 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Multi-Event Temporal Grounding in Long-Form Video
Jun 13, 2026Multimodal large language models have made rapid progress in video temporal grounding, yet real-world applications routinely require localizing every event that satisfies compositional temporal and spatial conditions. Existing benchmarks fall short: they localize only a single moment per query, count without temporal conditions, or treat grounding and counting as disjoint tasks. We introduce CoMET-Bench for Conditional Multi-Event Temporal Grounding in long-form video, comprising 2789 queries over 600 videos averaging 33.8 minutes across five real-world domains, with each query composed from 4 temporal conditions, 3 spatial conditions, and a dedicated negative-query subset. We further propose a unified evaluation protocol jointly measuring counting, grounding, and negative-query recognition, including a new Rejection-F1 metric that prevents trivial gaming by lazy "always-empty" models. Benchmarking a broad suite of MLLMs, agent-based, and grounding-specialized methods reveals that existing approaches remain far from solving this task. Building on these findings, we propose CoMET-Agent, a training-free agentic framework that reformulates the task as structured search-and-aggregate, improving F1@0.5 by 6.1% over GPT-5 purely through structural reasoning. Failure analysis further surfaces three open directions: fine-grained entity tracking, position-uniform retrieval, and causal event pairing.
Latent Bridge: Feature Delta Prediction for Efficient Dual-System Vision-Language-Action Model Inference
May 04, 2026Dual-system Vision-Language-Action (VLA) models achieve state-of-the-art robotic manipulation but are bottlenecked by the VLM backbone, which must execute at every control step while producing temporally redundant features. We propose Latent Bridge, a lightweight model that predicts VLM output deltas between timesteps, enabling the action head to operate on predicted outputs while the expensive VLM backbone is called only periodically. We instantiate Latent Bridge on two architecturally distinct VLAs: GR00T-N1.6 (feature-space bridge) and π0.5 (KV-cache bridge), demonstrating that the approach generalizes across VLA designs. Our task-agnostic DAgger training pipeline transfers across benchmarks without modification. Across four LIBERO suites, 24 RoboCasa kitchen tasks, and the ALOHA sim transfer-cube task, Latent Bridge achieves 95-100% performance retention while reducing VLM calls by 50-75%, yielding 1.65-1.73x net per-episode speedup.
Evaluation of Winning Solutions of 2025 Low Power Computer Vision Challenge
Apr 22, 2026The IEEE Low-Power Computer Vision Challenge (LPCVC) aims to promote the development of efficient vision models for edge devices, balancing accuracy with constraints such as latency, memory capacity, and energy use. The 2025 challenge featured three tracks: (1) Image classification under various lighting conditions and styles, (2) Open-Vocabulary Segmentation with Text Prompt, and (3) Monocular Depth Estimation. This paper presents the design of LPCVC 2025, including its competition structure and evaluation framework, which integrates the Qualcomm AI Hub for consistent and reproducible benchmarking. The paper also introduces the top-performing solutions from each track and outlines key trends and observations. The paper concludes with suggestions for future computer vision competitions.
ForeSea: AI Forensic Search with Multi-modal Queries for Video Surveillance
Mar 24, 2026Despite decades of work, surveillance still struggles to find specific targets across long, multi-camera video. Prior methods -- tracking pipelines, CLIP based models, and VideoRAG -- require heavy manual filtering, capture only shallow attributes, and fail at temporal reasoning. Real-world searches are inherently multimodal (e.g., "When does this person join the fight?" with the person's image), yet this setting remains underexplored. Also, there are no proper benchmarks to evaluate those setting - asking video with multimodal queries. To address this gap, we introduce ForeSeaQA, a new benchmark specifically designed for video QA with image-and-text queries and timestamped annotations of key events. The dataset consists of long-horizon surveillance footage paired with diverse multimodal questions, enabling systematic evaluation of retrieval, temporal grounding, and multimodal reasoning in realistic forensic conditions. Not limited to this benchmark, we propose ForeSea, an AI forensic search system with a 3-stage, plug-and-play pipeline. (1) A tracking module filters irrelevant footage; (2) a multimodal embedding module indexes the remaining clips; and (3) during inference, the system retrieves top-K candidate clips for a Video Large Language Model (VideoLLM) to answer queries and localize events. On ForeSeaQA, ForeSea improves accuracy by 3.5% and temporal IoU by 11.0 over prior VideoRAG models. To our knowledge, ForeSeaQA is the first benchmark to support complex multimodal queries with precise temporal grounding, and ForeSea is the first VideoRAG system built to excel in this setting.
DiSa: Saliency-Aware Foreground-Background Disentangled Framework for Open-Vocabulary Semantic Segmentation
Jan 27, 2026Open-vocabulary semantic segmentation aims to assign labels to every pixel in an image based on text labels. Existing approaches typically utilize vision-language models (VLMs), such as CLIP, for dense prediction. However, VLMs, pre-trained on image-text pairs, are biased toward salient, object-centric regions and exhibit two critical limitations when adapted to segmentation: (i) Foreground Bias, which tends to ignore background regions, and (ii) Limited Spatial Localization, resulting in blurred object boundaries. To address these limitations, we introduce DiSa, a novel saliency-aware foreground-background disentangled framework. By explicitly incorporating saliency cues in our designed Saliency-aware Disentanglement Module (SDM), DiSa separately models foreground and background ensemble features in a divide-and-conquer manner. Additionally, we propose a Hierarchical Refinement Module (HRM) that leverages pixel-wise spatial contexts and enables channel-wise feature refinement through multi-level updates. Extensive experiments on six benchmarks demonstrate that DiSa consistently outperforms state-of-the-art methods.
VLMs Guided Interpretable Decision Making for Autonomous Driving
Nov 17, 2025



Recent advancements in autonomous driving (AD) have explored the use of vision-language models (VLMs) within visual question answering (VQA) frameworks for direct driving decision-making. However, these approaches often depend on handcrafted prompts and suffer from inconsistent performance, limiting their robustness and generalization in real-world scenarios. In this work, we evaluate state-of-the-art open-source VLMs on high-level decision-making tasks using ego-view visual inputs and identify critical limitations in their ability to deliver reliable, context-aware decisions. Motivated by these observations, we propose a new approach that shifts the role of VLMs from direct decision generators to semantic enhancers. Specifically, we leverage their strong general scene understanding to enrich existing vision-based benchmarks with structured, linguistically rich scene descriptions. Building on this enriched representation, we introduce a multi-modal interactive architecture that fuses visual and linguistic features for more accurate decision-making and interpretable textual explanations. Furthermore, we design a post-hoc refinement module that utilizes VLMs to enhance prediction reliability. Extensive experiments on two autonomous driving benchmarks demonstrate that our approach achieves state-of-the-art performance, offering a promising direction for integrating VLMs into reliable and interpretable AD systems.
iBARLE: imBalance-Aware Room Layout Estimation
Aug 29, 2023



Room layout estimation predicts layouts from a single panorama. It requires datasets with large-scale and diverse room shapes to train the models. However, there are significant imbalances in real-world datasets including the dimensions of layout complexity, camera locations, and variation in scene appearance. These issues considerably influence the model training performance. In this work, we propose the imBalance-Aware Room Layout Estimation (iBARLE) framework to address these issues. iBARLE consists of (1) Appearance Variation Generation (AVG) module, which promotes visual appearance domain generalization, (2) Complex Structure Mix-up (CSMix) module, which enhances generalizability w.r.t. room structure, and (3) a gradient-based layout objective function, which allows more effective accounting for occlusions in complex layouts. All modules are jointly trained and help each other to achieve the best performance. Experiments and ablation studies based on ZInD~\cite{cruz2021zillow} dataset illustrate that iBARLE has state-of-the-art performance compared with other layout estimation baselines.
PSI: A Pedestrian Behavior Dataset for Socially Intelligent Autonomous Car
Dec 05, 2021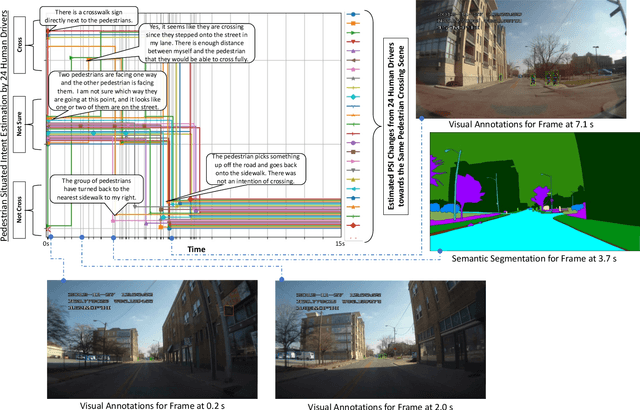
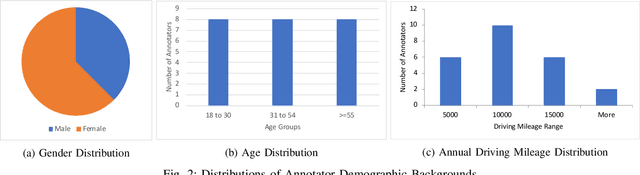


Prediction of pedestrian behavior is critical for fully autonomous vehicles to drive in busy city streets safely and efficiently. The future autonomous cars need to fit into mixed conditions with not only technical but also social capabilities. As more algorithms and datasets have been developed to predict pedestrian behaviors, these efforts lack the benchmark labels and the capability to estimate the temporal-dynamic intent changes of the pedestrians, provide explanations of the interaction scenes, and support algorithms with social intelligence. This paper proposes and shares another benchmark dataset called the IUPUI-CSRC Pedestrian Situated Intent (PSI) data with two innovative labels besides comprehensive computer vision labels. The first novel label is the dynamic intent changes for the pedestrians to cross in front of the ego-vehicle, achieved from 24 drivers with diverse backgrounds. The second one is the text-based explanations of the driver reasoning process when estimating pedestrian intents and predicting their behaviors during the interaction period. These innovative labels can enable several computer vision tasks, including pedestrian intent/behavior prediction, vehicle-pedestrian interaction segmentation, and video-to-language mapping for explainable algorithms. The released dataset can fundamentally improve the development of pedestrian behavior prediction models and develop socially intelligent autonomous cars to interact with pedestrians efficiently. The dataset has been evaluated with different tasks and is released to the public to access.
Towards Novel Target Discovery Through Open-Set Domain Adaptation
May 16, 2021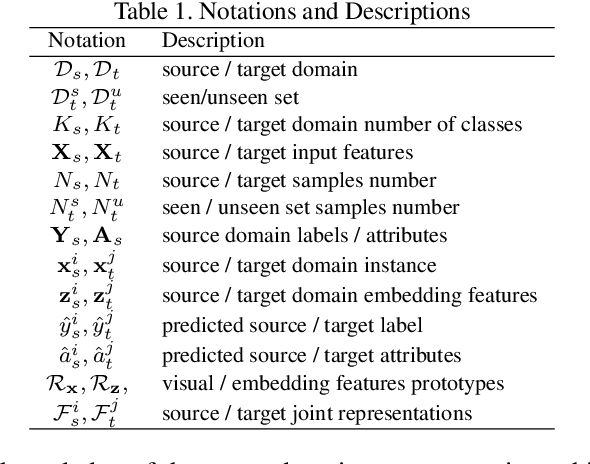
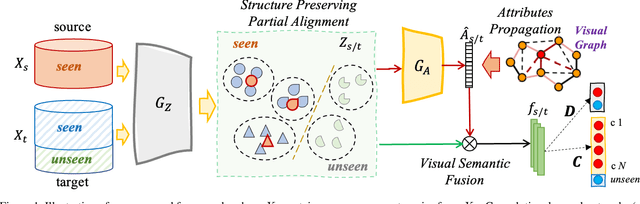
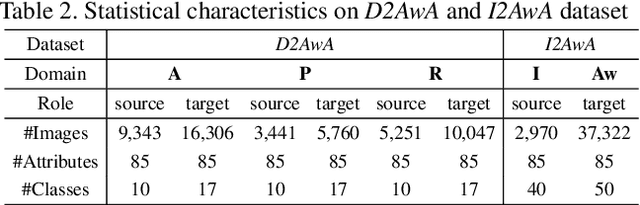
Open-set domain adaptation (OSDA) considers that the target domain contains samples from novel categories unobserved in external source domain. Unfortunately, existing OSDA methods always ignore the demand for the information of unseen categories and simply recognize them as "unknown" set without further explanation. This motivates us to understand the unknown categories more specifically by exploring the underlying structures and recovering their interpretable semantic attributes. In this paper, we propose a novel framework to accurately identify the seen categories in target domain, and effectively recover the semantic attributes for unseen categories. Specifically, structure preserving partial alignment is developed to recognize the seen categories through domain-invariant feature learning. Attribute propagation over visual graph is designed to smoothly transit attributes from seen to unseen categories via visual-semantic mapping. Moreover, two new cross-main benchmarks are constructed to evaluate the proposed framework in the novel and practical challenge. Experimental results on open-set recognition and semantic recovery demonstrate the superiority of the proposed method over other compared baselines.
Adversarial Dual Distinct Classifiers for Unsupervised Domain Adaptation
Aug 27, 2020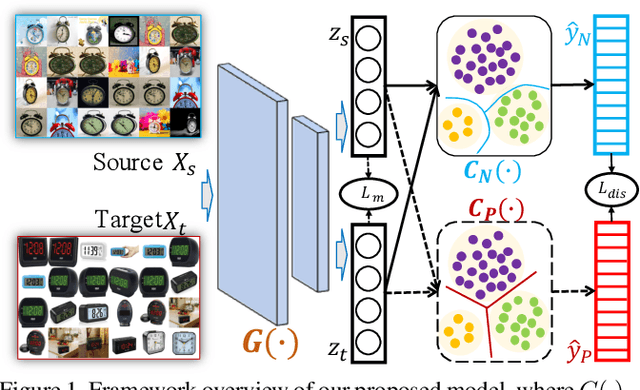
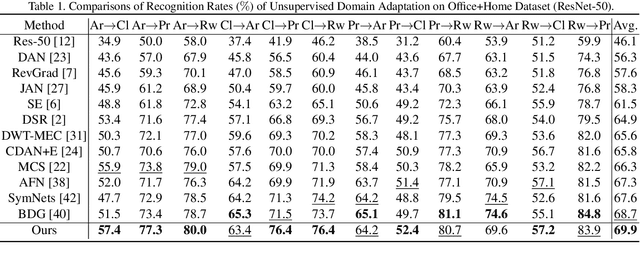
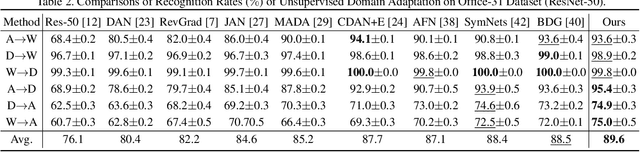
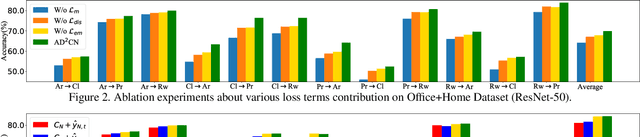
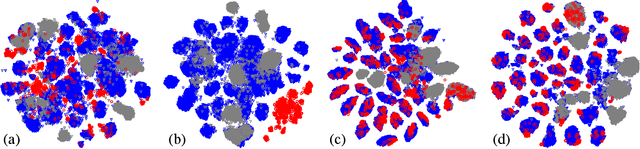
Unsupervised Domain adaptation (UDA) attempts to recognize the unlabeled target samples by building a learning model from a differently-distributed labeled source domain. Conventional UDA concentrates on extracting domain-invariant features through deep adversarial networks. However, most of them seek to match the different domain feature distributions, without considering the task-specific decision boundaries across various classes. In this paper, we propose a novel Adversarial Dual Distinct Classifiers Network (AD$^2$CN) to align the source and target domain data distribution simultaneously with matching task-specific category boundaries. To be specific, a domain-invariant feature generator is exploited to embed the source and target data into a latent common space with the guidance of discriminative cross-domain alignment. Moreover, we naturally design two different structure classifiers to identify the unlabeled target samples over the supervision of the labeled source domain data. Such dual distinct classifiers with various architectures can capture diverse knowledge of the target data structure from different perspectives. Extensive experimental results on several cross-domain visual benchmarks prove the model's effectiveness by comparing it with other state-of-the-art UDA.