 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiBARLE: imBalance-Aware Room Layout Estimation
Aug 29, 2023



Room layout estimation predicts layouts from a single panorama. It requires datasets with large-scale and diverse room shapes to train the models. However, there are significant imbalances in real-world datasets including the dimensions of layout complexity, camera locations, and variation in scene appearance. These issues considerably influence the model training performance. In this work, we propose the imBalance-Aware Room Layout Estimation (iBARLE) framework to address these issues. iBARLE consists of (1) Appearance Variation Generation (AVG) module, which promotes visual appearance domain generalization, (2) Complex Structure Mix-up (CSMix) module, which enhances generalizability w.r.t. room structure, and (3) a gradient-based layout objective function, which allows more effective accounting for occlusions in complex layouts. All modules are jointly trained and help each other to achieve the best performance. Experiments and ablation studies based on ZInD~\cite{cruz2021zillow} dataset illustrate that iBARLE has state-of-the-art performance compared with other layout estimation baselines.
LASER: LAtent SpacE Rendering for 2D Visual Localization
Apr 01, 2022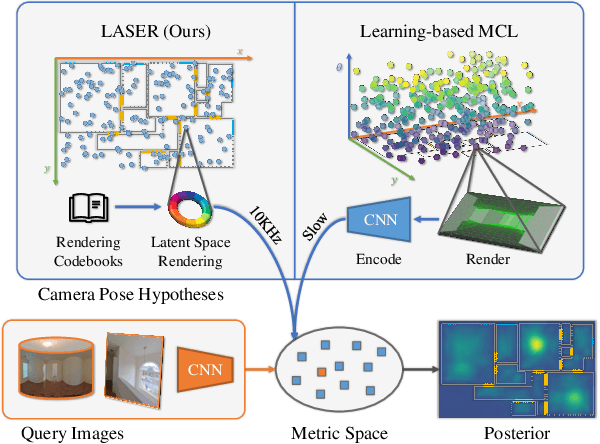
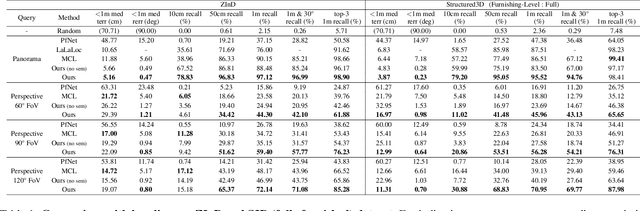
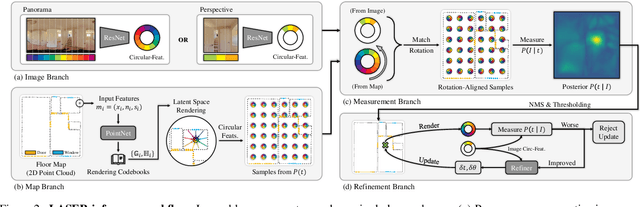
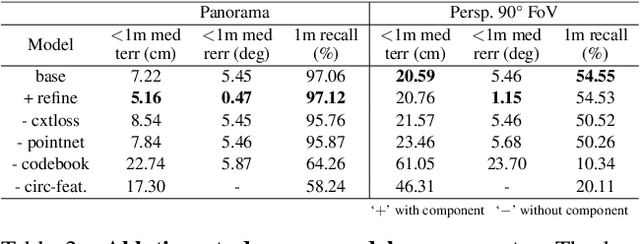
We present LASER, an image-based Monte Carlo Localization (MCL) framework for 2D floor maps. LASER introduces the concept of latent space rendering, where 2D pose hypotheses on the floor map are directly rendered into a geometrically-structured latent space by aggregating viewing ray features. Through a tightly coupled rendering codebook scheme, the viewing ray features are dynamically determined at rendering-time based on their geometries (i.e. length, incident-angle), endowing our representation with view-dependent fine-grain variability. Our codebook scheme effectively disentangles feature encoding from rendering, allowing the latent space rendering to run at speeds above 10KHz. Moreover, through metric learning, our geometrically-structured latent space is common to both pose hypotheses and query images with arbitrary field of views. As a result, LASER achieves state-of-the-art performance on large-scale indoor localization datasets (i.e. ZInD and Structured3D) for both panorama and perspective image queries, while significantly outperforming existing learning-based methods in speed.
Predicting Ground-Level Scene Layout from Aerial Imagery
Dec 08, 2016


We introduce a novel strategy for learning to extract semantically meaningful features from aerial imagery. Instead of manually labeling the aerial imagery, we propose to predict (noisy) semantic features automatically extracted from co-located ground imagery. Our network architecture takes an aerial image as input, extracts features using a convolutional neural network, and then applies an adaptive transformation to map these features into the ground-level perspective. We use an end-to-end learning approach to minimize the difference between the semantic segmentation extracted directly from the ground image and the semantic segmentation predicted solely based on the aerial image. We show that a model learned using this strategy, with no additional training, is already capable of rough semantic labeling of aerial imagery. Furthermore, we demonstrate that by finetuning this model we can achieve more accurate semantic segmentation than two baseline initialization strategies. We use our network to address the task of estimating the geolocation and geoorientation of a ground image. Finally, we show how features extracted from an aerial image can be used to hallucinate a plausible ground-level panorama.