 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Self-Training Based Cross-Subject Domain Adaptation for SSVEP Classification
Jan 29, 2026Steady-state visually evoked potentials (SSVEP)-based brain-computer interfaces (BCIs) are widely used due to their high signal-to-noise ratio and user-friendliness. Accurate decoding of SSVEP signals is crucial for interpreting user intentions in BCI applications. However, signal variability across subjects and the costly user-specific annotation limit recognition performance. Therefore, we propose a novel cross-subject domain adaptation method built upon the self-training paradigm. Specifically, a Filter-Bank Euclidean Alignment (FBEA) strategy is designed to exploit frequency information from SSVEP filter banks. Then, we propose a Cross-Subject Self-Training (CSST) framework consisting of two stages: Pre-Training with Adversarial Learning (PTAL), which aligns the source and target distributions, and Dual-Ensemble Self-Training (DEST), which refines pseudo-label quality. Moreover, we introduce a Time-Frequency Augmented Contrastive Learning (TFA-CL) module to enhance feature discriminability across multiple augmented views. Extensive experiments on the Benchmark and BETA datasets demonstrate that our approach achieves state-of-the-art performance across varying signal lengths, highlighting its superiority.
Towards Unbiased Source-Free Object Detection via Vision Foundation Models
Jan 19, 2026Source-Free Object Detection (SFOD) has garnered much attention in recent years by eliminating the need of source-domain data in cross-domain tasks, but existing SFOD methods suffer from the Source Bias problem, i.e. the adapted model remains skewed towards the source domain, leading to poor generalization and error accumulation during self-training. To overcome this challenge, we propose Debiased Source-free Object Detection (DSOD), a novel VFM-assisted SFOD framework that can effectively mitigate source bias with the help of powerful VFMs. Specifically, we propose Unified Feature Injection (UFI) module that integrates VFM features into the CNN backbone through Simple-Scale Extension (SSE) and Domain-aware Adaptive Weighting (DAAW). Then, we propose Semantic-aware Feature Regularization (SAFR) that constrains feature learning to prevent overfitting to source domain characteristics. Furthermore, we propose a VFM-free variant, termed DSOD-distill for computation-restricted scenarios through a novel Dual-Teacher distillation scheme. Extensive experiments on multiple benchmarks demonstrate that DSOD outperforms state-of-the-art SFOD methods, achieving 48.1% AP on Normal-to-Foggy weather adaptation, 39.3% AP on Cross-scene adaptation, and 61.4% AP on Synthetic-to-Real adaptation.
PS-TTL: Prototype-based Soft-labels and Test-Time Learning for Few-shot Object Detection
Aug 11, 2024In recent years, Few-Shot Object Detection (FSOD) has gained widespread attention and made significant progress due to its ability to build models with a good generalization power using extremely limited annotated data. The fine-tuning based paradigm is currently dominating this field, where detectors are initially pre-trained on base classes with sufficient samples and then fine-tuned on novel ones with few samples, but the scarcity of labeled samples of novel classes greatly interferes precisely fitting their data distribution, thus hampering the performance. To address this issue, we propose a new framework for FSOD, namely Prototype-based Soft-labels and Test-Time Learning (PS-TTL). Specifically, we design a Test-Time Learning (TTL) module that employs a mean-teacher network for self-training to discover novel instances from test data, allowing detectors to learn better representations and classifiers for novel classes. Furthermore, we notice that even though relatively low-confidence pseudo-labels exhibit classification confusion, they still tend to recall foreground. We thus develop a Prototype-based Soft-labels (PS) strategy through assessing similarities between low-confidence pseudo-labels and category prototypes as soft-labels to unleash their potential, which substantially mitigates the constraints posed by few-shot samples. Extensive experiments on both the VOC and COCO benchmarks show that PS-TTL achieves the state-of-the-art, highlighting its effectiveness. The code and model are available at https://github.com/gaoyingjay/PS-TTL.
Crowd-SAM: SAM as a Smart Annotator for Object Detection in Crowded Scenes
Jul 16, 2024

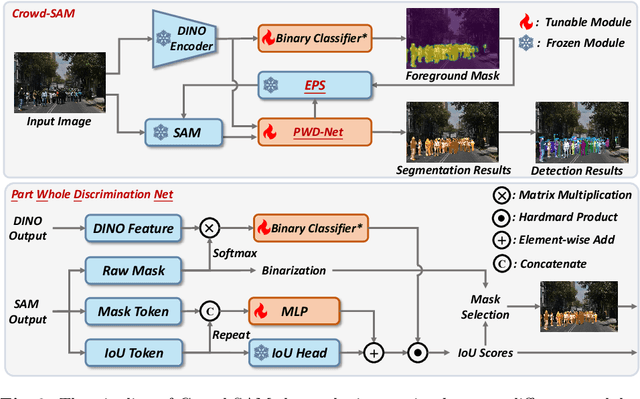

In computer vision, object detection is an important task that finds its application in many scenarios. However, obtaining extensive labels can be challenging, especially in crowded scenes. Recently, the Segment Anything Model (SAM) has been proposed as a powerful zero-shot segmenter, offering a novel approach to instance segmentation tasks. However, the accuracy and efficiency of SAM and its variants are often compromised when handling objects in crowded and occluded scenes. In this paper, we introduce Crowd-SAM, a SAM-based framework designed to enhance SAM's performance in crowded and occluded scenes with the cost of few learnable parameters and minimal labeled images. We introduce an efficient prompt sampler (EPS) and a part-whole discrimination network (PWD-Net), enhancing mask selection and accuracy in crowded scenes. Despite its simplicity, Crowd-SAM rivals state-of-the-art (SOTA) fully-supervised object detection methods on several benchmarks including CrowdHuman and CityPersons. Our code is available at https://github.com/FelixCaae/CrowdSAM.
Semantic Enhanced Few-shot Object Detection
Jun 19, 2024



Few-shot object detection~(FSOD), which aims to detect novel objects with limited annotated instances, has made significant progress in recent years. However, existing methods still suffer from biased representations, especially for novel classes in extremely low-shot scenarios. During fine-tuning, a novel class may exploit knowledge from similar base classes to construct its own feature distribution, leading to classification confusion and performance degradation. To address these challenges, we propose a fine-tuning based FSOD framework that utilizes semantic embeddings for better detection. In our proposed method, we align the visual features with class name embeddings and replace the linear classifier with our semantic similarity classifier. Our method trains each region proposal to converge to the corresponding class embedding. Furthermore, we introduce a multimodal feature fusion to augment the vision-language communication, enabling a novel class to draw support explicitly from well-trained similar base classes. To prevent class confusion, we propose a semantic-aware max-margin loss, which adaptively applies a margin beyond similar classes. As a result, our method allows each novel class to construct a compact feature space without being confused with similar base classes. Extensive experiments on Pascal VOC and MS COCO demonstrate the superiority of our method.
DUA-DA: Distillation-based Unbiased Alignment for Domain Adaptive Object Detection
Nov 17, 2023
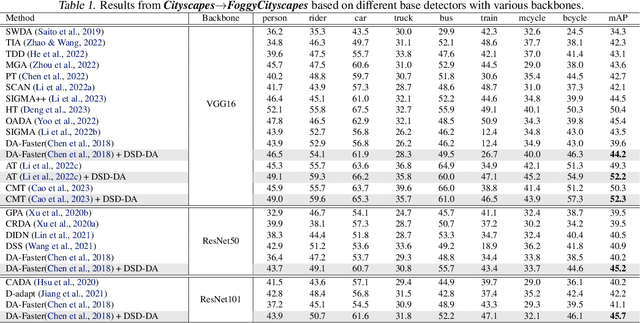
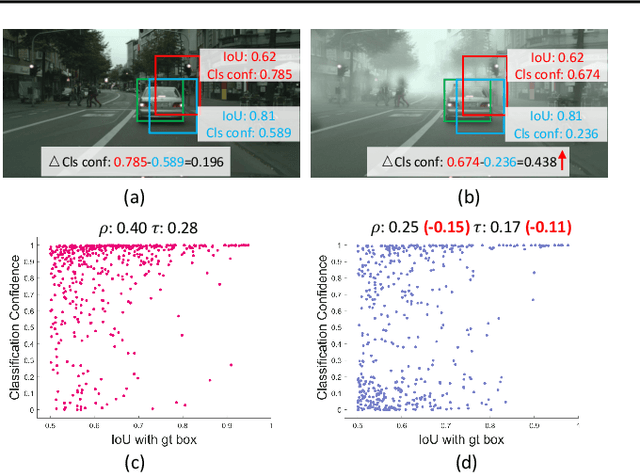
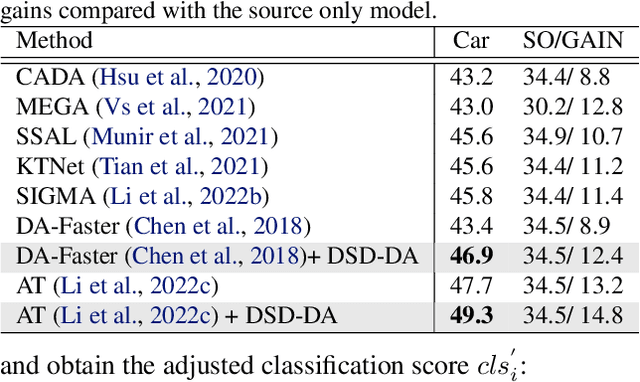
Though feature-alignment based Domain Adaptive Object Detection (DAOD) have achieved remarkable progress, they ignore the source bias issue, i.e. the aligned features are more favorable towards the source domain, leading to a sub-optimal adaptation. Furthermore, the presence of domain shift between the source and target domains exacerbates the problem of inconsistent classification and localization in general detection pipelines. To overcome these challenges, we propose a novel Distillation-based Unbiased Alignment (DUA) framework for DAOD, which can distill the source features towards a more balanced position via a pre-trained teacher model during the training process, alleviating the problem of source bias effectively. In addition, we design a Target-Relevant Object Localization Network (TROLN), which can mine target-related knowledge to produce two classification-free metrics (IoU and centerness). Accordingly, we implement a Domain-aware Consistency Enhancing (DCE) strategy that utilizes these two metrics to further refine classification confidences, achieving a harmonization between classification and localization in cross-domain scenarios. Extensive experiments have been conducted to manifest the effectiveness of this method, which consistently improves the strong baseline by large margins, outperforming existing alignment-based works.
Semi-Supervised Object Detection with Uncurated Unlabeled Data for Remote Sensing Images
Oct 09, 2023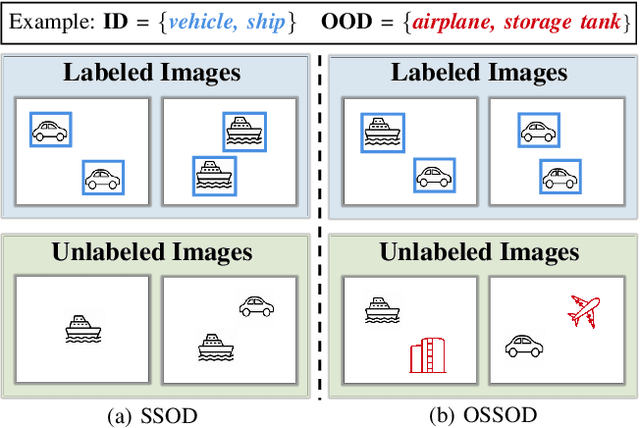

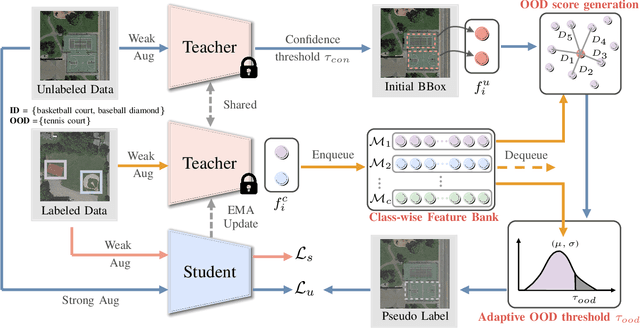
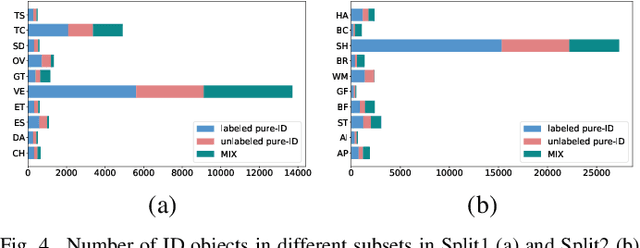
Annotating remote sensing images (RSIs) presents a notable challenge due to its labor-intensive nature. Semi-supervised object detection (SSOD) methods tackle this issue by generating pseudo-labels for the unlabeled data, assuming that all classes found in the unlabeled dataset are also represented in the labeled data. However, real-world situations introduce the possibility of out-of-distribution (OOD) samples being mixed with in-distribution (ID) samples within the unlabeled dataset. In this paper, we delve into techniques for conducting SSOD directly on uncurated unlabeled data, which is termed Open-Set Semi-Supervised Object Detection (OSSOD). Our approach commences by employing labeled in-distribution data to dynamically construct a class-wise feature bank (CFB) that captures features specific to each class. Subsequently, we compare the features of predicted object bounding boxes with the corresponding entries in the CFB to calculate OOD scores. We design an adaptive threshold based on the statistical properties of the CFB, allowing us to filter out OOD samples effectively. The effectiveness of our proposed method is substantiated through extensive experiments on two widely used remote sensing object detection datasets: DIOR and DOTA. These experiments showcase the superior performance and efficacy of our approach for OSSOD on RSIs.