 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAPL: Semantic-Agnostic Prompt Learning in CLIP for Weakly Supervised Image Manipulation Localization
Jan 09, 2026Malicious image manipulation threatens public safety and requires efficient localization methods. Existing approaches depend on costly pixel-level annotations which make training expensive. Existing weakly supervised methods rely only on image-level binary labels and focus on global classification, often overlooking local edge cues that are critical for precise localization. We observe that feature variations at manipulated boundaries are substantially larger than in interior regions. To address this gap, we propose Semantic-Agnostic Prompt Learning (SAPL) in CLIP, which learns text prompts that intentionally encode non-semantic, boundary-centric cues so that CLIPs multimodal similarity highlights manipulation edges rather than high-level object semantics. SAPL combines two complementary modules Edge-aware Contextual Prompt Learning (ECPL) and Hierarchical Edge Contrastive Learning (HECL) to exploit edge information in both textual and visual spaces. The proposed ECPL leverages edge-enhanced image features to generate learnable textual prompts via an attention mechanism, embedding semantic-irrelevant information into text features, to guide CLIP focusing on manipulation edges. The proposed HECL extract genuine and manipulated edge patches, and utilize contrastive learning to boost the discrimination between genuine edge patches and manipulated edge patches. Finally, we predict the manipulated regions from the similarity map after processing. Extensive experiments on multiple public benchmarks demonstrate that SAPL significantly outperforms existing approaches, achieving state-of-the-art localization performance.
NTIRE 2025 Challenge on Cross-Domain Few-Shot Object Detection: Methods and Results
Apr 14, 2025Cross-Domain Few-Shot Object Detection (CD-FSOD) poses significant challenges to existing object detection and few-shot detection models when applied across domains. In conjunction with NTIRE 2025, we organized the 1st CD-FSOD Challenge, aiming to advance the performance of current object detectors on entirely novel target domains with only limited labeled data. The challenge attracted 152 registered participants, received submissions from 42 teams, and concluded with 13 teams making valid final submissions. Participants approached the task from diverse perspectives, proposing novel models that achieved new state-of-the-art (SOTA) results under both open-source and closed-source settings. In this report, we present an overview of the 1st NTIRE 2025 CD-FSOD Challenge, highlighting the proposed solutions and summarizing the results submitted by the participants.
Context-Aware Weakly Supervised Image Manipulation Localization with SAM Refinement
Mar 26, 2025Malicious image manipulation poses societal risks, increasing the importance of effective image manipulation detection methods. Recent approaches in image manipulation detection have largely been driven by fully supervised approaches, which require labor-intensive pixel-level annotations. Thus, it is essential to explore weakly supervised image manipulation localization methods that only require image-level binary labels for training. However, existing weakly supervised image manipulation methods overlook the importance of edge information for accurate localization, leading to suboptimal localization performance. To address this, we propose a Context-Aware Boundary Localization (CABL) module to aggregate boundary features and learn context-inconsistency for localizing manipulated areas. Furthermore, by leveraging Class Activation Mapping (CAM) and Segment Anything Model (SAM), we introduce the CAM-Guided SAM Refinement (CGSR) module to generate more accurate manipulation localization maps. By integrating two modules, we present a novel weakly supervised framework based on a dual-branch Transformer-CNN architecture. Our method achieves outstanding localization performance across multiple datasets.
Towards More Unified In-context Visual Understanding
Dec 05, 2023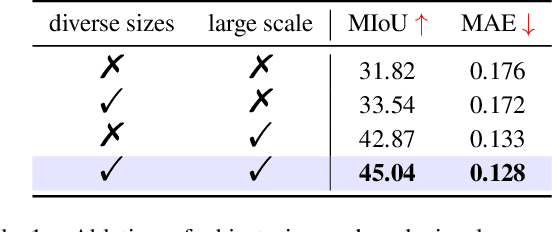
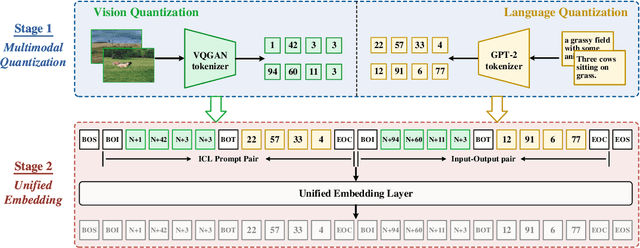

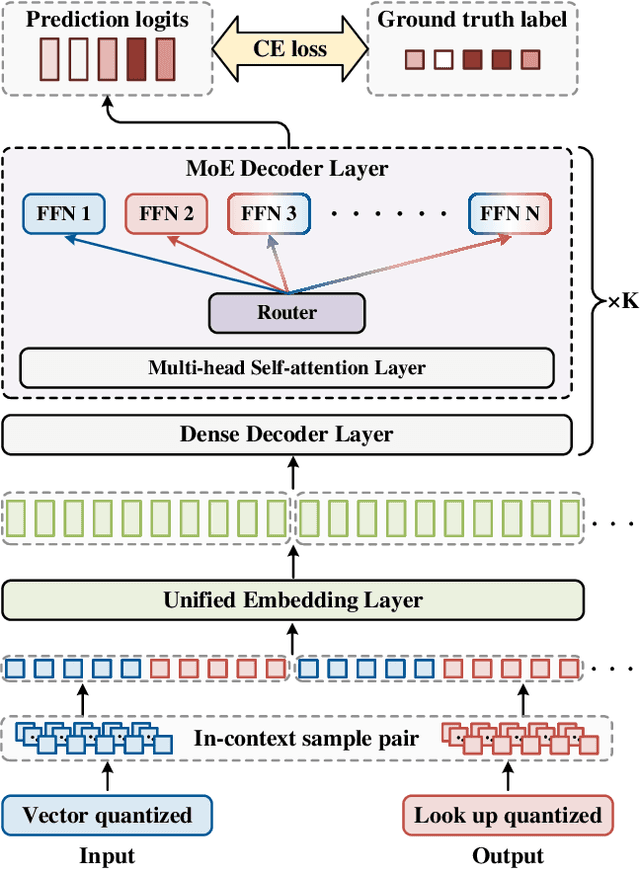
The rapid advancement of large language models (LLMs) has accelerated the emergence of in-context learning (ICL) as a cutting-edge approach in the natural language processing domain. Recently, ICL has been employed in visual understanding tasks, such as semantic segmentation and image captioning, yielding promising results. However, existing visual ICL framework can not enable producing content across multiple modalities, which limits their potential usage scenarios. To address this issue, we present a new ICL framework for visual understanding with multi-modal output enabled. First, we quantize and embed both text and visual prompt into a unified representational space, structured as interleaved in-context sequences. Then a decoder-only sparse transformer architecture is employed to perform generative modeling on them, facilitating in-context learning. Thanks to this design, the model is capable of handling in-context vision understanding tasks with multimodal output in a unified pipeline. Experimental results demonstrate that our model achieves competitive performance compared with specialized models and previous ICL baselines. Overall, our research takes a further step toward unified multimodal in-context learning.
X-Paste: Revisit Copy-Paste at Scale with CLIP and StableDiffusion
Dec 07, 2022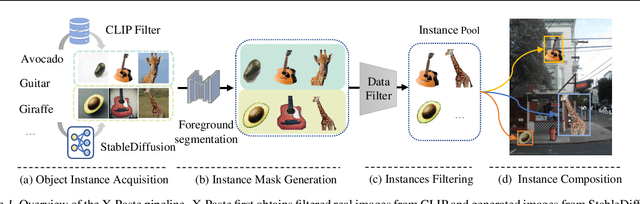



Copy-Paste is a simple and effective data augmentation strategy for instance segmentation. By randomly pasting object instances onto new background images, it creates new training data for free and significantly boosts the segmentation performance, especially for rare object categories. Although diverse, high-quality object instances used in Copy-Paste result in more performance gain, previous works utilize object instances either from human-annotated instance segmentation datasets or rendered from 3D object models, and both approaches are too expensive to scale up to obtain good diversity. In this paper, we revisit Copy-Paste at scale with the power of newly emerged zero-shot recognition models (e.g., CLIP) and text2image models (e.g., StableDiffusion). We demonstrate for the first time that using a text2image model to generate images or zero-shot recognition model to filter noisily crawled images for different object categories is a feasible way to make Copy-Paste truly scalable. To make such success happen, we design a data acquisition and processing framework, dubbed "X-Paste", upon which a systematic study is conducted. On the LVIS dataset, X-Paste provides impressive improvements over the strong baseline CenterNet2 with Swin-L as the backbone. Specifically, it archives +2.6 box AP and +2.1 mask AP gains on all classes and even more significant gains with +6.8 box AP +6.5 mask AP on long-tail classes.