 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicStyle: Portrait Stylization Based on Reference Image
Sep 12, 2024



The development of diffusion models has significantly advanced the research on image stylization, particularly in the area of stylizing a content image based on a given style image, which has attracted many scholars. The main challenge in this reference image stylization task lies in how to maintain the details of the content image while incorporating the color and texture features of the style image. This challenge becomes even more pronounced when the content image is a portrait which has complex textural details. To address this challenge, we propose a diffusion model-based reference image stylization method specifically for portraits, called MagicStyle. MagicStyle consists of two phases: Content and Style DDIM Inversion (CSDI) and Feature Fusion Forward (FFF). The CSDI phase involves a reverse denoising process, where DDIM Inversion is performed separately on the content image and the style image, storing the self-attention query, key and value features of both images during the inversion process. The FFF phase executes forward denoising, harmoniously integrating the texture and color information from the pre-stored feature queries, keys and values into the diffusion generation process based on our Well-designed Feature Fusion Attention (FFA). We conducted comprehensive comparative and ablation experiments to validate the effectiveness of our proposed MagicStyle and FFA.
MagicID: Flexible ID Fidelity Generation System
Aug 20, 2024
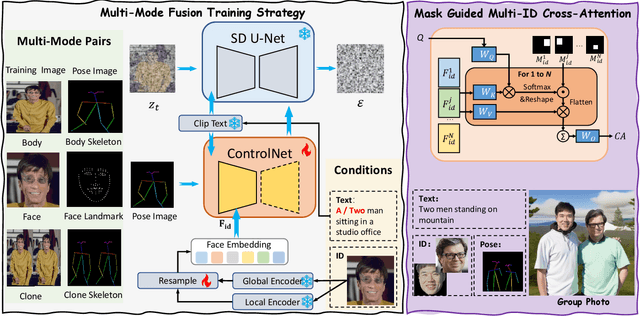


Portrait Fidelity Generation is a prominent research area in generative models, with a primary focus on enhancing both controllability and fidelity. Current methods face challenges in generating high-fidelity portrait results when faces occupy a small portion of the image with a low resolution, especially in multi-person group photo settings. To tackle these issues, we propose a systematic solution called MagicID, based on a self-constructed million-level multi-modal dataset named IDZoom. MagicID consists of Multi-Mode Fusion training strategy (MMF) and DDIM Inversion based ID Restoration inference framework (DIIR). During training, MMF iteratively uses the skeleton and landmark modalities from IDZoom as conditional guidance. By introducing the Clone Face Tuning in training stage and Mask Guided Multi-ID Cross Attention (MGMICA) in inference stage, explicit constraints on face positional features are achieved for multi-ID group photo generation. The DIIR aims to address the issue of artifacts. The DDIM Inversion is used in conjunction with face landmarks, global and local face features to achieve face restoration while keeping the background unchanged. Additionally, DIIR is plug-and-play and can be applied to any diffusion-based portrait generation method. To validate the effectiveness of MagicID, we conducted extensive comparative and ablation experiments. The experimental results demonstrate that MagicID has significant advantages in both subjective and objective metrics, and achieves controllable generation in multi-person scenarios.
RepControlNet: ControlNet Reparameterization
Aug 17, 2024



With the wide application of diffusion model, the high cost of inference resources has became an important bottleneck for its universal application. Controllable generation, such as ControlNet, is one of the key research directions of diffusion model, and the research related to inference acceleration and model compression is more important. In order to solve this problem, this paper proposes a modal reparameterization method, RepControlNet, to realize the controllable generation of diffusion models without increasing computation. In the training process, RepControlNet uses the adapter to modulate the modal information into the feature space, copy the CNN and MLP learnable layers of the original diffusion model as the modal network, and initialize these weights based on the original weights and coefficients. The training process only optimizes the parameters of the modal network. In the inference process, the weights of the neutralization original diffusion model in the modal network are reparameterized, which can be compared with or even surpass the methods such as ControlNet, which use additional parameters and computational quantities, without increasing the number of parameters. We have carried out a large number of experiments on both SD1.5 and SDXL, and the experimental results show the effectiveness and efficiency of the proposed RepControlNet.