 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unbiased Source-Free Object Detection via Vision Foundation Models
Jan 19, 2026Source-Free Object Detection (SFOD) has garnered much attention in recent years by eliminating the need of source-domain data in cross-domain tasks, but existing SFOD methods suffer from the Source Bias problem, i.e. the adapted model remains skewed towards the source domain, leading to poor generalization and error accumulation during self-training. To overcome this challenge, we propose Debiased Source-free Object Detection (DSOD), a novel VFM-assisted SFOD framework that can effectively mitigate source bias with the help of powerful VFMs. Specifically, we propose Unified Feature Injection (UFI) module that integrates VFM features into the CNN backbone through Simple-Scale Extension (SSE) and Domain-aware Adaptive Weighting (DAAW). Then, we propose Semantic-aware Feature Regularization (SAFR) that constrains feature learning to prevent overfitting to source domain characteristics. Furthermore, we propose a VFM-free variant, termed DSOD-distill for computation-restricted scenarios through a novel Dual-Teacher distillation scheme. Extensive experiments on multiple benchmarks demonstrate that DSOD outperforms state-of-the-art SFOD methods, achieving 48.1% AP on Normal-to-Foggy weather adaptation, 39.3% AP on Cross-scene adaptation, and 61.4% AP on Synthetic-to-Real adaptation.
OBJVanish: Physically Realizable Text-to-3D Adv. Generation of LiDAR-Invisible Objects
Oct 08, 2025LiDAR-based 3D object detectors are fundamental to autonomous driving, where failing to detect objects poses severe safety risks. Developing effective 3D adversarial attacks is essential for thoroughly testing these detection systems and exposing their vulnerabilities before real-world deployment. However, existing adversarial attacks that add optimized perturbations to 3D points have two critical limitations: they rarely cause complete object disappearance and prove difficult to implement in physical environments. We introduce the text-to-3D adversarial generation method, a novel approach enabling physically realizable attacks that can generate 3D models of objects truly invisible to LiDAR detectors and be easily realized in the real world. Specifically, we present the first empirical study that systematically investigates the factors influencing detection vulnerability by manipulating the topology, connectivity, and intensity of individual pedestrian 3D models and combining pedestrians with multiple objects within the CARLA simulation environment. Building on the insights, we propose the physically-informed text-to-3D adversarial generation (Phy3DAdvGen) that systematically optimizes text prompts by iteratively refining verbs, objects, and poses to produce LiDAR-invisible pedestrians. To ensure physical realizability, we construct a comprehensive object pool containing 13 3D models of real objects and constrain Phy3DAdvGen to generate 3D objects based on combinations of objects in this set. Extensive experiments demonstrate that our approach can generate 3D pedestrians that evade six state-of-the-art (SOTA) LiDAR 3D detectors in both CARLA simulation and physical environments, thereby highlighting vulnerabilities in safety-critical applications.
CoSDH: Communication-Efficient Collaborative Perception via Supply-Demand Awareness and Intermediate-Late Hybridization
Mar 05, 2025



Multi-agent collaborative perception enhances perceptual capabilities by utilizing information from multiple agents and is considered a fundamental solution to the problem of weak single-vehicle perception in autonomous driving. However, existing collaborative perception methods face a dilemma between communication efficiency and perception accuracy. To address this issue, we propose a novel communication-efficient collaborative perception framework based on supply-demand awareness and intermediate-late hybridization, dubbed as \mymethodname. By modeling the supply-demand relationship between agents, the framework refines the selection of collaboration regions, reducing unnecessary communication cost while maintaining accuracy. In addition, we innovatively introduce the intermediate-late hybrid collaboration mode, where late-stage collaboration compensates for the performance degradation in collaborative perception under low communication bandwidth. Extensive experiments on multiple datasets, including both simulated and real-world scenarios, demonstrate that \mymethodname~ achieves state-of-the-art detection accuracy and optimal bandwidth trade-offs, delivering superior detection precision under real communication bandwidths, thus proving its effectiveness and practical applicability. The code will be released at https://github.com/Xu2729/CoSDH.
ETimeline: An Extensive Timeline Generation Dataset based on Large Language Model
Feb 11, 2025
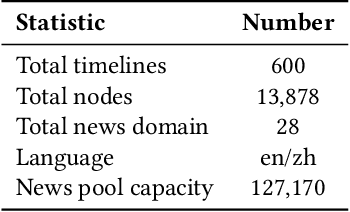
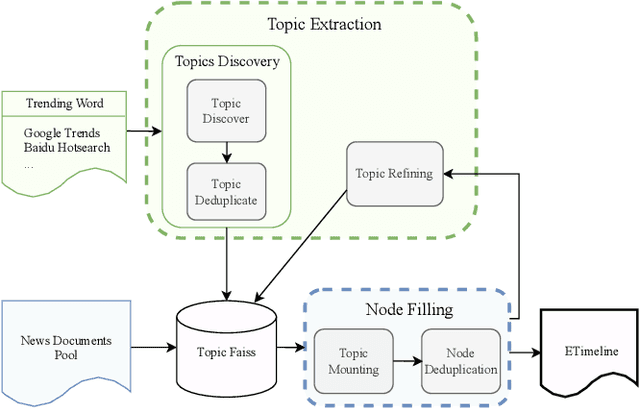

Timeline generation is of great significance for a comprehensive understanding of the development of events over time. Its goal is to organize news chronologically, which helps to identify patterns and trends that may be obscured when viewing news in isolation, making it easier to track the development of stories and understand the interrelationships between key events. Timelines are now common in various commercial products, but academic research in this area is notably scarce. Additionally, the current datasets are in need of refinement for enhanced utility and expanded coverage. In this paper, we propose ETimeline, which encompasses over $13,000$ news articles, spanning $600$ bilingual timelines across $28$ news domains. Specifically, we gather a candidate pool of more than $120,000$ news articles and employ the large language model (LLM) Pipeline to improve performance, ultimately yielding the ETimeline. The data analysis underscores the appeal of ETimeline. Additionally, we also provide the news pool data for further research and analysis. This work contributes to the advancement of timeline generation research and supports a wide range of tasks, including topic generation and event relationships. We believe that this dataset will serve as a catalyst for innovative research and bridge the gap between academia and industry in understanding the practical application of technology services. The dataset is available at https://zenodo.org/records/11392212
Breaking the SSL-AL Barrier: A Synergistic Semi-Supervised Active Learning Framework for 3D Object Detection
Jan 26, 2025



To address the annotation burden in LiDAR-based 3D object detection, active learning (AL) methods offer a promising solution. However, traditional active learning approaches solely rely on a small amount of labeled data to train an initial model for data selection, overlooking the potential of leveraging the abundance of unlabeled data. Recently, attempts to integrate semi-supervised learning (SSL) into AL with the goal of leveraging unlabeled data have faced challenges in effectively resolving the conflict between the two paradigms, resulting in less satisfactory performance. To tackle this conflict, we propose a Synergistic Semi-Supervised Active Learning framework, dubbed as S-SSAL. Specifically, from the perspective of SSL, we propose a Collaborative PseudoScene Pre-training (CPSP) method that effectively learns from unlabeled data without introducing adverse effects. From the perspective of AL, we design a Collaborative Active Learning (CAL) method, which complements the uncertainty and diversity methods by model cascading. This allows us to fully exploit the potential of the CPSP pre-trained model. Extensive experiments conducted on KITTI and Waymo demonstrate the effectiveness of our S-SSAL framework. Notably, on the KITTI dataset, utilizing only 2% labeled data, S-SSAL can achieve performance comparable to models trained on the full dataset.
Breaking the Stigma! Unobtrusively Probe Symptoms in Depression Disorder Diagnosis Dialogue
Jan 25, 2025



Stigma has emerged as one of the major obstacles to effectively diagnosing depression, as it prevents users from open conversations about their struggles. This requires advanced questioning skills to carefully probe the presence of specific symptoms in an unobtrusive manner. While recent efforts have been made on depression-diagnosis-oriented dialogue systems, they largely ignore this problem, ultimately hampering their practical utility. To this end, we propose a novel and effective method, UPSD$^{4}$, developing a series of strategies to promote a sense of unobtrusiveness within the dialogue system and assessing depression disorder by probing symptoms. We experimentally show that UPSD$^{4}$ demonstrates a significant improvement over current baselines, including unobtrusiveness evaluation of dialogue content and diagnostic accuracy. We believe our work contributes to developing more accessible and user-friendly tools for addressing the widespread need for depression diagnosis.
PACF: Prototype Augmented Compact Features for Improving Domain Adaptive Object Detection
Jan 15, 2025In recent years, there has been significant advancement in object detection. However, applying off-the-shelf detectors to a new domain leads to significant performance drop, caused by the domain gap. These detectors exhibit higher-variance class-conditional distributions in the target domain than that in the source domain, along with mean shift. To address this problem, we propose the Prototype Augmented Compact Features (PACF) framework to regularize the distribution of intra-class features. Specifically, we provide an in-depth theoretical analysis on the lower bound of the target features-related likelihood and derive the prototype cross entropy loss to further calibrate the distribution of target RoI features. Furthermore, a mutual regularization strategy is designed to enable the linear and prototype-based classifiers to learn from each other, promoting feature compactness while enhancing discriminability. Thanks to this PACF framework, we have obtained a more compact cross-domain feature space, within which the variance of the target features' class-conditional distributions has significantly decreased, and the class-mean shift between the two domains has also been further reduced. The results on different adaptation settings are state-of-the-art, which demonstrate the board applicability and effectiveness of the proposed approach.
SpecFuse: Ensembling Large Language Models via Next-Segment Prediction
Dec 10, 2024



Ensembles of generative large language models (LLMs) can integrate the strengths of different LLMs to compensate for the limitations of individual models. However, recent work has focused on training an additional fusion model to combine complete responses from multiple LLMs, failing to tap into their collaborative potential to generate higher-quality responses. Moreover, as the additional fusion model is trained on a specialized dataset, these methods struggle with generalizing to open-domain queries from online users. In this paper, we propose SpecFuse, a novel ensemble framework that outputs the fused result by iteratively producing the next segment through collaboration among LLMs. This is achieved through cyclic execution of its inference and verification components. In each round, the inference component invokes each base LLM to generate candidate segments in parallel, and the verify component calls these LLMs again to predict the ranking of the segments. The top-ranked segment is then broadcast to all LLMs, encouraging them to generate higher-quality segments in the next round. This approach also allows the base LLMs to be plug-and-play, without any training or adaptation, avoiding generalization limitations. Furthermore, to conserve computational resources, we propose a model exit mechanism that dynamically excludes models exhibiting poor performance in previous rounds during each query response. In this way, it effectively reduces the number of model calls while maintaining overall performance.
Lightweight Spatial Embedding for Vision-based 3D Occupancy Prediction
Dec 08, 2024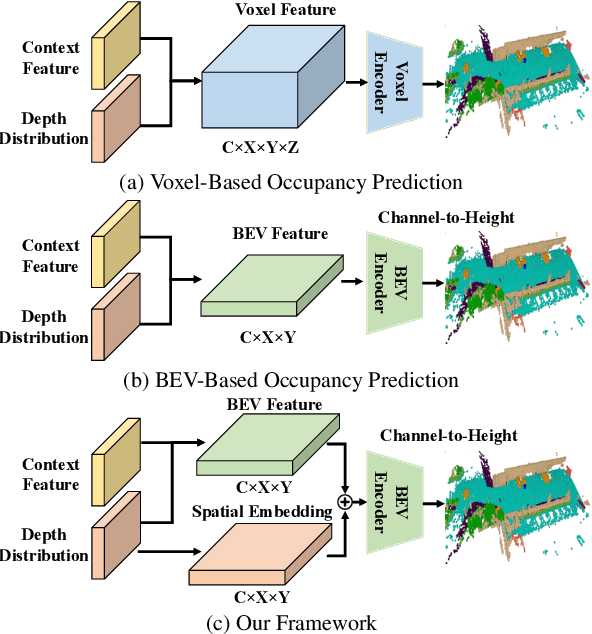
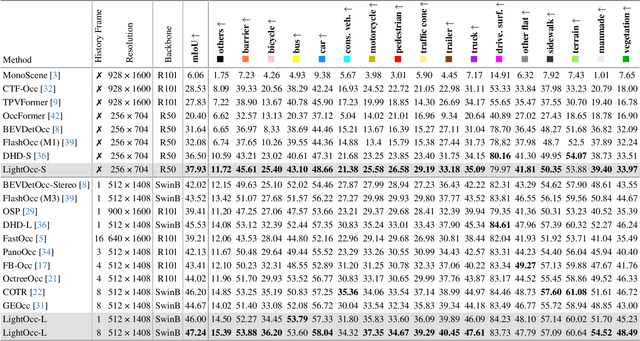
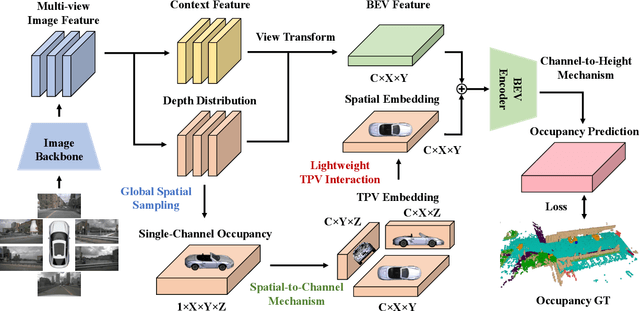
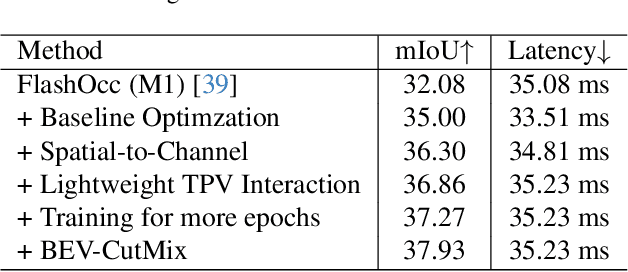
Occupancy prediction has garnered increasing attention in recent years for its comprehensive fine-grained environmental representation and strong generalization to open-set objects. However, cumbersome voxel features and 3D convolution operations inevitably introduce large overheads in both memory and computation, obstructing the deployment of occupancy prediction approaches in real-time autonomous driving systems. Although some methods attempt to efficiently predict 3D occupancy from 2D Bird's-Eye-View (BEV) features through the Channel-to-Height mechanism, BEV features are insufficient to store all the height information of the scene, which limits performance. This paper proposes LightOcc, an innovative 3D occupancy prediction framework that leverages Lightweight Spatial Embedding to effectively supplement the height clues for the BEV-based representation while maintaining its deployability. Firstly, Global Spatial Sampling is used to obtain the Single-Channel Occupancy from multi-view depth distribution. Spatial-to-Channel mechanism then takes the arbitrary spatial dimension of Single-Channel Occupancy as the feature dimension and extracts Tri-Perspective Views (TPV) Embeddings by 2D convolution. Finally, TPV Embeddings will interact with each other by Lightweight TPV Interaction module to obtain the Spatial Embedding that is optimal supplementary to BEV features. Sufficient experimental results show that LightOcc significantly increases the prediction accuracy of the baseline and achieves state-of-the-art performance on the Occ3D-nuScenes benchmark.
Centerness-based Instance-aware Knowledge Distillation with Task-wise Mutual Lifting for Object Detection on Drone Imagery
Nov 05, 2024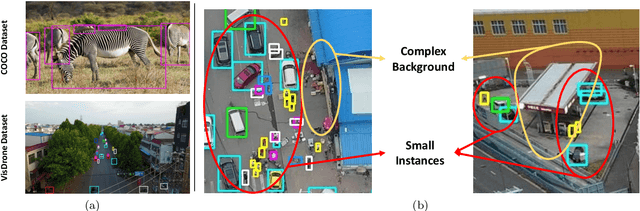
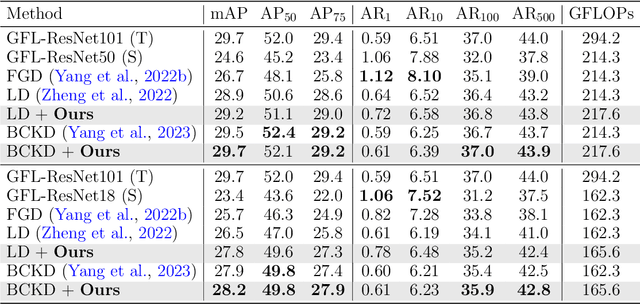
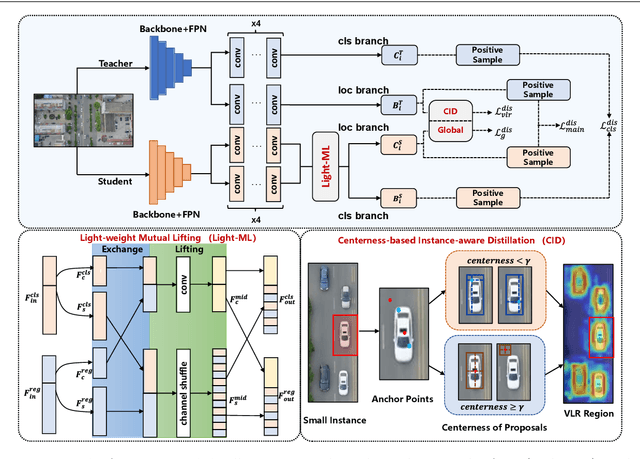
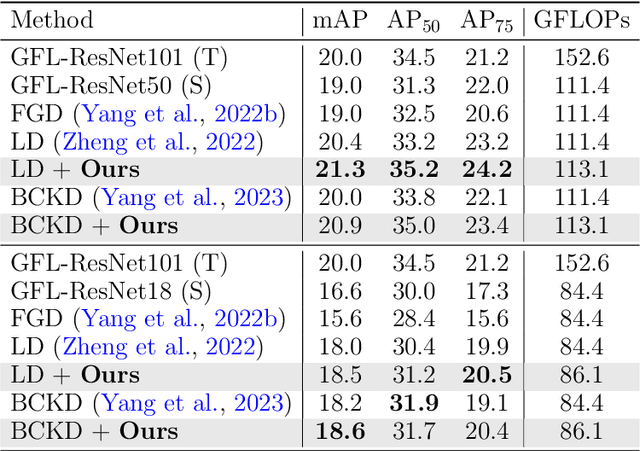
Developing accurate and efficient detectors for drone imagery is challenging due to the inherent complexity of aerial scenes. While some existing methods aim to achieve high accuracy by utilizing larger models, their computational cost is prohibitive for drones. Recently, Knowledge Distillation (KD) has shown promising potential for maintaining satisfactory accuracy while significantly compressing models in general object detection. Considering the advantages of KD, this paper presents the first attempt to adapt it to object detection on drone imagery and addresses two intrinsic issues: (1) low foreground-background ratio and (2) small instances and complex backgrounds, which lead to inadequate training, resulting insufficient distillation. Therefore, we propose a task-wise Lightweight Mutual Lifting (Light-ML) module with a Centerness-based Instance-aware Distillation (CID) strategy. The Light-ML module mutually harmonizes the classification and localization branches by channel shuffling and convolution, integrating teacher supervision across different tasks during back-propagation, thus facilitating training the student model. The CID strategy extracts valuable regions surrounding instances through the centerness of proposals, enhancing distillation efficacy. Experiments on the VisDrone, UAVDT, and COCO benchmarks demonstrate that the proposed approach promotes the accuracies of existing state-of-the-art KD methods with comparable computational requirements. Codes will be available upon acceptance.