 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAd Insertion in LLM-Generated Responses
Jan 27, 2026Sustainable monetization of Large Language Models (LLMs) remains a critical open challenge. Traditional search advertising, which relies on static keywords, fails to capture the fleeting, context-dependent user intents--the specific information, goods, or services a user seeks--embedded in conversational flows. Beyond the standard goal of social welfare maximization, effective LLM advertising imposes additional requirements on contextual coherence (ensuring ads align semantically with transient user intents) and computational efficiency (avoiding user interaction latency), as well as adherence to ethical and regulatory standards, including preserving privacy and ensuring explicit ad disclosure. Although various recent solutions have explored bidding on token-level and query-level, both categories of approaches generally fail to holistically satisfy this multifaceted set of constraints. We propose a practical framework that resolves these tensions through two decoupling strategies. First, we decouple ad insertion from response generation to ensure safety and explicit disclosure. Second, we decouple bidding from specific user queries by using ``genres'' (high-level semantic clusters) as a proxy. This allows advertisers to bid on stable categories rather than sensitive real-time response, reducing computational burden and privacy risks. We demonstrate that applying the VCG auction mechanism to this genre-based framework yields approximately dominant strategy incentive compatibility (DSIC) and individual rationality (IR), as well as approximately optimal social welfare, while maintaining high computational efficiency. Finally, we introduce an "LLM-as-a-Judge" metric to estimate contextual coherence. Our experiments show that this metric correlates strongly with human ratings (Spearman's $ρ\approx 0.66$), outperforming 80% of individual human evaluators.
Benchmarking LLMs' Judgments with No Gold Standard
Nov 11, 2024



We introduce the GEM (Generative Estimator for Mutual Information), an evaluation metric for assessing language generation by Large Language Models (LLMs), particularly in generating informative judgments, without the need for a gold standard reference. GEM broadens the scenarios where we can benchmark LLM generation performance-from traditional ones, like machine translation and summarization, where gold standard references are readily available, to subjective tasks without clear gold standards, such as academic peer review. GEM uses a generative model to estimate mutual information between candidate and reference responses, without requiring the reference to be a gold standard. In experiments on a human-annotated dataset, GEM demonstrates competitive correlations with human scores compared to the state-of-the-art GPT-4o Examiner, and outperforms all other baselines. Additionally, GEM is more robust against strategic manipulations, such as rephrasing or elongation, which can artificially inflate scores under a GPT-4o Examiner. We also present GRE-bench (Generating Review Evaluation Benchmark) which evaluates LLMs based on how well they can generate high-quality peer reviews for academic research papers. Because GRE-bench is based upon GEM, it inherits its robustness properties. Additionally, GRE-bench circumvents data contamination problems (or data leakage) by using the continuous influx of new open-access research papers and peer reviews each year. We show GRE-bench results of various popular LLMs on their peer review capabilities using the ICLR2023 dataset.
Eliciting Informative Text Evaluations with Large Language Models
May 28, 2024
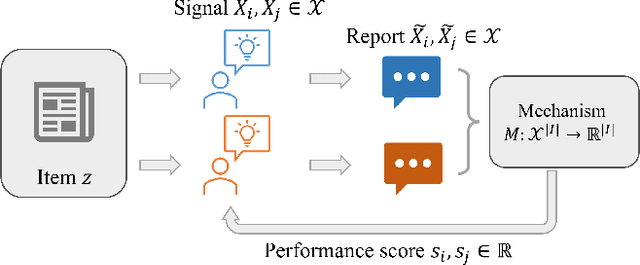


Peer prediction mechanisms motivate high-quality feedback with provable guarantees. However, current methods only apply to rather simple reports, like multiple-choice or scalar numbers. We aim to broaden these techniques to the larger domain of text-based reports, drawing on the recent developments in large language models. This vastly increases the applicability of peer prediction mechanisms as textual feedback is the norm in a large variety of feedback channels: peer reviews, e-commerce customer reviews, and comments on social media. We introduce two mechanisms, the Generative Peer Prediction Mechanism (GPPM) and the Generative Synopsis Peer Prediction Mechanism (GSPPM). These mechanisms utilize LLMs as predictors, mapping from one agent's report to a prediction of her peer's report. Theoretically, we show that when the LLM prediction is sufficiently accurate, our mechanisms can incentivize high effort and truth-telling as an (approximate) Bayesian Nash equilibrium. Empirically, we confirm the efficacy of our mechanisms through experiments conducted on two real datasets: the Yelp review dataset and the ICLR OpenReview dataset. We highlight the results that on the ICLR dataset, our mechanisms can differentiate three quality levels -- human-written reviews, GPT-4-generated reviews, and GPT-3.5-generated reviews in terms of expected scores. Additionally, GSPPM penalizes LLM-generated reviews more effectively than GPPM.
Spot Check Equivalence: an Interpretable Metric for Information Elicitation Mechanisms
Feb 21, 2024Because high-quality data is like oxygen for AI systems, effectively eliciting information from crowdsourcing workers has become a first-order problem for developing high-performance machine learning algorithms. Two prevalent paradigms, spot-checking and peer prediction, enable the design of mechanisms to evaluate and incentivize high-quality data from human labelers. So far, at least three metrics have been proposed to compare the performances of these techniques [33, 8, 3]. However, different metrics lead to divergent and even contradictory results in various contexts. In this paper, we harmonize these divergent stories, showing that two of these metrics are actually the same within certain contexts and explain the divergence of the third. Moreover, we unify these different contexts by introducing \textit{Spot Check Equivalence}, which offers an interpretable metric for the effectiveness of a peer prediction mechanism. Finally, we present two approaches to compute spot check equivalence in various contexts, where simulation results verify the effectiveness of our proposed metric.
Towards More Unified In-context Visual Understanding
Dec 05, 2023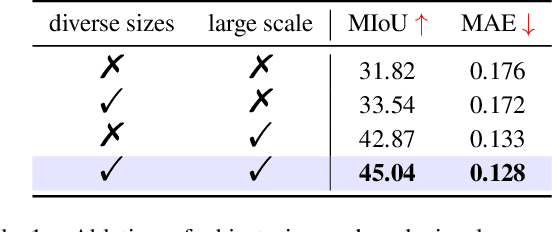
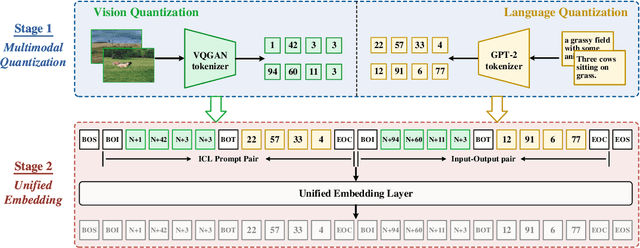

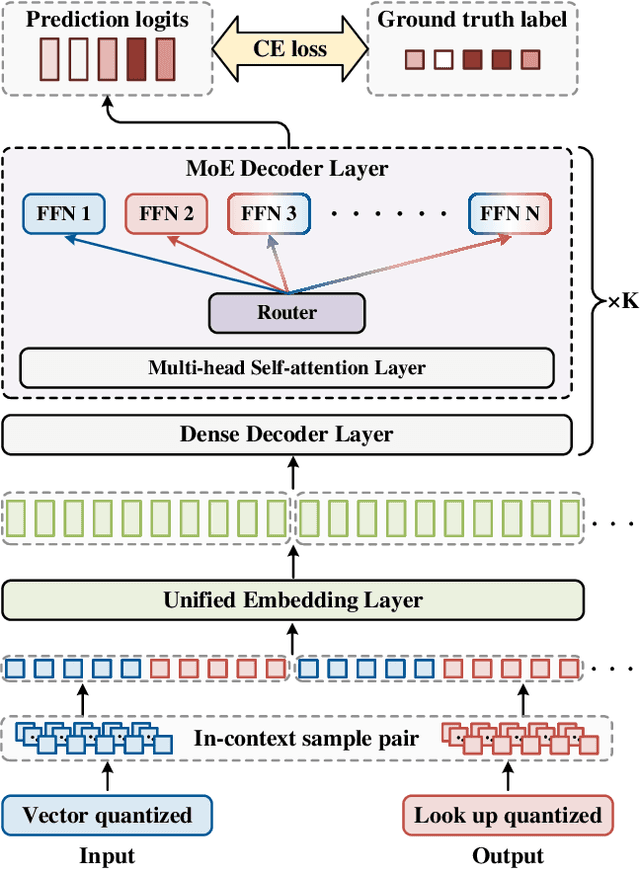
The rapid advancement of large language models (LLMs) has accelerated the emergence of in-context learning (ICL) as a cutting-edge approach in the natural language processing domain. Recently, ICL has been employed in visual understanding tasks, such as semantic segmentation and image captioning, yielding promising results. However, existing visual ICL framework can not enable producing content across multiple modalities, which limits their potential usage scenarios. To address this issue, we present a new ICL framework for visual understanding with multi-modal output enabled. First, we quantize and embed both text and visual prompt into a unified representational space, structured as interleaved in-context sequences. Then a decoder-only sparse transformer architecture is employed to perform generative modeling on them, facilitating in-context learning. Thanks to this design, the model is capable of handling in-context vision understanding tasks with multimodal output in a unified pipeline. Experimental results demonstrate that our model achieves competitive performance compared with specialized models and previous ICL baselines. Overall, our research takes a further step toward unified multimodal in-context learning.
Two-Stage Copy-Move Forgery Detection with Self Deep Matching and Proposal SuperGlue
Dec 16, 2020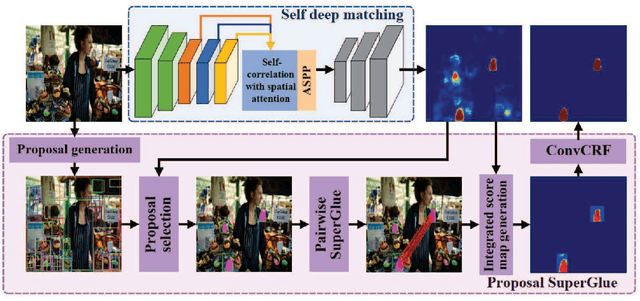
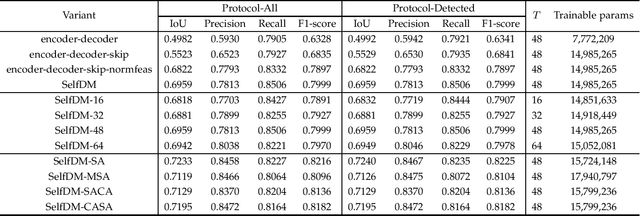
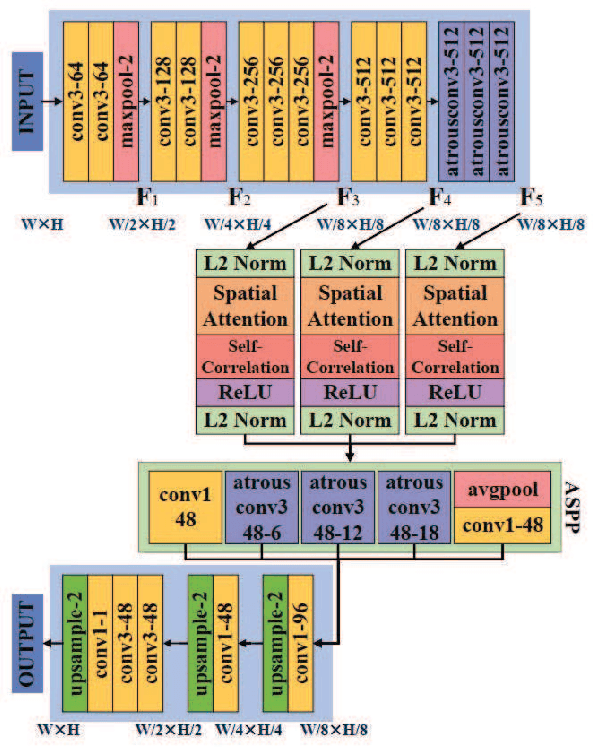

Copy-move forgery detection identifies a tampered image by detecting pasted and source regions in the same image. In this paper, we propose a novel two-stage framework specially for copy-move forgery detection. The first stage is a backbone self deep matching network, and the second stage is named as Proposal SuperGlue. In the first stage, atrous convolution and skip matching are incorporated to enrich spatial information and leverage hierarchical features. Spatial attention is built on self-correlation to reinforce the ability to find appearance similar regions. In the second stage, Proposal SuperGlue is proposed to remove false-alarmed regions and remedy incomplete regions. Specifically, a proposal selection strategy is designed to enclose highly suspected regions based on proposal generation and backbone score maps. Then, pairwise matching is conducted among candidate proposals by deep learning based keypoint extraction and matching, i.e., SuperPoint and SuperGlue. Integrated score map generation and refinement methods are designed to integrate results of both stages and obtain optimized results. Our two-stage framework unifies end-to-end deep matching and keypoint matching by obtaining highly suspected proposals, and opens a new gate for deep learning research in copy-move forgery detection. Experiments on publicly available datasets demonstrate the effectiveness of our two-stage framework.