 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMFDFormer: Transformer-based Copy-Move Forgery Detection with Continual Learning
Nov 22, 2023Copy-move forgery detection aims at detecting duplicated regions in a suspected forged image, and deep learning based copy-move forgery detection methods are in the ascendant. These deep learning based methods heavily rely on synthetic training data, and the performance will degrade when facing new tasks. In this paper, we propose a Transformer-style copy-move forgery detection network named as CMFDFormer, and provide a novel PCSD (Pooled Cube and Strip Distillation) continual learning framework to help CMFDFormer handle new tasks. CMFDFormer consists of a MiT (Mix Transformer) backbone network and a PHD (Pluggable Hybrid Decoder) mask prediction network. The MiT backbone network is a Transformer-style network which is adopted on the basis of comprehensive analyses with CNN-style and MLP-style backbones. The PHD network is constructed based on self-correlation computation, hierarchical feature integration, a multi-scale cycle fully-connected block and a mask reconstruction block. The PHD network is applicable to feature extractors of different styles for hierarchical multi-scale information extraction, achieving comparable performance. Last but not least, we propose a PCSD continual learning framework to improve the forgery detectability and avoid catastrophic forgetting when handling new tasks. Our continual learning framework restricts intermediate features from the PHD network, and takes advantage of both cube pooling and strip pooling. Extensive experiments on publicly available datasets demonstrate the good performance of CMFDFormer and the effectiveness of the PCSD continual learning framework.
Quadric Representations for LiDAR Odometry, Mapping and Localization
Apr 27, 2023



Current LiDAR odometry, mapping and localization methods leverage point-wise representations of 3D scenes and achieve high accuracy in autonomous driving tasks. However, the space-inefficiency of methods that use point-wise representations limits their development and usage in practical applications. In particular, scan-submap matching and global map representation methods are restricted by the inefficiency of nearest neighbor searching (NNS) for large-volume point clouds. To improve space-time efficiency, we propose a novel method of describing scenes using quadric surfaces, which are far more compact representations of 3D objects than conventional point clouds. In contrast to point cloud-based methods, our quadric representation-based method decomposes a 3D scene into a collection of sparse quadric patches, which improves storage efficiency and avoids the slow point-wise NNS process. Our method first segments a given point cloud into patches and fits each of them to a quadric implicit function. Each function is then coupled with other geometric descriptors of the patch, such as its center position and covariance matrix. Collectively, these patch representations fully describe a 3D scene, which can be used in place of the original point cloud and employed in LiDAR odometry, mapping and localization algorithms. We further design a novel incremental growing method for quadric representations, which eliminates the need to repeatedly re-fit quadric surfaces from the original point cloud. Extensive odometry, mapping and localization experiments on large-volume point clouds in the KITTI and UrbanLoco datasets demonstrate that our method maintains low latency and memory utility while achieving competitive, and even superior, accuracy.
Two-Stage Copy-Move Forgery Detection with Self Deep Matching and Proposal SuperGlue
Dec 16, 2020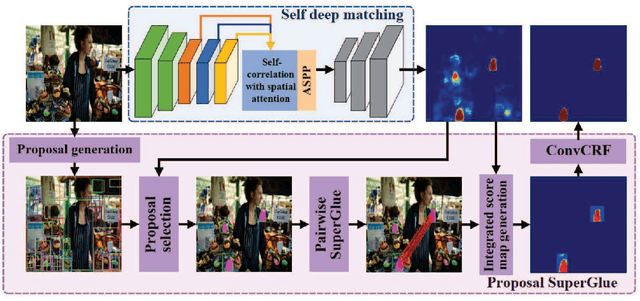
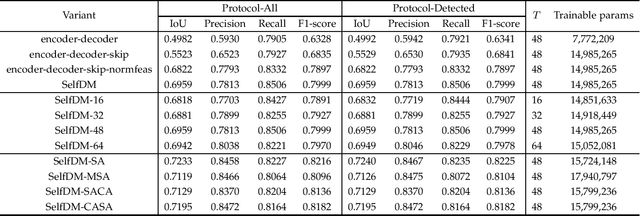
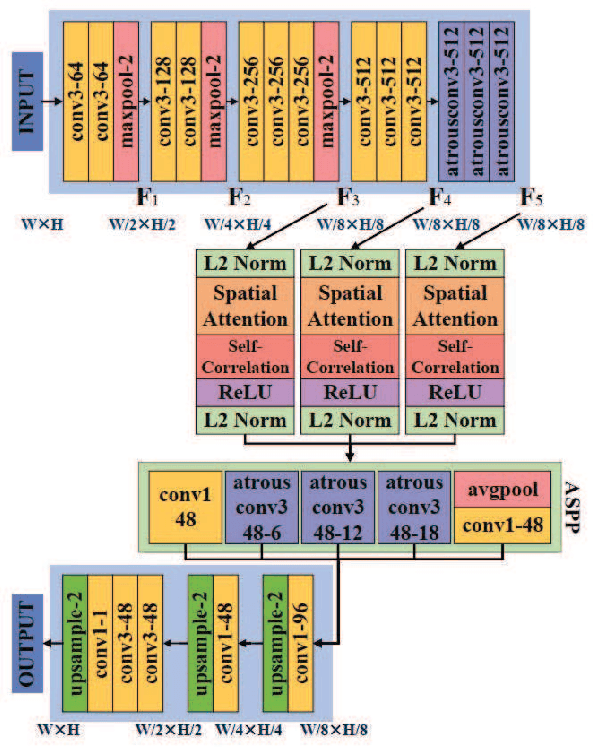

Copy-move forgery detection identifies a tampered image by detecting pasted and source regions in the same image. In this paper, we propose a novel two-stage framework specially for copy-move forgery detection. The first stage is a backbone self deep matching network, and the second stage is named as Proposal SuperGlue. In the first stage, atrous convolution and skip matching are incorporated to enrich spatial information and leverage hierarchical features. Spatial attention is built on self-correlation to reinforce the ability to find appearance similar regions. In the second stage, Proposal SuperGlue is proposed to remove false-alarmed regions and remedy incomplete regions. Specifically, a proposal selection strategy is designed to enclose highly suspected regions based on proposal generation and backbone score maps. Then, pairwise matching is conducted among candidate proposals by deep learning based keypoint extraction and matching, i.e., SuperPoint and SuperGlue. Integrated score map generation and refinement methods are designed to integrate results of both stages and obtain optimized results. Our two-stage framework unifies end-to-end deep matching and keypoint matching by obtaining highly suspected proposals, and opens a new gate for deep learning research in copy-move forgery detection. Experiments on publicly available datasets demonstrate the effectiveness of our two-stage framework.
What Will Your Child Look Like? DNA-Net: Age and Gender Aware Kin Face Synthesizer
Nov 16, 2019
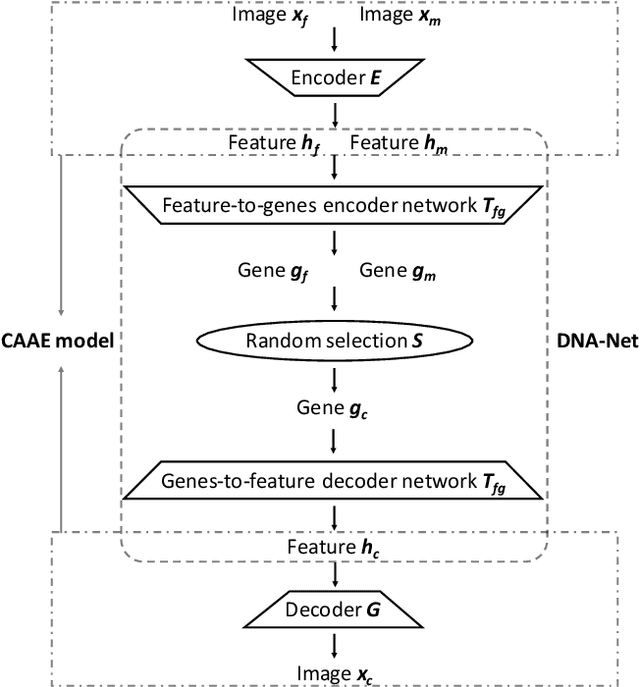
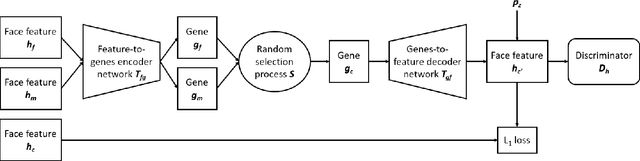

Visual kinship recognition aims to identify blood relatives from facial images. Its practical application-- like in law-enforcement, video surveillance, automatic family album management, and more-- has motivated many researchers to put forth effort on the topic as of recent. In this paper, we focus on a new view of visual kinship technology: kin-based face generation. Specifically, we propose a two-stage kin-face generation model to predict the appearance of a child given a pair of parents. The first stage includes a deep generative adversarial autoencoder conditioned on ages and genders to map between facial appearance and high-level features. The second stage is our proposed DNA-Net, which serves as a transformation between the deep and genetic features based on a random selection process to fuse genes of a parent pair to form the genes of a child. We demonstrate the effectiveness of the proposed method quantitatively and qualitatively: quantitatively, pre-trained models and human subjects perform kinship verification on the generated images of children; qualitatively, we show photo-realistic face images of children that closely resemble the given pair of parents. In the end, experiments validate that the proposed model synthesizes convincing kin-faces using both subjective and objective standards.