 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreaking LLMs via Calibration
Jan 31, 2026Safety alignment in Large Language Models (LLMs) often creates a systematic discrepancy between a model's aligned output and the underlying pre-aligned data distribution. We propose a framework in which the effect of safety alignment on next-token prediction is modeled as a systematic distortion of a pre-alignment distribution. We cast Weak-to-Strong Jailbreaking as a forecast aggregation problem and derive an optimal aggregation strategy characterized by a Gradient Shift in the loss-induced dual space. We show that logit-arithmetic jailbreaking methods are a special case of this framework under cross-entropy loss, and derive a broader family of aggregation rules corresponding to other proper losses. We also propose a new hybrid aggregation rule. Evaluations across red-teaming benchmarks and math utility tasks using frontier models demonstrate that our approach achieves superior Attack Success Rates and lower "Jailbreak Tax" compared with existing methods, especially on the safety-hardened gpt-oss-120b.
Calibration without Ground Truth
Jan 27, 2026Villalobos et al. [2024] predict that publicly available human text will be exhausted within the next decade. Thus, improving models without access to ground-truth labels becomes increasingly important. We propose a label-free post-processing framework that improves a strong but miscalibrated model using a weaker yet better-calibrated reference. Our framework guarantees a strict performance improvement under any proper loss. Our approach is based on a characterization of when strict improvement is possible: when the strong and reference models are not mutually calibrated. We formalize this condition, connect it to arbitrage and no-trade results from economics, and develop an efficient Bregman projection algorithm that guarantees worst-case loss reduction without labels. Experiments on representative LLMs across varying scales demonstrate that our label-free method significantly reduces proper losses and calibration errors, achieving performance competitive with supervised baselines.
Mitigating the Participation Bias by Balancing Extreme Ratings
Feb 06, 2025



Rating aggregation plays a crucial role in various fields, such as product recommendations, hotel rankings, and teaching evaluations. However, traditional averaging methods can be affected by participation bias, where some raters do not participate in the rating process, leading to potential distortions. In this paper, we consider a robust rating aggregation task under the participation bias. We assume that raters may not reveal their ratings with a certain probability depending on their individual ratings, resulting in partially observed samples. Our goal is to minimize the expected squared loss between the aggregated ratings and the average of all underlying ratings (possibly unobserved) in the worst-case scenario. We focus on two settings based on whether the sample size (i.e. the number of raters) is known. In the first setting, where the sample size is known, we propose an aggregator, named as the Balanced Extremes Aggregator. It estimates unrevealed ratings with a balanced combination of extreme ratings. When the sample size is unknown, we derive another aggregator, the Polarizing-Averaging Aggregator, which becomes optimal as the sample size grows to infinity. Numerical results demonstrate the superiority of our proposed aggregators in mitigating participation bias, compared to simple averaging and the spectral method. Furthermore, we validate the effectiveness of our aggregators on a real-world dataset.
Benchmarking LLMs' Judgments with No Gold Standard
Nov 11, 2024



We introduce the GEM (Generative Estimator for Mutual Information), an evaluation metric for assessing language generation by Large Language Models (LLMs), particularly in generating informative judgments, without the need for a gold standard reference. GEM broadens the scenarios where we can benchmark LLM generation performance-from traditional ones, like machine translation and summarization, where gold standard references are readily available, to subjective tasks without clear gold standards, such as academic peer review. GEM uses a generative model to estimate mutual information between candidate and reference responses, without requiring the reference to be a gold standard. In experiments on a human-annotated dataset, GEM demonstrates competitive correlations with human scores compared to the state-of-the-art GPT-4o Examiner, and outperforms all other baselines. Additionally, GEM is more robust against strategic manipulations, such as rephrasing or elongation, which can artificially inflate scores under a GPT-4o Examiner. We also present GRE-bench (Generating Review Evaluation Benchmark) which evaluates LLMs based on how well they can generate high-quality peer reviews for academic research papers. Because GRE-bench is based upon GEM, it inherits its robustness properties. Additionally, GRE-bench circumvents data contamination problems (or data leakage) by using the continuous influx of new open-access research papers and peer reviews each year. We show GRE-bench results of various popular LLMs on their peer review capabilities using the ICLR2023 dataset.
The Surprising Benefits of Base Rate Neglect in Robust Aggregation
Jun 19, 2024Robust aggregation integrates predictions from multiple experts without knowledge of the experts' information structures. Prior work assumes experts are Bayesian, providing predictions as perfect posteriors based on their signals. However, real-world experts often deviate systematically from Bayesian reasoning. Our work considers experts who tend to ignore the base rate. We find that a certain degree of base rate neglect helps with robust forecast aggregation. Specifically, we consider a forecast aggregation problem with two experts who each predict a binary world state after observing private signals. Unlike previous work, we model experts exhibiting base rate neglect, where they incorporate the base rate information to degree $\lambda\in[0,1]$, with $\lambda=0$ indicating complete ignorance and $\lambda=1$ perfect Bayesian updating. To evaluate aggregators' performance, we adopt Arieli et al. (2018)'s worst-case regret model, which measures the maximum regret across the set of considered information structures compared to an omniscient benchmark. Our results reveal the surprising V-shape of regret as a function of $\lambda$. That is, predictions with an intermediate incorporating degree of base rate $\lambda<1$ can counter-intuitively lead to lower regret than perfect Bayesian posteriors with $\lambda=1$. We additionally propose a new aggregator with low regret robust to unknown $\lambda$. Finally, we conduct an empirical study to test the base rate neglect model and evaluate the performance of various aggregators.
Eliciting Informative Text Evaluations with Large Language Models
May 28, 2024
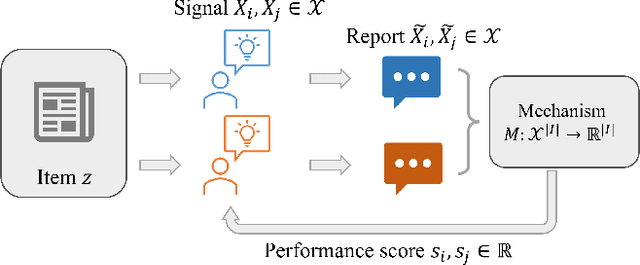


Peer prediction mechanisms motivate high-quality feedback with provable guarantees. However, current methods only apply to rather simple reports, like multiple-choice or scalar numbers. We aim to broaden these techniques to the larger domain of text-based reports, drawing on the recent developments in large language models. This vastly increases the applicability of peer prediction mechanisms as textual feedback is the norm in a large variety of feedback channels: peer reviews, e-commerce customer reviews, and comments on social media. We introduce two mechanisms, the Generative Peer Prediction Mechanism (GPPM) and the Generative Synopsis Peer Prediction Mechanism (GSPPM). These mechanisms utilize LLMs as predictors, mapping from one agent's report to a prediction of her peer's report. Theoretically, we show that when the LLM prediction is sufficiently accurate, our mechanisms can incentivize high effort and truth-telling as an (approximate) Bayesian Nash equilibrium. Empirically, we confirm the efficacy of our mechanisms through experiments conducted on two real datasets: the Yelp review dataset and the ICLR OpenReview dataset. We highlight the results that on the ICLR dataset, our mechanisms can differentiate three quality levels -- human-written reviews, GPT-4-generated reviews, and GPT-3.5-generated reviews in terms of expected scores. Additionally, GSPPM penalizes LLM-generated reviews more effectively than GPPM.
Robust Decision Aggregation with Adversarial Experts
Mar 13, 2024
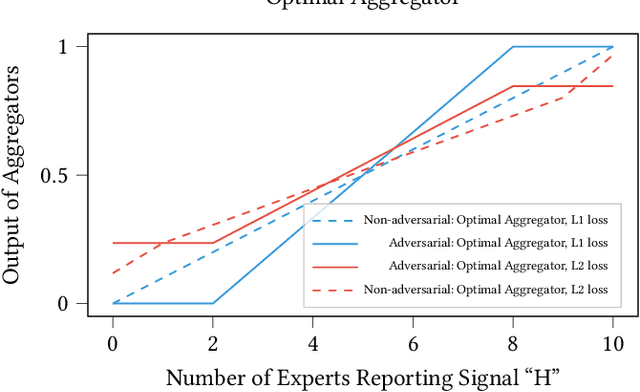
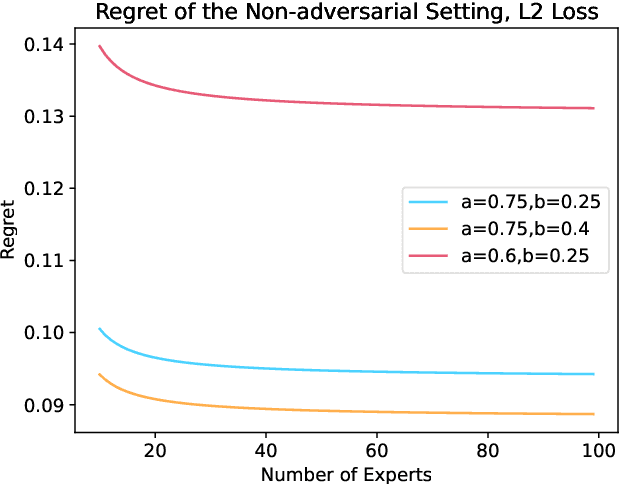
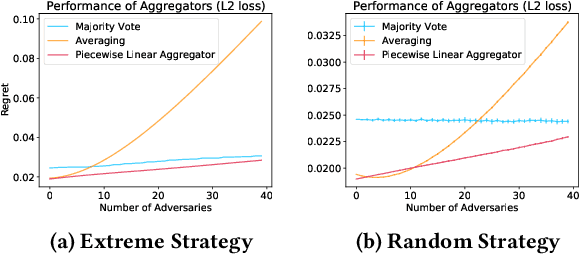
We consider a binary decision aggregation problem in the presence of both truthful and adversarial experts. The truthful experts will report their private signals truthfully with proper incentive, while the adversarial experts can report arbitrarily. The decision maker needs to design a robust aggregator to forecast the true state of the world based on the reports of experts. The decision maker does not know the specific information structure, which is a joint distribution of signals, states, and strategies of adversarial experts. We want to find the optimal aggregator minimizing regret under the worst information structure. The regret is defined by the difference in expected loss between the aggregator and a benchmark who makes the optimal decision given the joint distribution and reports of truthful experts. We prove that when the truthful experts are symmetric and adversarial experts are not too numerous, the truncated mean is optimal, which means that we remove some lowest reports and highest reports and take averaging among the left reports. Moreover, for many settings, the optimal aggregators are in the family of piecewise linear functions. The regret is independent of the total number of experts but only depends on the ratio of adversaries. We evaluate our aggregators by numerical experiment in an ensemble learning task. We also obtain some negative results for the aggregation problem with adversarial experts under some more general information structures and experts' report space.
Algorithmic Robust Forecast Aggregation
Jan 31, 2024



Forecast aggregation combines the predictions of multiple forecasters to improve accuracy. However, the lack of knowledge about forecasters' information structure hinders optimal aggregation. Given a family of information structures, robust forecast aggregation aims to find the aggregator with minimal worst-case regret compared to the omniscient aggregator. Previous approaches for robust forecast aggregation rely on heuristic observations and parameter tuning. We propose an algorithmic framework for robust forecast aggregation. Our framework provides efficient approximation schemes for general information aggregation with a finite family of possible information structures. In the setting considered by Arieli et al. (2018) where two agents receive independent signals conditioned on a binary state, our framework also provides efficient approximation schemes by imposing Lipschitz conditions on the aggregator or discrete conditions on agents' reports. Numerical experiments demonstrate the effectiveness of our method by providing a nearly optimal aggregator in the setting considered by Arieli et al. (2018).
Robust Decision Aggregation with Second-order Information
Nov 23, 2023We consider a decision aggregation problem with two experts who each make a binary recommendation after observing a private signal about an unknown binary world state. An agent, who does not know the joint information structure between signals and states, sees the experts' recommendations and aims to match the action with the true state. Under the scenario, we study whether supplemented additionally with second-order information (each expert's forecast on the other's recommendation) could enable a better aggregation. We adopt a minimax regret framework to evaluate the aggregator's performance, by comparing it to an omniscient benchmark that knows the joint information structure. With general information structures, we show that second-order information provides no benefit. No aggregator can improve over a trivial aggregator, which always follows the first expert's recommendation. However, positive results emerge when we assume experts' signals are conditionally independent given the world state. When the aggregator is deterministic, we present a robust aggregator that leverages second-order information, which can significantly outperform counterparts without it. Second, when two experts are homogeneous, by adding a non-degenerate assumption on the signals, we demonstrate that random aggregators using second-order information can surpass optimal ones without it. In the remaining settings, the second-order information is not beneficial. We also extend the above results to the setting when the aggregator's utility function is more general.
Near-Optimal Experimental Design Under the Budget Constraint in Online Platforms
Feb 10, 2023A/B testing, or controlled experiments, is the gold standard approach to causally compare the performance of algorithms on online platforms. However, conventional Bernoulli randomization in A/B testing faces many challenges such as spillover and carryover effects. Our study focuses on another challenge, especially for A/B testing on two-sided platforms -- budget constraints. Buyers on two-sided platforms often have limited budgets, where the conventional A/B testing may be infeasible to be applied, partly because two variants of allocation algorithms may conflict and lead some buyers to exceed their budgets if they are implemented simultaneously. We develop a model to describe two-sided platforms where buyers have limited budgets. We then provide an optimal experimental design that guarantees small bias and minimum variance. Bias is lower when there is more budget and a higher supply-demand rate. We test our experimental design on both synthetic data and real-world data, which verifies the theoretical results and shows our advantage compared to Bernoulli randomization.