 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebCiteS: Attributed Query-Focused Summarization on Chinese Web Search Results with Citations
Mar 04, 2024Enhancing the attribution in large language models (LLMs) is a crucial task. One feasible approach is to enable LLMs to cite external sources that support their generations. However, existing datasets and evaluation methods in this domain still exhibit notable limitations. In this work, we formulate the task of attributed query-focused summarization (AQFS) and present WebCiteS, a Chinese dataset featuring 7k human-annotated summaries with citations. WebCiteS derives from real-world user queries and web search results, offering a valuable resource for model training and evaluation. Prior works in attribution evaluation do not differentiate between groundedness errors and citation errors. They also fall short in automatically verifying sentences that draw partial support from multiple sources. We tackle these issues by developing detailed metrics and enabling the automatic evaluator to decompose the sentences into sub-claims for fine-grained verification. Our comprehensive evaluation of both open-source and proprietary models on WebCiteS highlights the challenge LLMs face in correctly citing sources, underscoring the necessity for further improvement. The dataset and code will be open-sourced to facilitate further research in this crucial field.
Named Entity Recognition Only from Word Embeddings
Aug 31, 2019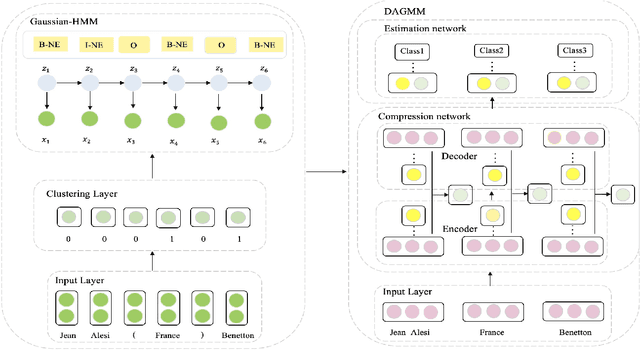
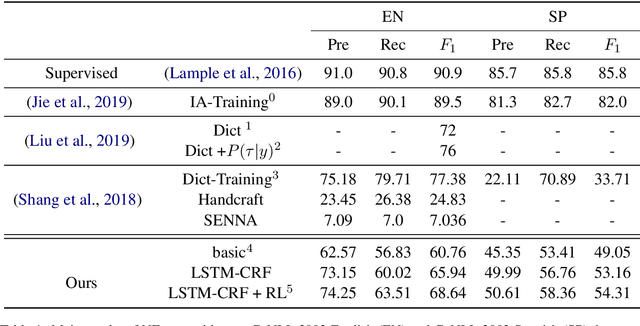
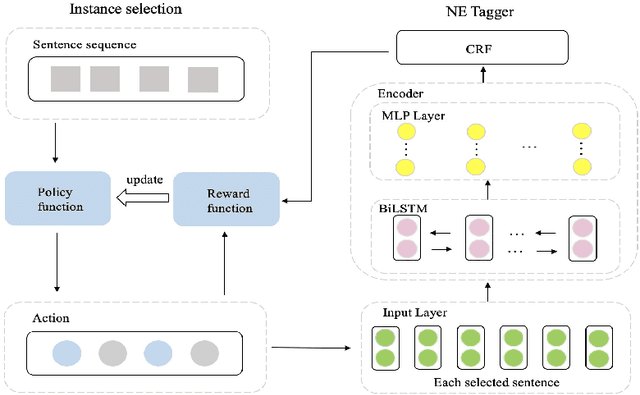

Deep neural network models have helped named entity (NE) recognition achieve amazing performance without handcrafting features. However, existing systems require large amounts of human annotated training data. Efforts have been made to replace human annotations with external knowledge (e.g., NE dictionary, part-of-speech tags), while it is another challenge to obtain such effective resources. In this work, we propose a fully unsupervised NE recognition model which only needs to take informative clues from pre-trained word embeddings. We first apply Gaussian Hidden Markov Model and Deep Autoencoding Gaussian Mixture Model on word embeddings for entity span detection and type prediction, and then further design an instance selector based on reinforcement learning to distinguish positive sentences from noisy sentences and refine these coarse-grained annotations through neural networks. Extensive experiments on CoNLL benchmark datasets demonstrate that our proposed light NE recognition model achieves remarkable performance without using any annotated lexicon or corpus.
Span Based Open Information Extraction
Mar 01, 2019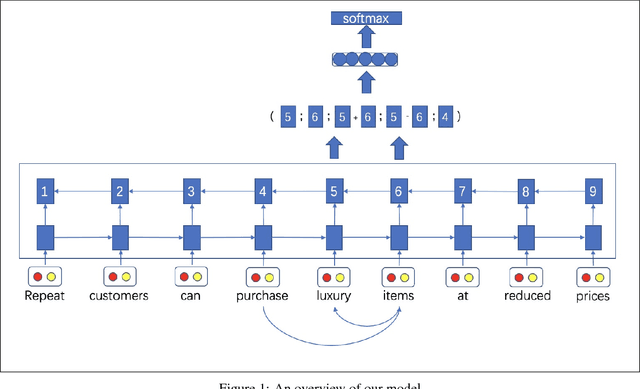
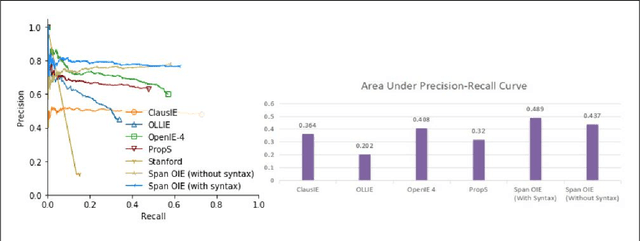
In this paper, we propose a span based model combined with syntactic information for n-ary open information extraction. The advantage of span model is that it can leverage span level features, which is difficult in token based BIO tagging methods. We also improve the previous bootstrap method to construct training corpus. Experiments show that our model outperforms previous open information extraction systems. Our code and data are publicly available at https://github.com/zhanjunlang/Span_OIE
Chemical Names Standardization using Neural Sequence to Sequence Model
Jan 21, 2019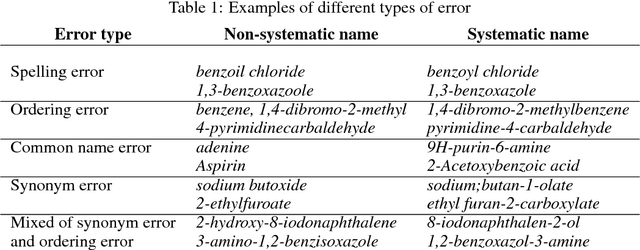
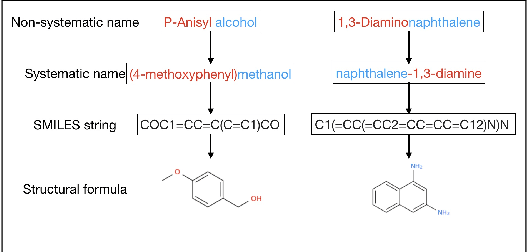
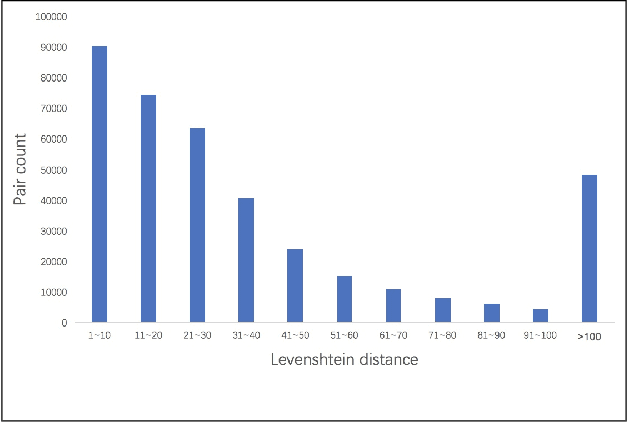
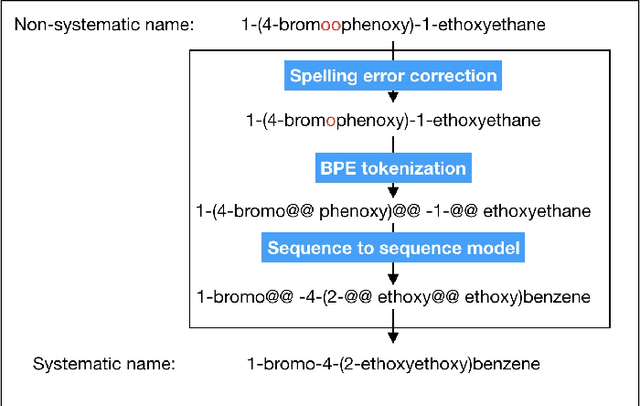
Chemical information extraction is to convert chemical knowledge in text into true chemical database, which is a text processing task heavily relying on chemical compound name identification and standardization. Once a systematic name for a chemical compound is given, it will naturally and much simply convert the name into the eventually required molecular formula. However, for many chemical substances, they have been shown in many other names besides their systematic names which poses a great challenge for this task. In this paper, we propose a framework to do the auto standardization from the non-systematic names to the corresponding systematic names by using the spelling error correction, byte pair encoding tokenization and neural sequence to sequence model. Our framework is trained end to end and is fully data-driven. Our standardization accuracy on the test dataset achieves 54.04% which has a great improvement compared to previous state-of-the-art result.