 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinkedOut: Linking World Knowledge Representation Out of Video LLM for Next-Generation Video Recommendation
Dec 18, 2025Video Large Language Models (VLLMs) unlock world-knowledge-aware video understanding through pretraining on internet-scale data and have already shown promise on tasks such as movie analysis and video question answering. However, deploying VLLMs for downstream tasks such as video recommendation remains challenging, since real systems require multi-video inputs, lightweight backbones, low-latency sequential inference, and rapid response. In practice, (1) decode-only generation yields high latency for sequential inference, (2) typical interfaces do not support multi-video inputs, and (3) constraining outputs to language discards fine-grained visual details that matter for downstream vision tasks. We argue that these limitations stem from the absence of a representation that preserves pixel-level detail while leveraging world knowledge. We present LinkedOut, a representation that extracts VLLM world knowledge directly from video to enable fast inference, supports multi-video histories, and removes the language bottleneck. LinkedOut extracts semantically grounded, knowledge-aware tokens from raw frames using VLLMs, guided by promptable queries and optional auxiliary modalities. We introduce a cross-layer knowledge fusion MoE that selects the appropriate level of abstraction from the rich VLLM features, enabling personalized, interpretable, and low-latency recommendation. To our knowledge, LinkedOut is the first VLLM-based video recommendation method that operates on raw frames without handcrafted labels, achieving state-of-the-art results on standard benchmarks. Interpretability studies and ablations confirm the benefits of layer diversity and layer-wise fusion, pointing to a practical path that fully leverages VLLM world-knowledge priors and visual reasoning for downstream vision tasks such as recommendation.
iBARLE: imBalance-Aware Room Layout Estimation
Aug 29, 2023



Room layout estimation predicts layouts from a single panorama. It requires datasets with large-scale and diverse room shapes to train the models. However, there are significant imbalances in real-world datasets including the dimensions of layout complexity, camera locations, and variation in scene appearance. These issues considerably influence the model training performance. In this work, we propose the imBalance-Aware Room Layout Estimation (iBARLE) framework to address these issues. iBARLE consists of (1) Appearance Variation Generation (AVG) module, which promotes visual appearance domain generalization, (2) Complex Structure Mix-up (CSMix) module, which enhances generalizability w.r.t. room structure, and (3) a gradient-based layout objective function, which allows more effective accounting for occlusions in complex layouts. All modules are jointly trained and help each other to achieve the best performance. Experiments and ablation studies based on ZInD~\cite{cruz2021zillow} dataset illustrate that iBARLE has state-of-the-art performance compared with other layout estimation baselines.
Adaptive Trajectory Prediction via Transferable GNN
Mar 26, 2022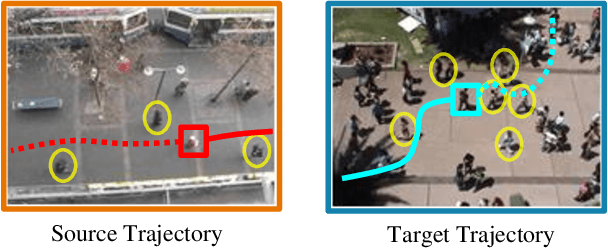



Pedestrian trajectory prediction is an essential component in a wide range of AI applications such as autonomous driving and robotics. Existing methods usually assume the training and testing motions follow the same pattern while ignoring the potential distribution differences (e.g., shopping mall and street). This issue results in inevitable performance decrease. To address this issue, we propose a novel Transferable Graph Neural Network (T-GNN) framework, which jointly conducts trajectory prediction as well as domain alignment in a unified framework. Specifically, a domain-invariant GNN is proposed to explore the structural motion knowledge where the domain-specific knowledge is reduced. Moreover, an attention-based adaptive knowledge learning module is further proposed to explore fine-grained individual-level feature representations for knowledge transfer. By this way, disparities across different trajectory domains will be better alleviated. More challenging while practical trajectory prediction experiments are designed, and the experimental results verify the superior performance of our proposed model. To the best of our knowledge, our work is the pioneer which fills the gap in benchmarks and techniques for practical pedestrian trajectory prediction across different domains.
Semi-supervised Domain Adaptive Structure Learning
Dec 12, 2021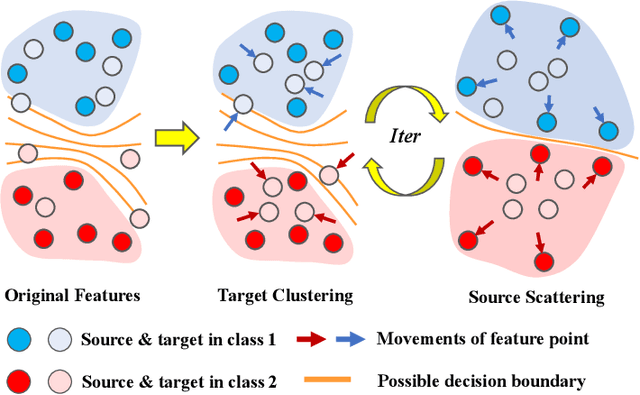
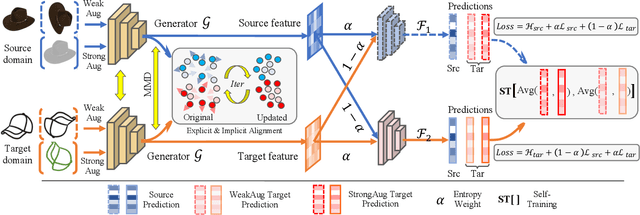
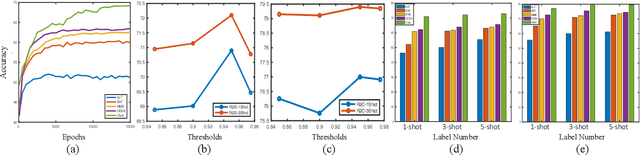

Semi-supervised domain adaptation (SSDA) is quite a challenging problem requiring methods to overcome both 1) overfitting towards poorly annotated data and 2) distribution shift across domains. Unfortunately, a simple combination of domain adaptation (DA) and semi-supervised learning (SSL) methods often fail to address such two objects because of training data bias towards labeled samples. In this paper, we introduce an adaptive structure learning method to regularize the cooperation of SSL and DA. Inspired by the multi-views learning, our proposed framework is composed of a shared feature encoder network and two classifier networks, trained for contradictory purposes. Among them, one of the classifiers is applied to group target features to improve intra-class density, enlarging the gap of categorical clusters for robust representation learning. Meanwhile, the other classifier, serviced as a regularizer, attempts to scatter the source features to enhance the smoothness of the decision boundary. The iterations of target clustering and source expansion make the target features being well-enclosed inside the dilated boundary of the corresponding source points. For the joint address of cross-domain features alignment and partially labeled data learning, we apply the maximum mean discrepancy (MMD) distance minimization and self-training (ST) to project the contradictory structures into a shared view to make the reliable final decision. The experimental results over the standard SSDA benchmarks, including DomainNet and Office-home, demonstrate both the accuracy and robustness of our method over the state-of-the-art approaches.
Sign Language Recognition via Skeleton-Aware Multi-Model Ensemble
Oct 12, 2021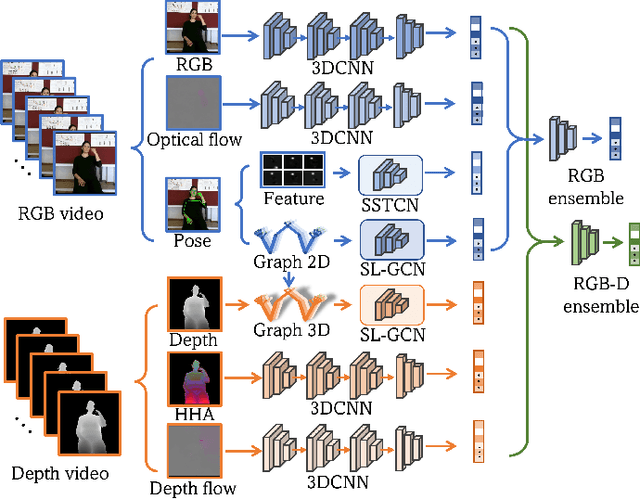
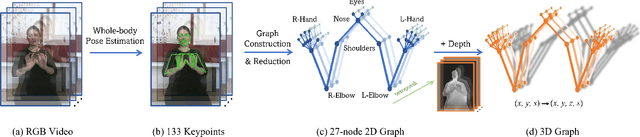
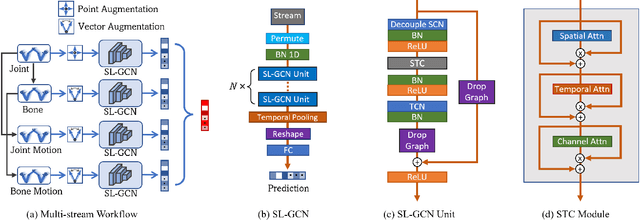
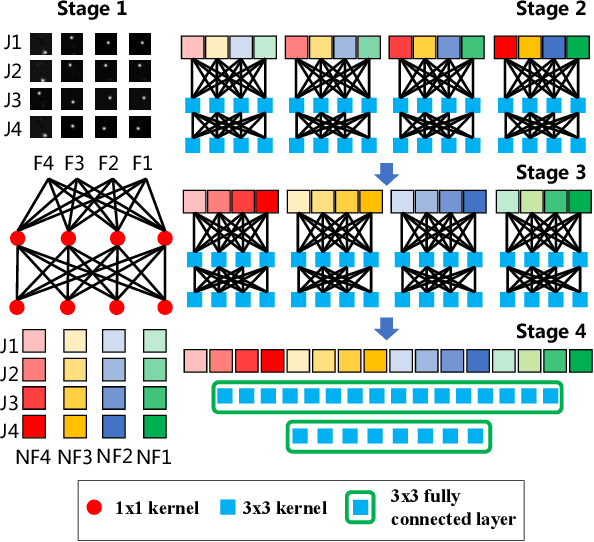
Sign language is commonly used by deaf or mute people to communicate but requires extensive effort to master. It is usually performed with the fast yet delicate movement of hand gestures, body posture, and even facial expressions. Current Sign Language Recognition (SLR) methods usually extract features via deep neural networks and suffer overfitting due to limited and noisy data. Recently, skeleton-based action recognition has attracted increasing attention due to its subject-invariant and background-invariant nature, whereas skeleton-based SLR is still under exploration due to the lack of hand annotations. Some researchers have tried to use off-line hand pose trackers to obtain hand keypoints and aid in recognizing sign language via recurrent neural networks. Nevertheless, none of them outperforms RGB-based approaches yet. To this end, we propose a novel Skeleton Aware Multi-modal Framework with a Global Ensemble Model (GEM) for isolated SLR (SAM-SLR-v2) to learn and fuse multi-modal feature representations towards a higher recognition rate. Specifically, we propose a Sign Language Graph Convolution Network (SL-GCN) to model the embedded dynamics of skeleton keypoints and a Separable Spatial-Temporal Convolution Network (SSTCN) to exploit skeleton features. The skeleton-based predictions are fused with other RGB and depth based modalities by the proposed late-fusion GEM to provide global information and make a faithful SLR prediction. Experiments on three isolated SLR datasets demonstrate that our proposed SAM-SLR-v2 framework is exceedingly effective and achieves state-of-the-art performance with significant margins. Our code will be available at https://github.com/jackyjsy/SAM-SLR-v2
Skeleton Aware Multi-modal Sign Language Recognition
Mar 26, 2021
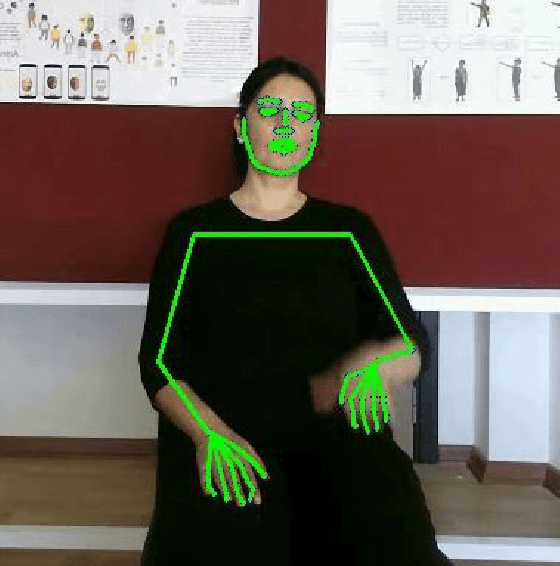
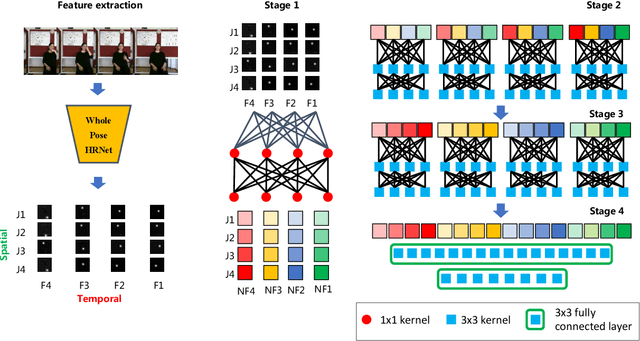
Sign language is used by deaf or speech impaired people to communicate and requires great effort to master. Sign Language Recognition (SLR) aims to bridge between sign language users and others by recognizing words from given videos. It is an important yet challenging task since sign language is performed with fast and complex movement of hand gestures, body posture, and even facial expressions. Recently, skeleton-based action recognition attracts increasing attention due to the independence on subject and background variation. Furthermore, it can be a strong complement to RGB/D modalities to boost the overall recognition rate. However, skeleton-based SLR is still under exploration due to the lack of annotations on hand keypoints. Some efforts have been made to use hand detectors with pose estimators to extract hand key points and learn to recognize sign language via a Recurrent Neural Network, but none of them outperforms RGB-based methods. To this end, we propose a novel Skeleton Aware Multi-modal SLR framework (SAM-SLR) to further improve the recognition rate. Specifically, we propose a Sign Language Graph Convolution Network (SL-GCN) to model the embedded dynamics and propose a novel Separable Spatial-Temporal Convolution Network (SSTCN) to exploit skeleton features. Our skeleton-based method achieves a higher recognition rate compared with all other single modalities. Moreover, our proposed SAM-SLR framework can further enhance the performance by assembling our skeleton-based method with other RGB and depth modalities. As a result, SAM-SLR achieves the highest performance in both RGB (98.42%) and RGB-D (98.53%) tracks in 2021 Looking at People Large Scale Signer Independent Isolated SLR Challenge. Our code is available at https://github.com/jackyjsy/CVPR21Chal-SLR
I3DOL: Incremental 3D Object Learning without Catastrophic Forgetting
Dec 16, 2020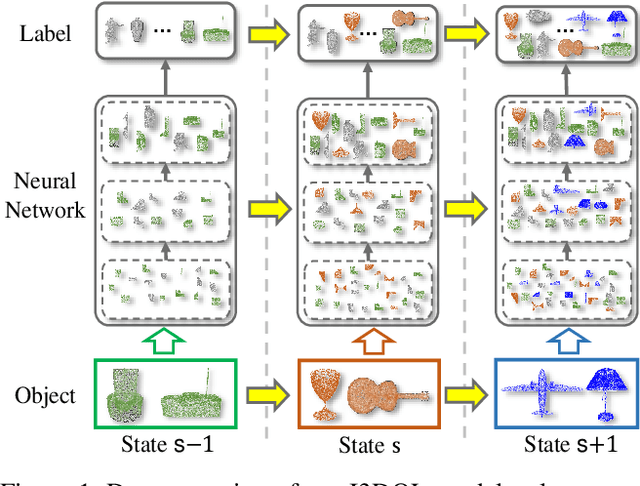
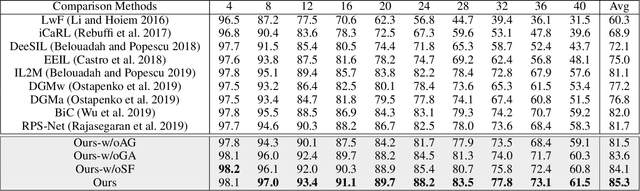
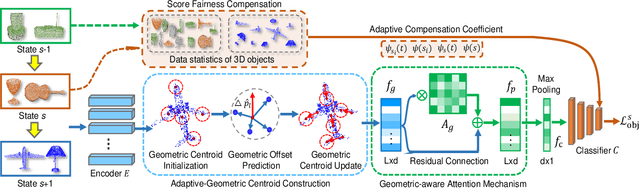

3D object classification has attracted appealing attentions in academic researches and industrial applications. However, most existing methods need to access the training data of past 3D object classes when facing the common real-world scenario: new classes of 3D objects arrive in a sequence. Moreover, the performance of advanced approaches degrades dramatically for past learned classes (i.e., catastrophic forgetting), due to the irregular and redundant geometric structures of 3D point cloud data. To address these challenges, we propose a new Incremental 3D Object Learning (i.e., I3DOL) model, which is the first exploration to learn new classes of 3D object continually. Specifically, an adaptive-geometric centroid module is designed to construct discriminative local geometric structures, which can better characterize the irregular point cloud representation for 3D object. Afterwards, to prevent the catastrophic forgetting brought by redundant geometric information, a geometric-aware attention mechanism is developed to quantify the contributions of local geometric structures, and explore unique 3D geometric characteristics with high contributions for classes incremental learning. Meanwhile, a score fairness compensation strategy is proposed to further alleviate the catastrophic forgetting caused by unbalanced data between past and new classes of 3D object, by compensating biased prediction for new classes in the validation phase. Experiments on 3D representative datasets validate the superiority of our I3DOL framework.
Job2Vec: Job Title Benchmarking with Collective Multi-View Representation Learning
Sep 16, 2020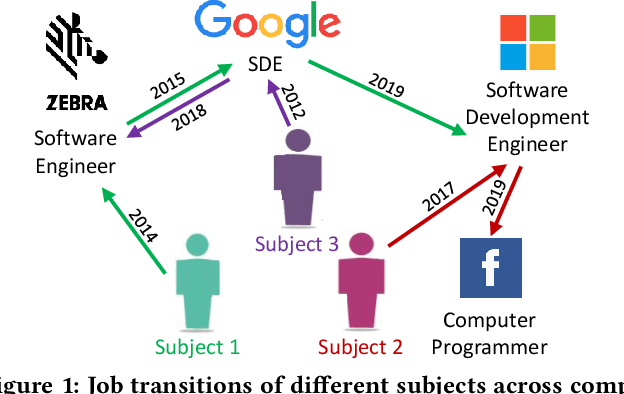

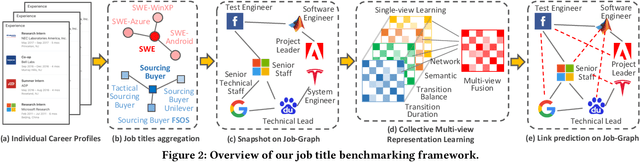
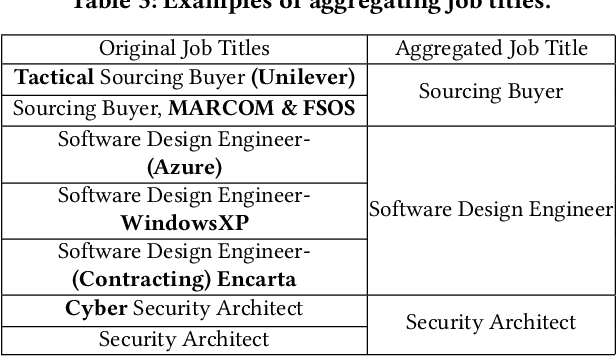
Job Title Benchmarking (JTB) aims at matching job titles with similar expertise levels across various companies. JTB could provide precise guidance and considerable convenience for both talent recruitment and job seekers for position and salary calibration/prediction. Traditional JTB approaches mainly rely on manual market surveys, which is expensive and labor-intensive. Recently, the rapid development of Online Professional Graph has accumulated a large number of talent career records, which provides a promising trend for data-driven solutions. However, it is still a challenging task since (1) the job title and job transition (job-hopping) data is messy which contains a lot of subjective and non-standard naming conventions for the same position (e.g., Programmer, Software Development Engineer, SDE, Implementation Engineer), (2) there is a large amount of missing title/transition information, and (3) one talent only seeks limited numbers of jobs which brings the incompleteness and randomness modeling job transition patterns. To overcome these challenges, we aggregate all the records to construct a large-scale Job Title Benchmarking Graph (Job-Graph), where nodes denote job titles affiliated with specific companies and links denote the correlations between jobs. We reformulate the JTB as the task of link prediction over the Job-Graph that matched job titles should have links. Along this line, we propose a collective multi-view representation learning method (Job2Vec) by examining the Job-Graph jointly in (1) graph topology view, (2)semantic view, (3) job transition balance view, and (4) job transition duration view. We fuse the multi-view representations in the encode-decode paradigm to obtain a unified optimal representation for the task of link prediction. Finally, we conduct extensive experiments to validate the effectiveness of our proposed method.
Collaborative Attention Mechanism for Multi-View Action Recognition
Sep 14, 2020

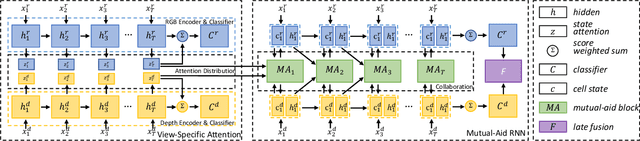

Multi-view action recognition (MVAR) leverages complementary temporal information from different views to enhance the learning process. Attention is an effective mechanism which has been extensively adopted for modeling temporal data. However, most existing MVAR methods only utilize attention to extract view-specific patterns. They ignore the potential to dig latent mutual-support information inattention space. To fully take the advantage of the multi-view cooperation, we propose a collaborative attention mechanism (CAM). It detects the attention differences among multi-view inputs, and adaptively integrates complementary frame-level information to benefit each other. Specifically, we utilize recurrent neural network (RNN) by expanding long short-term memory (LSTM) as a Mutual-Aid RNN (MAR). CAM takes advantages of view-specific attention pattern to guide another view and unlock potential information which is hard to explore by itself. Extensive experiments on three action datasets illustrate our CAM achieves better result for each single view, and also boosts the multi-view performance.
Opposite Structure Learning for Semi-supervised Domain Adaptation
Feb 06, 2020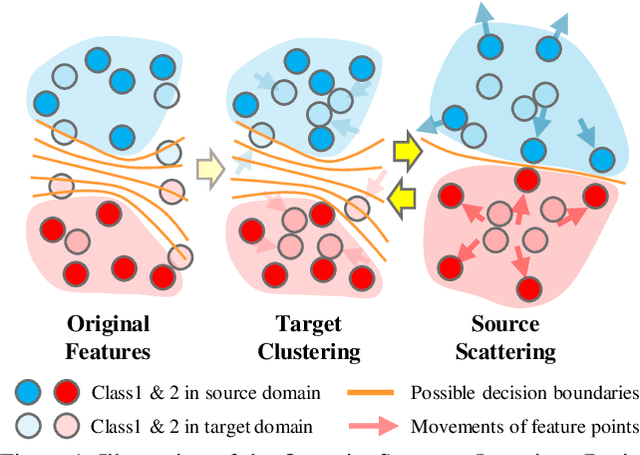

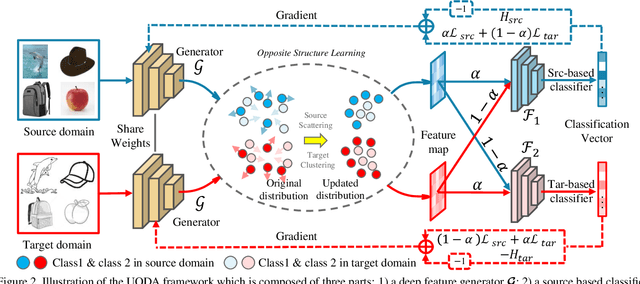

Current adversarial adaptation methods attempt to align the cross-domain features whereas two challenges remain unsolved: 1) conditional distribution mismatch between different domains and 2) the bias of decision boundary towards the source domain. To solve these challenges, we propose a novel framework for semi-supervised domain adaptation by unifying the learning of opposite structures (UODA). UODA consists of a generator and two classifiers (i.e., the source-based and the target-based classifiers respectively) which are trained with opposite forms of losses for a unified object. The target-based classifier attempts to cluster the target features to improve intra-class density and enlarge inter-class divergence. Meanwhile, the source-based classifier is designed to scatter the source features to enhance the smoothness of decision boundary. Through the alternation of source-feature expansion and target-feature clustering procedures, the target features are well-enclosed within the dilated boundary of the corresponding source features. This strategy effectively makes the cross-domain features precisely aligned. To overcome the model collapse through training, we progressively update the measurement of distance and the feature representation on both domains via an adversarial training paradigm. Extensive experiments on the benchmarks of DomainNet and Office-home datasets demonstrate the effectiveness of our approach over the state-of-the-art method.