 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Semantic Collaborative Integration: Why Alignment Is Not Enough
Apr 24, 2026Large language models (LLMs) have become an important semantic infrastructure for modern recommender systems. A prevailing paradigm integrates LLM-derived semantic embeddings with collaborative representations via representation alignment, implicitly assuming that the two views encode a shared latent entity and that stronger alignment yields better results. We formalize this assumption as the global low-complexity alignment hypothesis and argue that it is stronger than necessary and often structurally mismatched with real-world recommendation settings. We propose a complementary perspective in which semantic and collaborative representations are treated as partially shared yet fundamentally heterogeneous views, each containing both shared and view-specific factors. Under this shared-plus-private latent structure, enforcing global geometric alignment may distort local structure, suppress view-specific signals, and reduce informational diversity. To support this perspective, we develop complementarity-aware diagnostics that quantify overlap, unique-hit contribution, and theoretical fusion upper bounds. Empirical analyses on sparse recommendation benchmarks reveal low item-level agreement between semantic and collaborative views and substantial oracle fusion gains, indicating strong complementarity. Furthermore, controlled alignment probes show that low-capacity mappings capture only shared components and fail to recover full collaborative geometry, especially under distribution shift. These findings suggest that alignment should not be treated as the default integration principle. We advocate a shift from alignment-centric modeling to complementarity fusion-centric, complementarity-aware design, where shared factors are selectively integrated while private signals are preserved. This reframing provides a principled foundation for the next generation of LLM-enhanced recommender systems.
SciGPT: A Large Language Model for Scientific Literature Understanding and Knowledge Discovery
Sep 09, 2025Scientific literature is growing exponentially, creating a critical bottleneck for researchers to efficiently synthesize knowledge. While general-purpose Large Language Models (LLMs) show potential in text processing, they often fail to capture scientific domain-specific nuances (e.g., technical jargon, methodological rigor) and struggle with complex scientific tasks, limiting their utility for interdisciplinary research. To address these gaps, this paper presents SciGPT, a domain-adapted foundation model for scientific literature understanding and ScienceBench, an open source benchmark tailored to evaluate scientific LLMs. Built on the Qwen3 architecture, SciGPT incorporates three key innovations: (1) low-cost domain distillation via a two-stage pipeline to balance performance and efficiency; (2) a Sparse Mixture-of-Experts (SMoE) attention mechanism that cuts memory consumption by 55\% for 32,000-token long-document reasoning; and (3) knowledge-aware adaptation integrating domain ontologies to bridge interdisciplinary knowledge gaps. Experimental results on ScienceBench show that SciGPT outperforms GPT-4o in core scientific tasks including sequence labeling, generation, and inference. It also exhibits strong robustness in unseen scientific tasks, validating its potential to facilitate AI-augmented scientific discovery.
Beyond Quality: Unlocking Diversity in Ad Headline Generation with Large Language Models
Aug 26, 2025
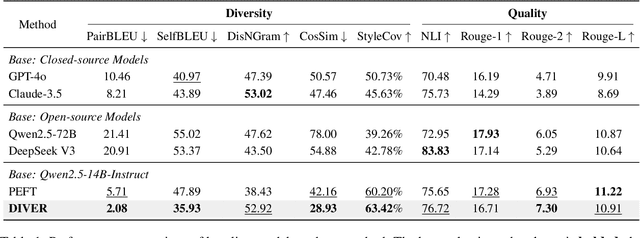
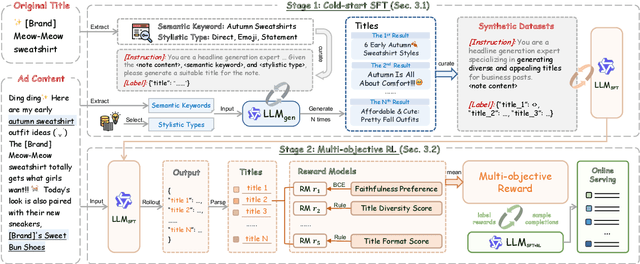
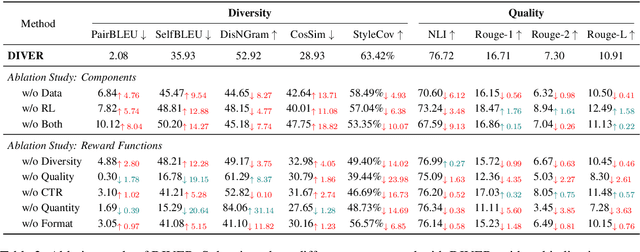
The generation of ad headlines plays a vital role in modern advertising, where both quality and diversity are essential to engage a broad range of audience segments. Current approaches primarily optimize language models for headline quality or click-through rates (CTR), often overlooking the need for diversity and resulting in homogeneous outputs. To address this limitation, we propose DIVER, a novel framework based on large language models (LLMs) that are jointly optimized for both diversity and quality. We first design a semantic- and stylistic-aware data generation pipeline that automatically produces high-quality training pairs with ad content and multiple diverse headlines. To achieve the goal of generating high-quality and diversified ad headlines within a single forward pass, we propose a multi-stage multi-objective optimization framework with supervised fine-tuning (SFT) and reinforcement learning (RL). Experiments on real-world industrial datasets demonstrate that DIVER effectively balances quality and diversity. Deployed on a large-scale content-sharing platform serving hundreds of millions of users, our framework improves advertiser value (ADVV) and CTR by 4.0% and 1.4%.
Enhancing Privacy in Decentralized Min-Max Optimization: A Differentially Private Approach
Aug 10, 2025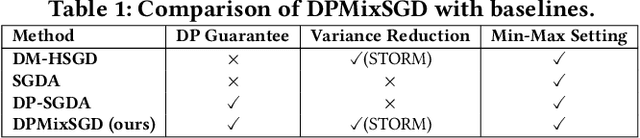

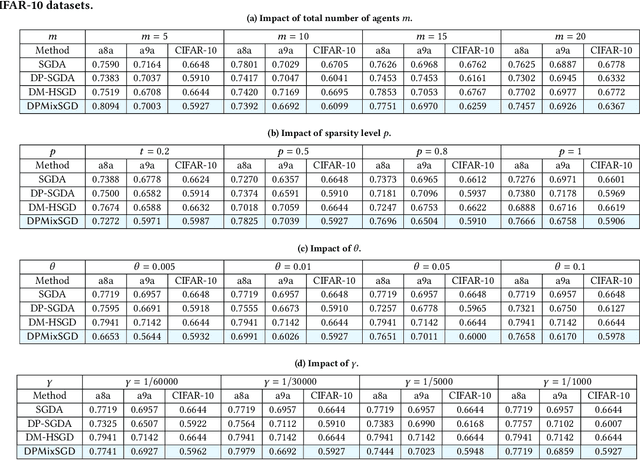

Decentralized min-max optimization allows multi-agent systems to collaboratively solve global min-max optimization problems by facilitating the exchange of model updates among neighboring agents, eliminating the need for a central server. However, sharing model updates in such systems carry a risk of exposing sensitive data to inference attacks, raising significant privacy concerns. To mitigate these privacy risks, differential privacy (DP) has become a widely adopted technique for safeguarding individual data. Despite its advantages, implementing DP in decentralized min-max optimization poses challenges, as the added noise can hinder convergence, particularly in non-convex scenarios with complex agent interactions in min-max optimization problems. In this work, we propose an algorithm called DPMixSGD (Differential Private Minmax Hybrid Stochastic Gradient Descent), a novel privacy-preserving algorithm specifically designed for non-convex decentralized min-max optimization. Our method builds on the state-of-the-art STORM-based algorithm, one of the fastest decentralized min-max solutions. We rigorously prove that the noise added to local gradients does not significantly compromise convergence performance, and we provide theoretical bounds to ensure privacy guarantees. To validate our theoretical findings, we conduct extensive experiments across various tasks and models, demonstrating the effectiveness of our approach.
A Metric for MLLM Alignment in Large-scale Recommendation
Aug 07, 2025
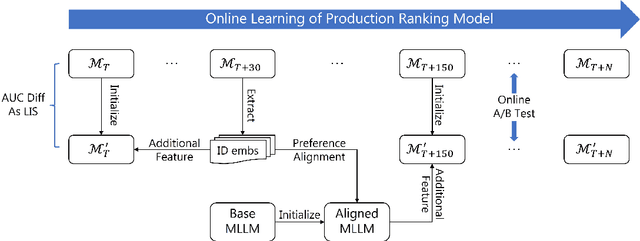


Multimodal recommendation has emerged as a critical technique in modern recommender systems, leveraging content representations from advanced multimodal large language models (MLLMs). To ensure these representations are well-adapted, alignment with the recommender system is essential. However, evaluating the alignment of MLLMs for recommendation presents significant challenges due to three key issues: (1) static benchmarks are inaccurate because of the dynamism in real-world applications, (2) evaluations with online system, while accurate, are prohibitively expensive at scale, and (3) conventional metrics fail to provide actionable insights when learned representations underperform. To address these challenges, we propose the Leakage Impact Score (LIS), a novel metric for multimodal recommendation. Rather than directly assessing MLLMs, LIS efficiently measures the upper bound of preference data. We also share practical insights on deploying MLLMs with LIS in real-world scenarios. Online A/B tests on both Content Feed and Display Ads of Xiaohongshu's Explore Feed production demonstrate the effectiveness of our proposed method, showing significant improvements in user spent time and advertiser value.
Accurate Multi-Category Student Performance Forecasting at Early Stages of Online Education Using Neural Networks
Dec 08, 2024The ability to accurately predict and analyze student performance in online education, both at the outset and throughout the semester, is vital. Most of the published studies focus on binary classification (Fail or Pass) but there is still a significant research gap in predicting students' performance across multiple categories. This study introduces a novel neural network-based approach capable of accurately predicting student performance and identifying vulnerable students at early stages of the online courses. The Open University Learning Analytics (OULA) dataset is employed to develop and test the proposed model, which predicts outcomes in Distinction, Fail, Pass, and Withdrawn categories. The OULA dataset is preprocessed to extract features from demographic data, assessment data, and clickstream interactions within a Virtual Learning Environment (VLE). Comparative simulations indicate that the proposed model significantly outperforms existing baseline models including Artificial Neural Network Long Short Term Memory (ANN-LSTM), Random Forest (RF) 'gini', RF 'entropy' and Deep Feed Forward Neural Network (DFFNN) in terms of accuracy, precision, recall, and F1-score. The results indicate that the prediction accuracy of the proposed method is about 25% more than the existing state-of-the-art. Furthermore, compared to existing methodologies, the model demonstrates superior predictive capability across temporal course progression, achieving superior accuracy even at the initial 20% phase of course completion.
WebCiteS: Attributed Query-Focused Summarization on Chinese Web Search Results with Citations
Mar 04, 2024Enhancing the attribution in large language models (LLMs) is a crucial task. One feasible approach is to enable LLMs to cite external sources that support their generations. However, existing datasets and evaluation methods in this domain still exhibit notable limitations. In this work, we formulate the task of attributed query-focused summarization (AQFS) and present WebCiteS, a Chinese dataset featuring 7k human-annotated summaries with citations. WebCiteS derives from real-world user queries and web search results, offering a valuable resource for model training and evaluation. Prior works in attribution evaluation do not differentiate between groundedness errors and citation errors. They also fall short in automatically verifying sentences that draw partial support from multiple sources. We tackle these issues by developing detailed metrics and enabling the automatic evaluator to decompose the sentences into sub-claims for fine-grained verification. Our comprehensive evaluation of both open-source and proprietary models on WebCiteS highlights the challenge LLMs face in correctly citing sources, underscoring the necessity for further improvement. The dataset and code will be open-sourced to facilitate further research in this crucial field.
Neural-Optic Co-Designed Polarization-Multiplexed Metalens for Compact Computational Spectral Imaging
Nov 26, 2023As the realm of spectral imaging applications extends its reach into the domains of mobile technology and augmented reality, the demands for compact yet high-fidelity systems become increasingly pronounced. Conventional methodologies, exemplified by coded aperture snapshot spectral imaging systems, are significantly limited by their cumbersome physical dimensions and form factors. To address this inherent challenge, diffractive optical elements (DOEs) have been repeatedly employed as a means to mitigate issues related to the bulky nature of these systems. Nonetheless, it's essential to note that the capabilities of DOEs primarily revolve around the modulation of the phase of light. Here, we introduce an end-to-end computational spectral imaging framework based on a polarization-multiplexed metalens. A distinguishing feature of this approach lies in its capacity to simultaneously modulate orthogonal polarization channels. When harnessed in conjunction with a neural network, it facilitates the attainment of high-fidelity spectral reconstruction. Importantly, the framework is intrinsically fully differentiable, a feature that permits the joint optimization of both the metalens structure and the parameters governing the neural network. The experimental results presented herein validate the exceptional spatial-spectral reconstruction performance, underscoring the efficacy of this system in practical, real-world scenarios. This innovative approach transcends the traditional boundaries separating hardware and software in the realm of computational imaging and holds the promise of substantially propelling the miniaturization of spectral imaging systems.
Efficient Post-training Quantization with FP8 Formats
Sep 26, 2023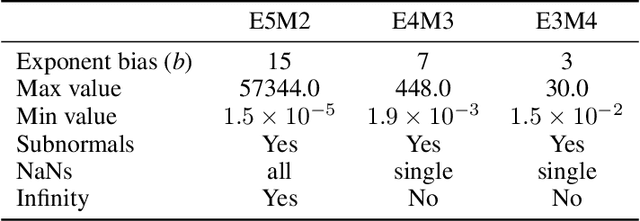

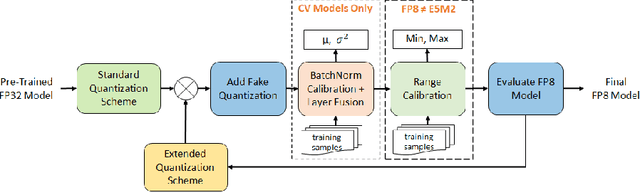
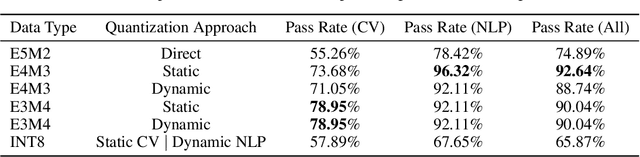
Recent advances in deep learning methods such as LLMs and Diffusion models have created a need for improved quantization methods that can meet the computational demands of these modern architectures while maintaining accuracy. Towards this goal, we study the advantages of FP8 data formats for post-training quantization across 75 unique network architectures covering a wide range of tasks, including machine translation, language modeling, text generation, image classification, generation, and segmentation. We examine three different FP8 representations (E5M2, E4M3, and E3M4) to study the effects of varying degrees of trade-off between dynamic range and precision on model accuracy. Based on our extensive study, we developed a quantization workflow that generalizes across different network architectures. Our empirical results show that FP8 formats outperform INT8 in multiple aspects, including workload coverage (92.64% vs. 65.87%), model accuracy and suitability for a broader range of operations. Furthermore, our findings suggest that E4M3 is better suited for NLP models, whereas E3M4 performs marginally better than E4M3 on computer vision tasks. The code is publicly available on Intel Neural Compressor: https://github.com/intel/neural-compressor.
On the Re-Solving Heuristic for Contextual Bandits with Knapsacks
Nov 25, 2022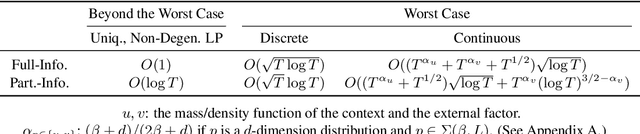

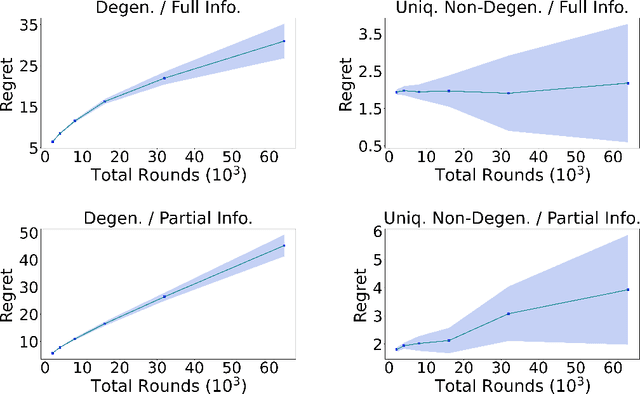
In the problem of (binary) contextual bandits with knapsacks (CBwK), the agent receives an i.i.d. context in each of the $T$ rounds and chooses an action, resulting in a random reward and a random consumption of resources that are related to an i.i.d. external factor. The agent's goal is to maximize the accumulated reward under the initial resource constraints. In this work, we combine the re-solving heuristic, which proved successful in revenue management, with distribution estimation techniques to solve this problem. We consider two different information feedback models, with full and partial information, which vary in the difficulty of getting a sample of the external factor. Under both information feedback settings, we achieve two-way results: (1) For general problems, we show that our algorithm gets an $\widetilde O(T^{\alpha_u} + T^{\alpha_v} + T^{1/2})$ regret against the fluid benchmark. Here, $\alpha_u$ and $\alpha_v$ reflect the complexity of the context and external factor distributions, respectively. This result is comparable to existing results. (2) When the fluid problem is linear programming with a unique and non-degenerate optimal solution, our algorithm leads to an $\widetilde O(1)$ regret. To the best of our knowledge, this is the first $\widetilde O(1)$ regret result in the CBwK problem regardless of information feedback models. We further use numerical experiments to verify our results.