 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicID: Flexible ID Fidelity Generation System
Aug 20, 2024
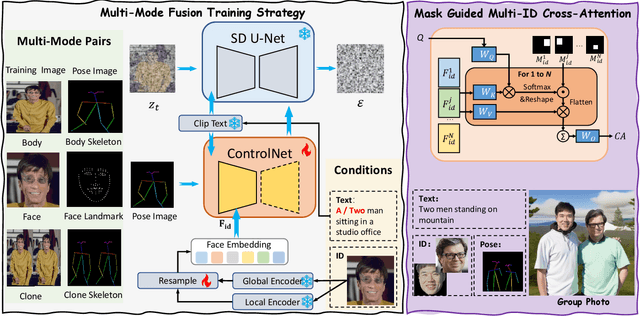


Portrait Fidelity Generation is a prominent research area in generative models, with a primary focus on enhancing both controllability and fidelity. Current methods face challenges in generating high-fidelity portrait results when faces occupy a small portion of the image with a low resolution, especially in multi-person group photo settings. To tackle these issues, we propose a systematic solution called MagicID, based on a self-constructed million-level multi-modal dataset named IDZoom. MagicID consists of Multi-Mode Fusion training strategy (MMF) and DDIM Inversion based ID Restoration inference framework (DIIR). During training, MMF iteratively uses the skeleton and landmark modalities from IDZoom as conditional guidance. By introducing the Clone Face Tuning in training stage and Mask Guided Multi-ID Cross Attention (MGMICA) in inference stage, explicit constraints on face positional features are achieved for multi-ID group photo generation. The DIIR aims to address the issue of artifacts. The DDIM Inversion is used in conjunction with face landmarks, global and local face features to achieve face restoration while keeping the background unchanged. Additionally, DIIR is plug-and-play and can be applied to any diffusion-based portrait generation method. To validate the effectiveness of MagicID, we conducted extensive comparative and ablation experiments. The experimental results demonstrate that MagicID has significant advantages in both subjective and objective metrics, and achieves controllable generation in multi-person scenarios.
What Will Your Child Look Like? DNA-Net: Age and Gender Aware Kin Face Synthesizer
Nov 16, 2019
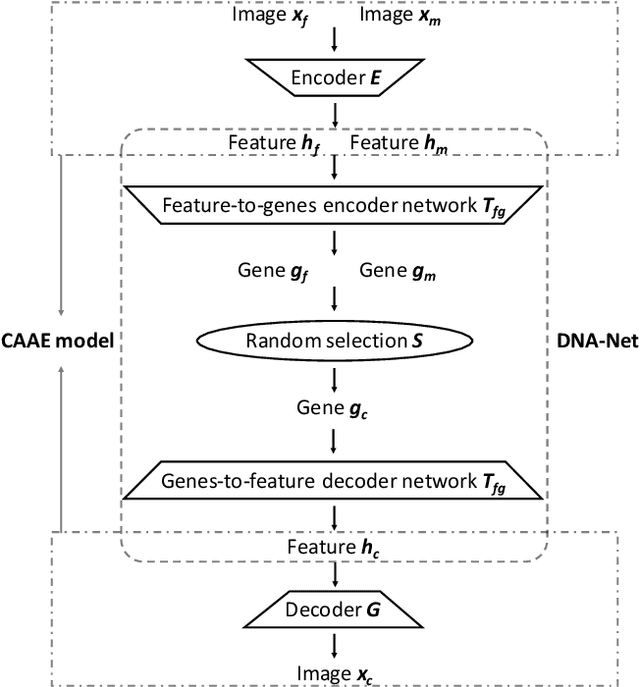
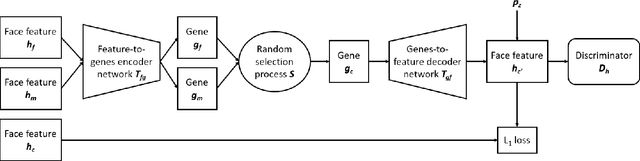

Visual kinship recognition aims to identify blood relatives from facial images. Its practical application-- like in law-enforcement, video surveillance, automatic family album management, and more-- has motivated many researchers to put forth effort on the topic as of recent. In this paper, we focus on a new view of visual kinship technology: kin-based face generation. Specifically, we propose a two-stage kin-face generation model to predict the appearance of a child given a pair of parents. The first stage includes a deep generative adversarial autoencoder conditioned on ages and genders to map between facial appearance and high-level features. The second stage is our proposed DNA-Net, which serves as a transformation between the deep and genetic features based on a random selection process to fuse genes of a parent pair to form the genes of a child. We demonstrate the effectiveness of the proposed method quantitatively and qualitatively: quantitatively, pre-trained models and human subjects perform kinship verification on the generated images of children; qualitatively, we show photo-realistic face images of children that closely resemble the given pair of parents. In the end, experiments validate that the proposed model synthesizes convincing kin-faces using both subjective and objective standards.