 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Attention Mechanism for Multi-View Action Recognition
Paper and Code
Sep 14, 2020

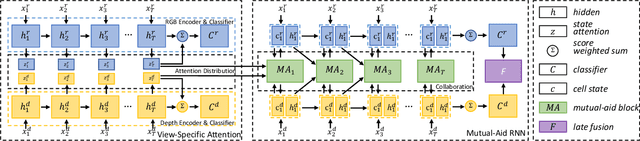

Multi-view action recognition (MVAR) leverages complementary temporal information from different views to enhance the learning process. Attention is an effective mechanism which has been extensively adopted for modeling temporal data. However, most existing MVAR methods only utilize attention to extract view-specific patterns. They ignore the potential to dig latent mutual-support information inattention space. To fully take the advantage of the multi-view cooperation, we propose a collaborative attention mechanism (CAM). It detects the attention differences among multi-view inputs, and adaptively integrates complementary frame-level information to benefit each other. Specifically, we utilize recurrent neural network (RNN) by expanding long short-term memory (LSTM) as a Mutual-Aid RNN (MAR). CAM takes advantages of view-specific attention pattern to guide another view and unlock potential information which is hard to explore by itself. Extensive experiments on three action datasets illustrate our CAM achieves better result for each single view, and also boosts the multi-view performance.