 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapidly deploying on-device eye tracking by distilling visual foundation models
Apr 02, 2026Eye tracking (ET) plays a critical role in augmented and virtual reality applications. However, rapidly deploying high-accuracy, on-device gaze estimation for new products remains challenging because hardware configurations (e.g., camera placement, camera pose, and illumination) often change across device generations. Visual foundation models (VFMs) are a promising direction for rapid training and deployment, and they excel on natural-image benchmarks; yet we find that off-the-shelf VFMs still struggle to achieve high accuracy on specialized near-eye infrared imagery. To address this gap, we introduce DistillGaze, a framework that distills a foundation model by leveraging labeled synthetic data and unlabeled real data for rapid and high-performance on-device gaze estimation. DistillGaze proceeds in two stages. First, we adapt a VFM into a domain-specialized teacher using self-supervised learning on labeled synthetic and unlabeled real images. Synthetic data provides scalable, high-quality gaze supervision, while unlabeled real data helps bridge the synthetic-to-real domain gap. Second, we train an on-device student using both teacher guidance and self-training. Evaluated on a large-scale, crowd-sourced dataset spanning over 2,000 participants, DistillGaze reduces median gaze error by 58.62% relative to synthetic-only baselines while maintaining a lightweight 256K-parameter model suitable for real-time on-device deployment. Overall, DistillGaze provides an efficient pathway for training and deploying ET models that adapt to hardware changes, and offers a recipe for combining synthetic supervision with unlabeled real data in on-device regression tasks.
What Will Your Child Look Like? DNA-Net: Age and Gender Aware Kin Face Synthesizer
Nov 16, 2019
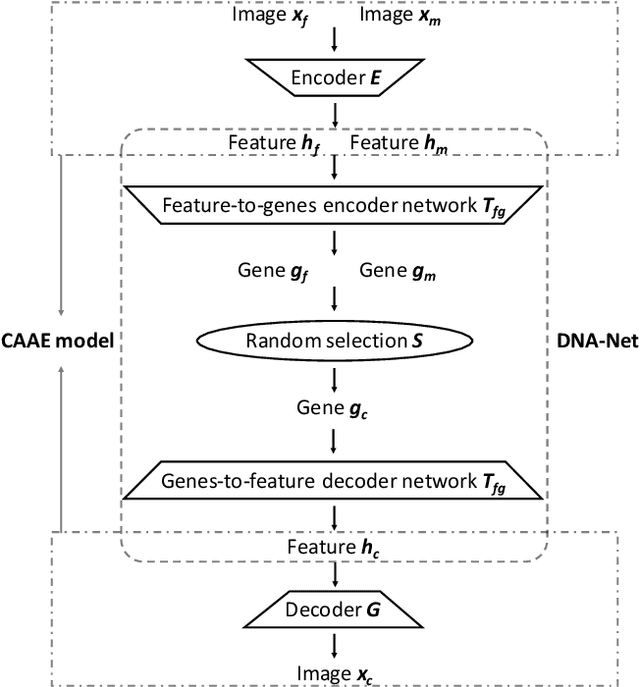
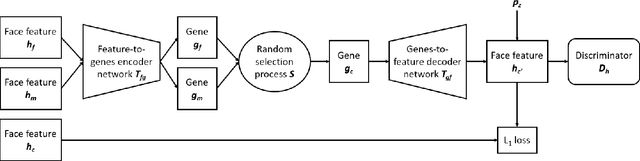

Visual kinship recognition aims to identify blood relatives from facial images. Its practical application-- like in law-enforcement, video surveillance, automatic family album management, and more-- has motivated many researchers to put forth effort on the topic as of recent. In this paper, we focus on a new view of visual kinship technology: kin-based face generation. Specifically, we propose a two-stage kin-face generation model to predict the appearance of a child given a pair of parents. The first stage includes a deep generative adversarial autoencoder conditioned on ages and genders to map between facial appearance and high-level features. The second stage is our proposed DNA-Net, which serves as a transformation between the deep and genetic features based on a random selection process to fuse genes of a parent pair to form the genes of a child. We demonstrate the effectiveness of the proposed method quantitatively and qualitatively: quantitatively, pre-trained models and human subjects perform kinship verification on the generated images of children; qualitatively, we show photo-realistic face images of children that closely resemble the given pair of parents. In the end, experiments validate that the proposed model synthesizes convincing kin-faces using both subjective and objective standards.
EV-Action: Electromyography-Vision Multi-Modal Action Dataset
Apr 20, 2019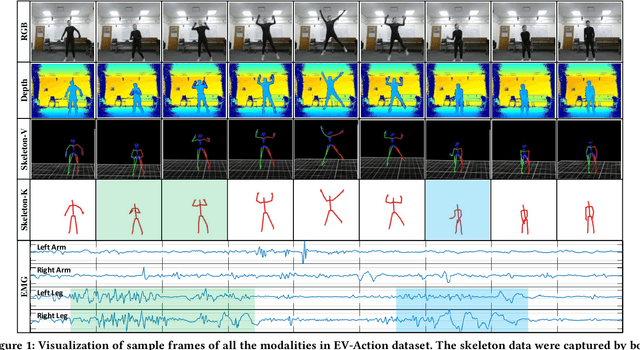

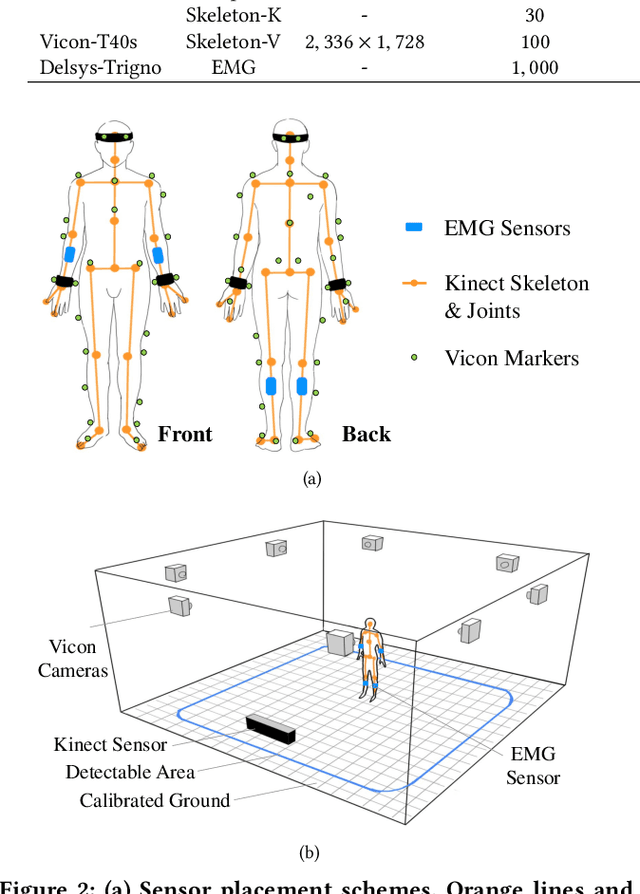
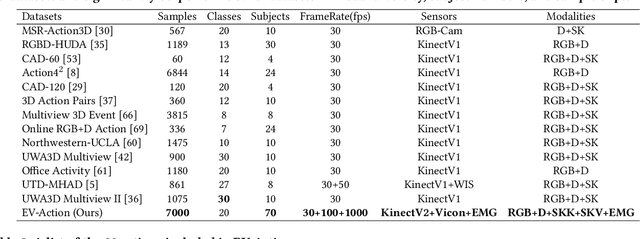
Multi-modal human motion analysis is a critical and attractive research topic. Most existing multi-modal action datasets only provide visual modalities such as RGB, depth, or low quality skeleton data. In this paper, we introduce a new, large-scale dataset named EV-Action dataset. It consists RGB, depth, electromyography (EMG), and two skeleton modalities. Compared with others, our dataset has two major improvements: (1) we deploy a motion capturing system to obtain high quality skeleton modality, which provides more comprehensive motion information including skeleton, trajectory, and acceleration with higher accuracy, sample frequency, and more skeleton markers. (2) we include an EMG modality. While EMG is used as an effective indicator for biomechanics area, it has yet to be well explored in multimedia, computer vision, and machine learning areas. To the best of our knowledge, this is the first action dataset with EMG modality. In this paper, we introduce the details of EV-Action dataset. A simple yet effective framework for EMG-based action recognition is proposed. Moreover, we provide state-of-the-art baselines for each modality. The approaches achieve considerable improvements when EMG is involved, and it demonstrates the effectiveness of EMG modality in human action analysis tasks. We hope this dataset could make significant contributions to signal processing, multimedia, computer vision, machine learning, biomechanics, and other interdisciplinary fields.