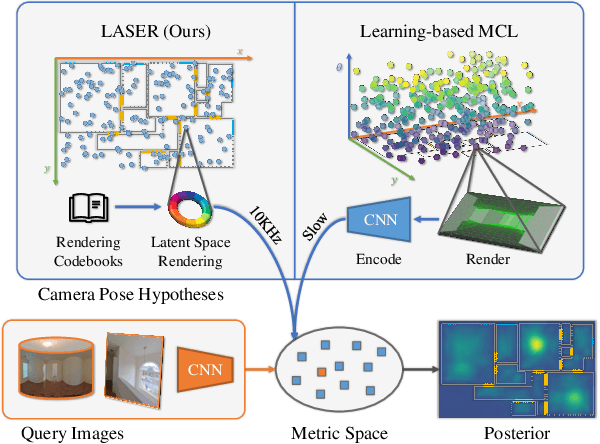
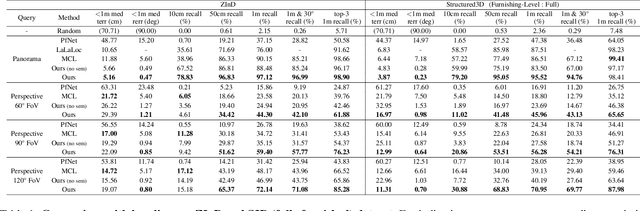
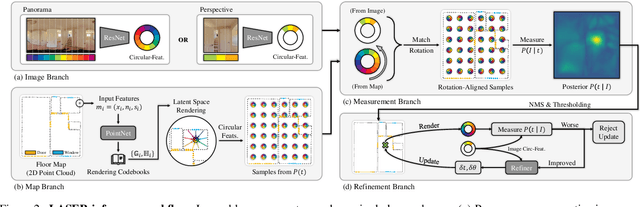
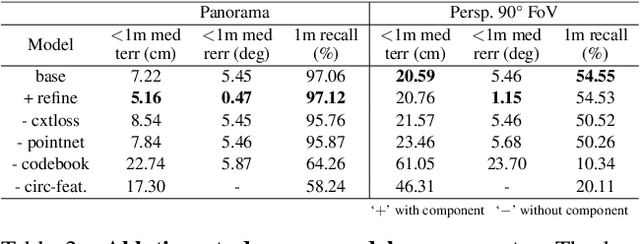
We present LASER, an image-based Monte Carlo Localization (MCL) framework for 2D floor maps. LASER introduces the concept of latent space rendering, where 2D pose hypotheses on the floor map are directly rendered into a geometrically-structured latent space by aggregating viewing ray features. Through a tightly coupled rendering codebook scheme, the viewing ray features are dynamically determined at rendering-time based on their geometries (i.e. length, incident-angle), endowing our representation with view-dependent fine-grain variability. Our codebook scheme effectively disentangles feature encoding from rendering, allowing the latent space rendering to run at speeds above 10KHz. Moreover, through metric learning, our geometrically-structured latent space is common to both pose hypotheses and query images with arbitrary field of views. As a result, LASER achieves state-of-the-art performance on large-scale indoor localization datasets (i.e. ZInD and Structured3D) for both panorama and perspective image queries, while significantly outperforming existing learning-based methods in speed.
Lifelong update of semantic maps in dynamic environments
Oct 17, 2020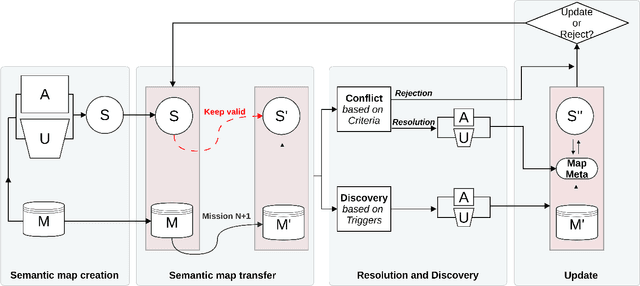
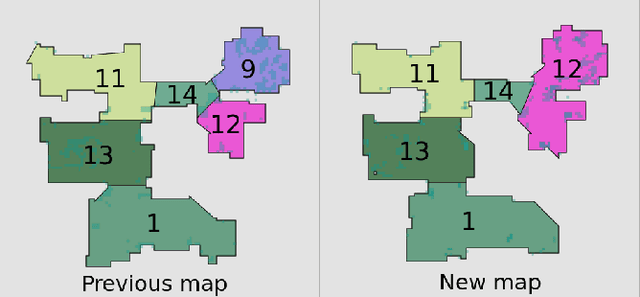
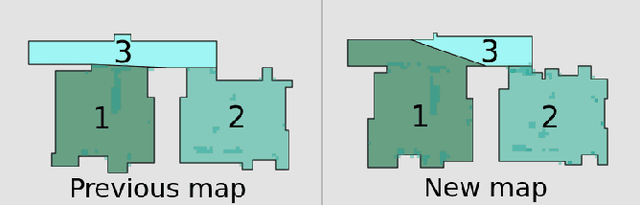
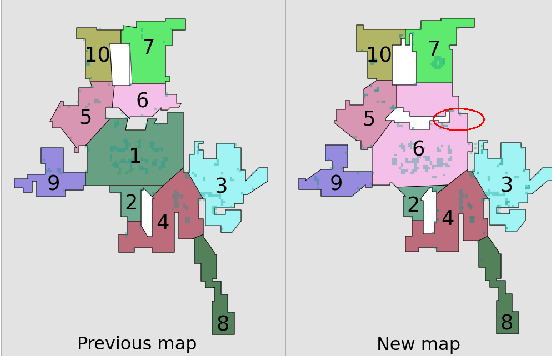
A robot understands its world through the raw information it senses from its surroundings. This raw information is not suitable as a shared representation between the robot and its user. A semantic map, containing high-level information that both the robot and user understand, is better suited to be a shared representation. We use the semantic map as the user-facing interface on our fleet of floor-cleaning robots. Jitter in the robot's sensed raw map, dynamic objects in the environment, and exploration of new space by the robot are common challenges for robots. Solving these challenges effectively in the context of semantic maps is key to enabling semantic maps for lifelong mapping. First, as a robot senses new changes and alters its raw map in successive runs, the semantics must be updated appropriately. We update the map using a spatial transfer of semantics. Second, it is important to keep semantics and their relative constraints consistent even in the presence of dynamic objects. Inconsistencies are automatically determined and resolved through the introduction of a map layer of meta-semantics. Finally, a discovery phase allows the semantic map to be updated with new semantics whenever the robot uncovers new information. Deployed commercially on thousands of floor-cleaning robots in real homes, our user-facing semantic maps provide a intuitive user experience through a lifelong mapping robot.
View management for lifelong visual maps
Aug 09, 2019
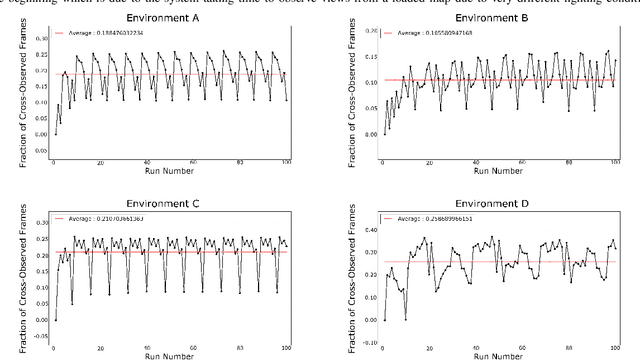
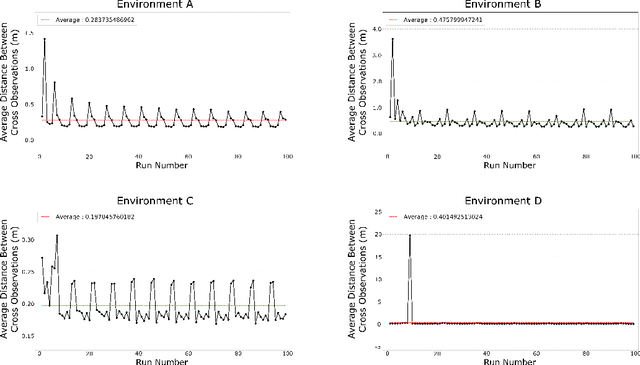

The time complexity of making observations and loop closures in a graph-based visual SLAM system is a function of the number of views stored. Clever algorithms, such as approximate nearest neighbor search, can make this function sub-linear. Despite this, over time the number of views can still grow to a point at which the speed and/or accuracy of the system becomes unacceptable, especially in computation- and memory-constrained SLAM systems. However, not all views are created equal. Some views are rarely observed, because they have been created in an unusual lighting condition, or from low quality images, or in a location whose appearance has changed. These views can be removed to improve the overall performance of a SLAM system. In this paper, we propose a method for pruning views in a visual SLAM system to maintain its speed and accuracy for long term use.
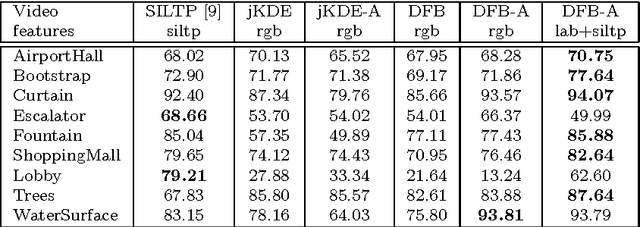
Background Modeling Using Adaptive Pixelwise Kernel Variances in a Hybrid Feature Space
Nov 05, 2015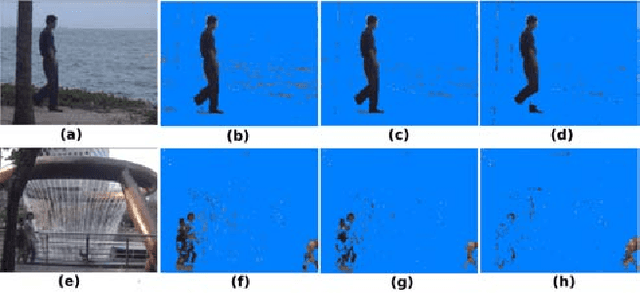
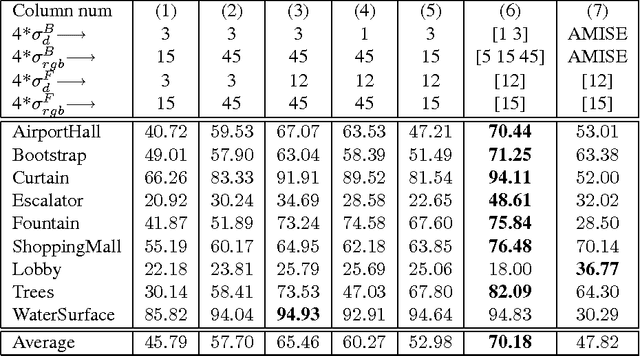
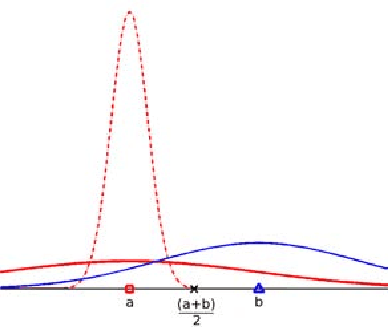

Recent work on background subtraction has shown developments on two major fronts. In one, there has been increasing sophistication of probabilistic models, from mixtures of Gaussians at each pixel [7], to kernel density estimates at each pixel [1], and more recently to joint domainrange density estimates that incorporate spatial information [6]. Another line of work has shown the benefits of increasingly complex feature representations, including the use of texture information, local binary patterns, and recently scale-invariant local ternary patterns [4]. In this work, we use joint domain-range based estimates for background and foreground scores and show that dynamically choosing kernel variances in our kernel estimates at each individual pixel can significantly improve results. We give a heuristic method for selectively applying the adaptive kernel calculations which is nearly as accurate as the full procedure but runs much faster. We combine these modeling improvements with recently developed complex features [4] and show significant improvements on a standard backgrounding benchmark.
Background subtraction - separating the modeling and the inference
Nov 05, 2015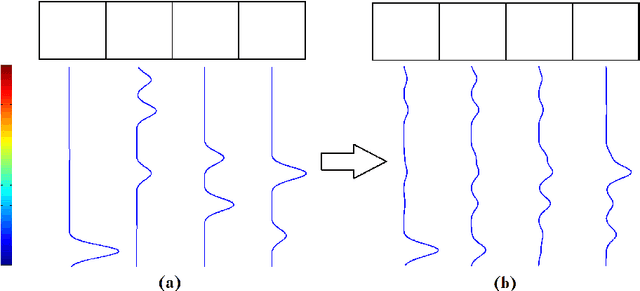
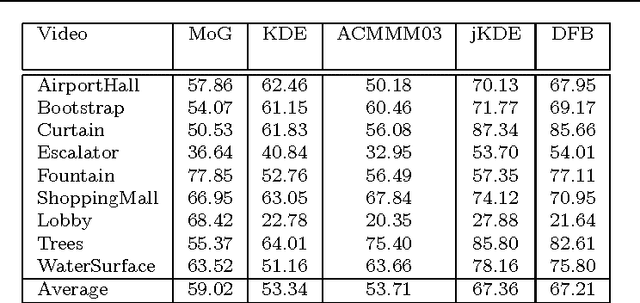
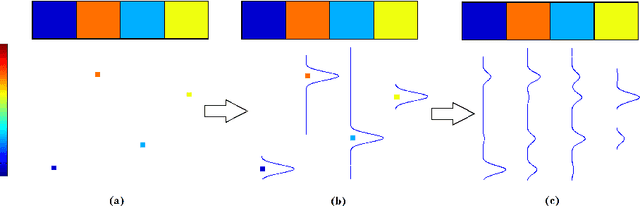
In its early implementations, background modeling was a process of building a model for the background of a video with a stationary camera, and identifying pixels that did not conform well to this model. The pixels that were not well-described by the background model were assumed to be moving objects. Many systems today maintain models for the foreground as well as the background, and these models compete to explain the pixels in a video. In this paper, we argue that the logical endpoint of this evolution is to simply use Bayes' rule to classify pixels. In particular, it is essential to have a background likelihood, a foreground likelihood, and a prior at each pixel. A simple application of Bayes' rule then gives a posterior probability over the label. The only remaining question is the quality of the component models: the background likelihood, the foreground likelihood, and the prior. We describe a model for the likelihoods that is built by using not only the past observations at a given pixel location, but by also including observations in a spatial neighborhood around the location. This enables us to model the influence between neighboring pixels and is an improvement over earlier pixelwise models that do not allow for such influence. Although similar in spirit to the joint domain-range model, we show that our model overcomes certain deficiencies in that model. We use a spatially dependent prior for the background and foreground. The background and foreground labels from the previous frame, after spatial smoothing to account for movement of objects,are used to build the prior for the current frame.
* 19 pages, 6 figures, Machine Vision and Applications journal
Coherent Motion Segmentation in Moving Camera Videos using Optical Flow Orientations
Nov 05, 2015
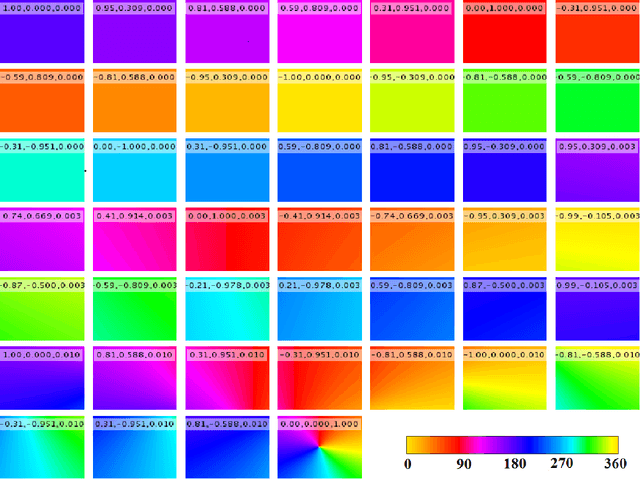

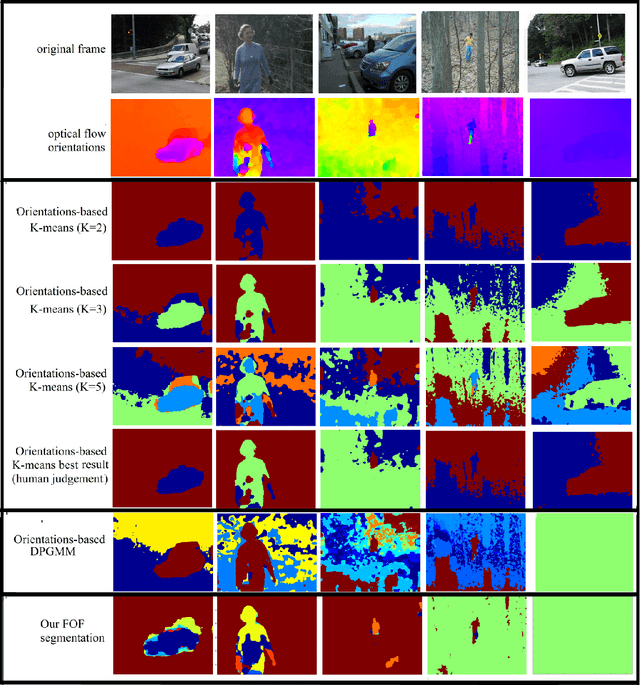
In moving camera videos, motion segmentation is commonly performed using the image plane motion of pixels, or optical flow. However, objects that are at different depths from the camera can exhibit different optical flows even if they share the same real-world motion. This can cause a depth-dependent segmentation of the scene. Our goal is to develop a segmentation algorithm that clusters pixels that have similar real-world motion irrespective of their depth in the scene. Our solution uses optical flow orientations instead of the complete vectors and exploits the well-known property that under camera translation, optical flow orientations are independent of object depth. We introduce a probabilistic model that automatically estimates the number of observed independent motions and results in a labeling that is consistent with real-world motion in the scene. The result of our system is that static objects are correctly identified as one segment, even if they are at different depths. Color features and information from previous frames in the video sequence are used to correct occasional errors due to the orientation-based segmentation. We present results on more than thirty videos from different benchmarks. The system is particularly robust on complex background scenes containing objects at significantly different depths