Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpan Based Open Information Extraction
Paper and Code
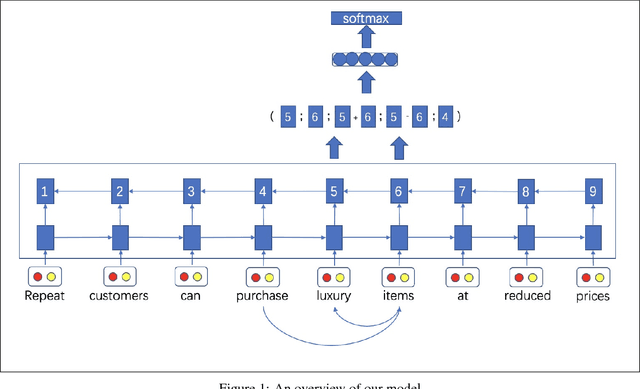
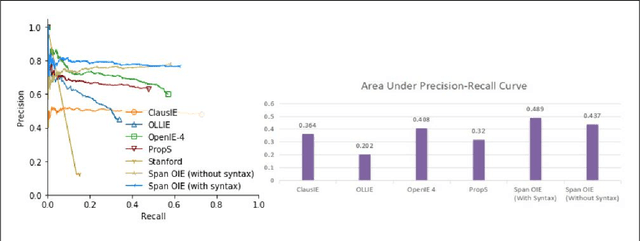
In this paper, we propose a span based model combined with syntactic information for n-ary open information extraction. The advantage of span model is that it can leverage span level features, which is difficult in token based BIO tagging methods. We also improve the previous bootstrap method to construct training corpus. Experiments show that our model outperforms previous open information extraction systems. Our code and data are publicly available at https://github.com/zhanjunlang/Span_OIE
* There is an error in this article. In section 2.2, we state that span
level syntactic information is helpful for Open IE, which is one of major
contribution of this paper. However, after our examination, there is a fatal
error in the code for this part so the statement is not true
View paper on