 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeller-Side Experiments under Interference Induced by Feedback Loops in Two-Sided Platforms
Jan 29, 2024Two-sided platforms are central to modern commerce and content sharing and often utilize A/B testing for developing new features. While user-side experiments are common, seller-side experiments become crucial for specific interventions and metrics. This paper investigates the effects of interference caused by feedback loops on seller-side experiments in two-sided platforms, with a particular focus on the counterfactual interleaving design, proposed in \citet{ha2020counterfactual,nandy2021b}. These feedback loops, often generated by pacing algorithms, cause outcomes from earlier sessions to influence subsequent ones. This paper contributes by creating a mathematical framework to analyze this interference, theoretically estimating its impact, and conducting empirical evaluations of the counterfactual interleaving design in real-world scenarios. Our research shows that feedback loops can result in misleading conclusions about the treatment effects.
Near-Optimal Experimental Design Under the Budget Constraint in Online Platforms
Feb 10, 2023A/B testing, or controlled experiments, is the gold standard approach to causally compare the performance of algorithms on online platforms. However, conventional Bernoulli randomization in A/B testing faces many challenges such as spillover and carryover effects. Our study focuses on another challenge, especially for A/B testing on two-sided platforms -- budget constraints. Buyers on two-sided platforms often have limited budgets, where the conventional A/B testing may be infeasible to be applied, partly because two variants of allocation algorithms may conflict and lead some buyers to exceed their budgets if they are implemented simultaneously. We develop a model to describe two-sided platforms where buyers have limited budgets. We then provide an optimal experimental design that guarantees small bias and minimum variance. Bias is lower when there is more budget and a higher supply-demand rate. We test our experimental design on both synthetic data and real-world data, which verifies the theoretical results and shows our advantage compared to Bernoulli randomization.
Dynamic Budget Throttling in Repeated Second-Price Auctions
Jul 15, 2022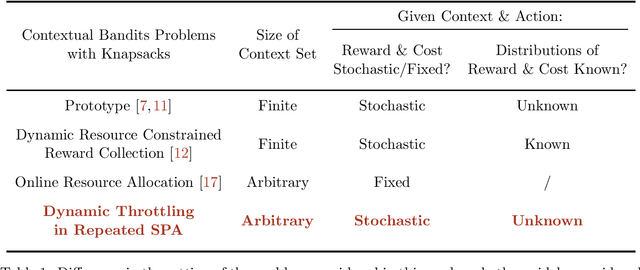
Throttling is one of the most popular budget control methods in today's online advertising markets. When a budget-constrained advertiser employs throttling, she can choose whether or not to participate in an auction after the advertising platform recommends a bid. This paper focuses on the dynamic budget throttling process in repeated second-price auctions from a theoretical view. An essential feature of the underlying problem is that the advertiser does not know the distribution of the highest competing bid upon entering the market. To model the difficulty of eliminating such uncertainty, we consider two different information structures. The advertiser could obtain the highest competing bid in each round with full-information feedback. Meanwhile, with partial information feedback, the advertiser could only have access to the highest competing bid in the auctions she participates in. We propose the OGD-CB algorithm, which involves simultaneous distribution learning and revenue optimization. In both settings, we demonstrate that this algorithm guarantees an $O(\sqrt{T\log T})$ regret with probability $1 - O(1/T)$ relative to the fluid adaptive throttling benchmark. By proving a lower bound of $\Omega(\sqrt{T})$ on the minimal regret for even the hindsight optimum, we establish the near optimality of our algorithm. Finally, we compare the fluid optimum of throttling to that of pacing, another widely adopted budget control method. The numerical relationship of these benchmarks sheds new light on the understanding of different online algorithms for revenue maximization under budget constraints.
Inspecting the Process of Bank Credit Rating via Visual Analytics
Aug 06, 2021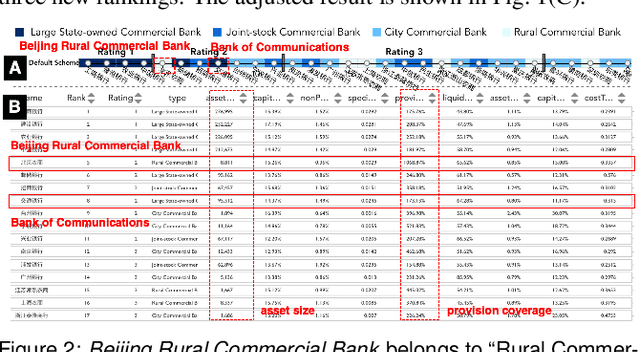
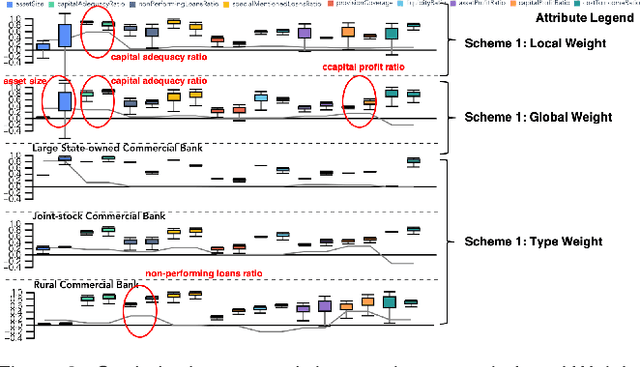
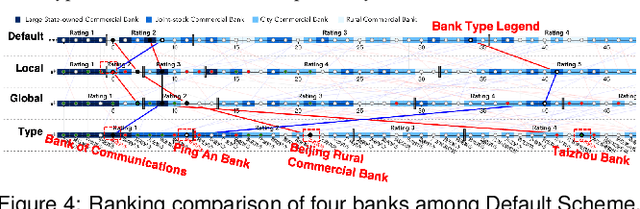
Bank credit rating classifies banks into different levels based on publicly disclosed and internal information, serving as an important input in financial risk management. However, domain experts have a vague idea of exploring and comparing different bank credit rating schemes. A loose connection between subjective and quantitative analysis and difficulties in determining appropriate indicator weights obscure understanding of bank credit ratings. Furthermore, existing models fail to consider bank types by just applying a unified indicator weight set to all banks. We propose RatingVis to assist experts in exploring and comparing different bank credit rating schemes. It supports interactively inferring indicator weights for banks by involving domain knowledge and considers bank types in the analysis loop. We conduct a case study with real-world bank data to verify the efficacy of RatingVis. Expert feedback suggests that our approach helps them better understand different rating schemes.