 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSERM: Self-Evolving Relevance Model with Agent-Driven Learning from Massive Query Streams
Jan 14, 2026Due to the dynamically evolving nature of real-world query streams, relevance models struggle to generalize to practical search scenarios. A sophisticated solution is self-evolution techniques. However, in large-scale industrial settings with massive query streams, this technique faces two challenges: (1) informative samples are often sparse and difficult to identify, and (2) pseudo-labels generated by the current model could be unreliable. To address these challenges, in this work, we propose a Self-Evolving Relevance Model approach (SERM), which comprises two complementary multi-agent modules: a multi-agent sample miner, designed to detect distributional shifts and identify informative training samples, and a multi-agent relevance annotator, which provides reliable labels through a two-level agreement framework. We evaluate SERM in a large-scale industrial setting, which serves billions of user requests daily. Experimental results demonstrate that SERM can achieve significant performance gains through iterative self-evolution, as validated by extensive offline multilingual evaluations and online testing.
Event-enhanced Retrieval in Real-time Search
Apr 09, 2024The embedding-based retrieval (EBR) approach is widely used in mainstream search engine retrieval systems and is crucial in recent retrieval-augmented methods for eliminating LLM illusions. However, existing EBR models often face the "semantic drift" problem and insufficient focus on key information, leading to a low adoption rate of retrieval results in subsequent steps. This issue is especially noticeable in real-time search scenarios, where the various expressions of popular events on the Internet make real-time retrieval heavily reliant on crucial event information. To tackle this problem, this paper proposes a novel approach called EER, which enhances real-time retrieval performance by improving the dual-encoder model of traditional EBR. We incorporate contrastive learning to accompany pairwise learning for encoder optimization. Furthermore, to strengthen the focus on critical event information in events, we include a decoder module after the document encoder, introduce a generative event triplet extraction scheme based on prompt-tuning, and correlate the events with query encoder optimization through comparative learning. This decoder module can be removed during inference. Extensive experiments demonstrate that EER can significantly improve the real-time search retrieval performance. We believe that this approach will provide new perspectives in the field of information retrieval. The codes and dataset are available at https://github.com/open-event-hub/Event-enhanced_Retrieval .
WebCiteS: Attributed Query-Focused Summarization on Chinese Web Search Results with Citations
Mar 04, 2024Enhancing the attribution in large language models (LLMs) is a crucial task. One feasible approach is to enable LLMs to cite external sources that support their generations. However, existing datasets and evaluation methods in this domain still exhibit notable limitations. In this work, we formulate the task of attributed query-focused summarization (AQFS) and present WebCiteS, a Chinese dataset featuring 7k human-annotated summaries with citations. WebCiteS derives from real-world user queries and web search results, offering a valuable resource for model training and evaluation. Prior works in attribution evaluation do not differentiate between groundedness errors and citation errors. They also fall short in automatically verifying sentences that draw partial support from multiple sources. We tackle these issues by developing detailed metrics and enabling the automatic evaluator to decompose the sentences into sub-claims for fine-grained verification. Our comprehensive evaluation of both open-source and proprietary models on WebCiteS highlights the challenge LLMs face in correctly citing sources, underscoring the necessity for further improvement. The dataset and code will be open-sourced to facilitate further research in this crucial field.
Event-driven Real-time Retrieval in Web Search
Dec 04, 2023Information retrieval in real-time search presents unique challenges distinct from those encountered in classical web search. These challenges are particularly pronounced due to the rapid change of user search intent, which is influenced by the occurrence and evolution of breaking news events, such as earthquakes, elections, and wars. Previous dense retrieval methods, which primarily focused on static semantic representation, lack the capacity to capture immediate search intent, leading to inferior performance in retrieving the most recent event-related documents in time-sensitive scenarios. To address this issue, this paper expands the query with event information that represents real-time search intent. The Event information is then integrated with the query through a cross-attention mechanism, resulting in a time-context query representation. We further enhance the model's capacity for event representation through multi-task training. Since publicly available datasets such as MS-MARCO do not contain any event information on the query side and have few time-sensitive queries, we design an automatic data collection and annotation pipeline to address this issue, which includes ModelZoo-based Coarse Annotation and LLM-driven Fine Annotation processes. In addition, we share the training tricks such as two-stage training and hard negative sampling. Finally, we conduct a set of offline experiments on a million-scale production dataset to evaluate our approach and deploy an A/B testing in a real online system to verify the performance. Extensive experimental results demonstrate that our proposed approach significantly outperforms existing state-of-the-art baseline methods.
Event-Centric Query Expansion in Web Search
May 30, 2023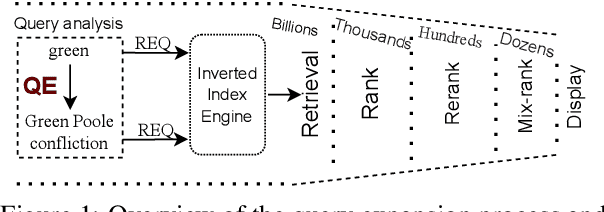
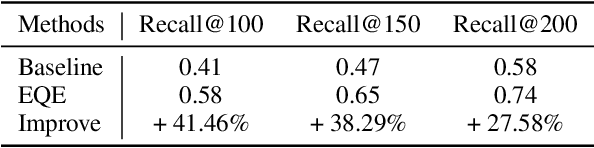
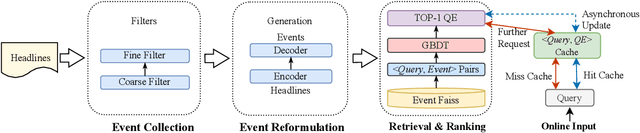

In search engines, query expansion (QE) is a crucial technique to improve search experience. Previous studies often rely on long-term search log mining, which leads to slow updates and is sub-optimal for time-sensitive news searches. In this work, we present Event-Centric Query Expansion (EQE), a novel QE system that addresses these issues by mining the best expansion from a significant amount of potential events rapidly and accurately. This system consists of four stages, i.e., event collection, event reformulation, semantic retrieval and online ranking. Specifically, we first collect and filter news headlines from websites. Then we propose a generation model that incorporates contrastive learning and prompt-tuning techniques to reformulate these headlines to concise candidates. Additionally, we fine-tune a dual-tower semantic model to function as an encoder for event retrieval and explore a two-stage contrastive training approach to enhance the accuracy of event retrieval. Finally, we rank the retrieved events and select the optimal one as QE, which is then used to improve the retrieval of event-related documents. Through offline analysis and online A/B testing, we observe that the EQE system significantly improves many metrics compared to the baseline. The system has been deployed in Tencent QQ Browser Search and served hundreds of millions of users. The dataset and baseline codes are available at https://open-event-hub.github.io/eqe .
Title2Event: Benchmarking Open Event Extraction with a Large-scale Chinese Title Dataset
Nov 02, 2022



Event extraction (EE) is crucial to downstream tasks such as new aggregation and event knowledge graph construction. Most existing EE datasets manually define fixed event types and design specific schema for each of them, failing to cover diverse events emerging from the online text. Moreover, news titles, an important source of event mentions, have not gained enough attention in current EE research. In this paper, We present Title2Event, a large-scale sentence-level dataset benchmarking Open Event Extraction without restricting event types. Title2Event contains more than 42,000 news titles in 34 topics collected from Chinese web pages. To the best of our knowledge, it is currently the largest manually-annotated Chinese dataset for open event extraction. We further conduct experiments on Title2Event with different models and show that the characteristics of titles make it challenging for event extraction, addressing the significance of advanced study on this problem. The dataset and baseline codes are available at https://open-event-hub.github.io/title2event.