 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of the generalization error for deep gradient flow methods for PDEs
Dec 31, 2025The aim of this article is to provide a firm mathematical foundation for the application of deep gradient flow methods (DGFMs) for the solution of (high-dimensional) partial differential equations (PDEs). We decompose the generalization error of DGFMs into an approximation and a training error. We first show that the solution of PDEs that satisfy reasonable and verifiable assumptions can be approximated by neural networks, thus the approximation error tends to zero as the number of neurons tends to infinity. Then, we derive the gradient flow that the training process follows in the ``wide network limit'' and analyze the limit of this flow as the training time tends to infinity. These results combined show that the generalization error of DGFMs tends to zero as the number of neurons and the training time tend to infinity.
POEv2: a flexible and robust framework for generic line segment detection and wireframe line segment detection
Aug 27, 2025Line segment detection in images has been studied for several decades. Existing line segment detectors can be roughly divided into two categories: generic line segment detectors and wireframe line segment detectors. Generic line segment detectors aim to detect all meaningful line segments in images and traditional approaches usually fall into this category. Recent deep learning based approaches are mostly wireframe line segment detectors. They detect only line segments that are geometrically meaningful and have large spatial support. Due to the difference in the aim of design, the performance of generic line segment detectors for the task of wireframe line segment detection won't be satisfactory, and vice versa. In this work, we propose a robust framework that can be used for both generic line segment detection and wireframe line segment detection. The proposed method is an improved version of the Pixel Orientation Estimation (POE) method. It is thus named as POEv2. POEv2 detects line segments from edge strength maps, and can be combined with any edge detector. We show in our experiments that by combining the proposed POEv2 with an efficient edge detector, it achieves state-of-the-art performance on three publicly available datasets.
Coop-WD: Cooperative Perception with Weighting and Denoising for Robust V2V Communication
May 06, 2025Cooperative perception, leveraging shared information from multiple vehicles via vehicle-to-vehicle (V2V) communication, plays a vital role in autonomous driving to alleviate the limitation of single-vehicle perception. Existing works have explored the effects of V2V communication impairments on perception precision, but they lack generalization to different levels of impairments. In this work, we propose a joint weighting and denoising framework, Coop-WD, to enhance cooperative perception subject to V2V channel impairments. In this framework, the self-supervised contrastive model and the conditional diffusion probabilistic model are adopted hierarchically for vehicle-level and pixel-level feature enhancement. An efficient variant model, Coop-WD-eco, is proposed to selectively deactivate denoising to reduce processing overhead. Rician fading, non-stationarity, and time-varying distortion are considered. Simulation results demonstrate that the proposed Coop-WD outperforms conventional benchmarks in all types of channels. Qualitative analysis with visual examples further proves the superiority of our proposed method. The proposed Coop-WD-eco achieves up to 50% reduction in computational cost under severe distortion while maintaining comparable accuracy as channel conditions improve.
Vision-Language Model for Object Detection and Segmentation: A Review and Evaluation
Apr 13, 2025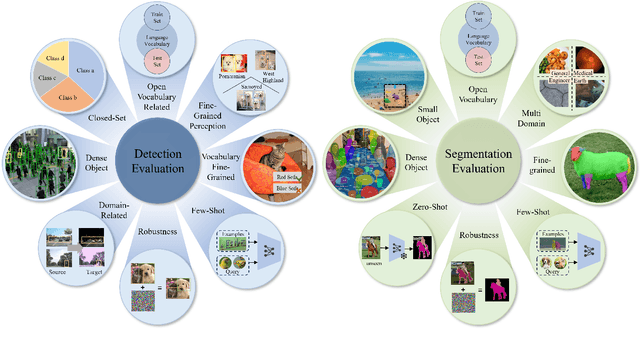
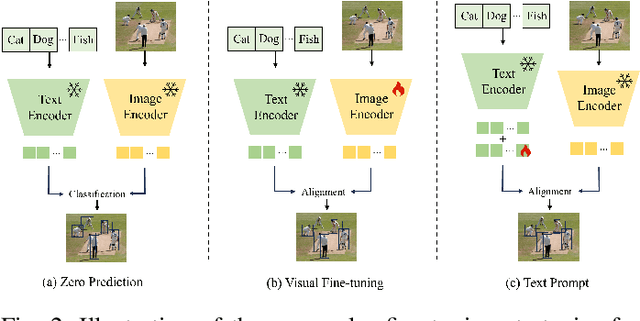
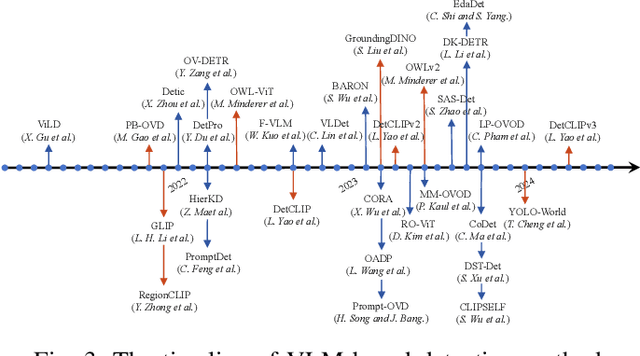
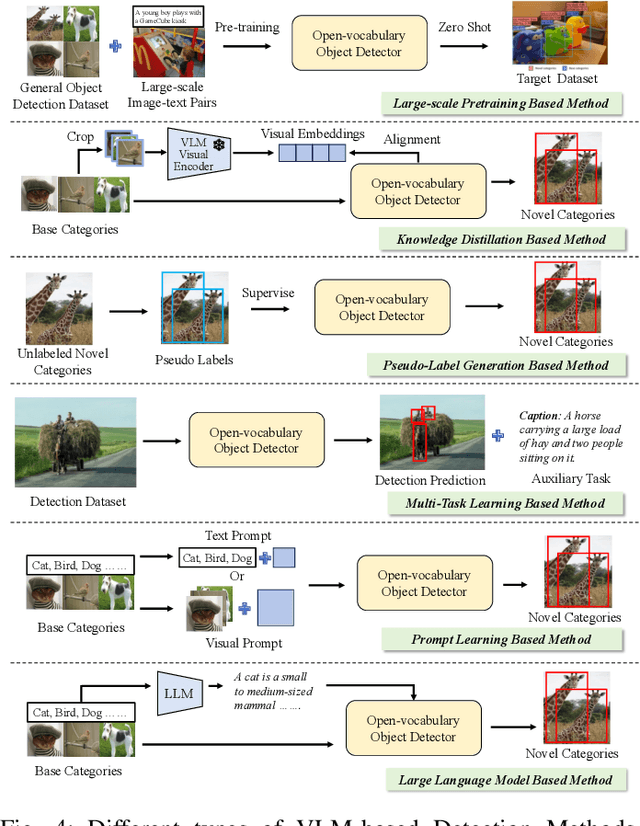
Vision-Language Model (VLM) have gained widespread adoption in Open-Vocabulary (OV) object detection and segmentation tasks. Despite they have shown promise on OV-related tasks, their effectiveness in conventional vision tasks has thus far been unevaluated. In this work, we present the systematic review of VLM-based detection and segmentation, view VLM as the foundational model and conduct comprehensive evaluations across multiple downstream tasks for the first time: 1) The evaluation spans eight detection scenarios (closed-set detection, domain adaptation, crowded objects, etc.) and eight segmentation scenarios (few-shot, open-world, small object, etc.), revealing distinct performance advantages and limitations of various VLM architectures across tasks. 2) As for detection tasks, we evaluate VLMs under three finetuning granularities: \textit{zero prediction}, \textit{visual fine-tuning}, and \textit{text prompt}, and further analyze how different finetuning strategies impact performance under varied task. 3) Based on empirical findings, we provide in-depth analysis of the correlations between task characteristics, model architectures, and training methodologies, offering insights for future VLM design. 4) We believe that this work shall be valuable to the pattern recognition experts working in the fields of computer vision, multimodal learning, and vision foundation models by introducing them to the problem, and familiarizing them with the current status of the progress while providing promising directions for future research. A project associated with this review and evaluation has been created at https://github.com/better-chao/perceptual_abilities_evaluation.
Integrated Sensing, Communication, and Over-The-Air Control of UAV Swarm Dynamics
Feb 11, 2025Coordinated controlling a large UAV swarm requires significant spectrum resources due to the need for bandwidth allocation per UAV, posing a challenge in resource-limited environments. Over-the-air (OTA) control has emerged as a spectrum-efficient approach, leveraging electromagnetic superposition to form control signals at a base station (BS). However, existing OTA controllers lack sufficient optimization variables to meet UAV swarm control objectives and fail to integrate control with other BS functions like sensing. This work proposes an integrated sensing and OTA control framework (ISAC-OTA) for UAV swarm. The BS performs OTA signal construction (uplink) and dispatch (downlink) while simultaneously sensing objects. Two uplink post-processing methods are developed: a control-centric approach generating closed-form control signals via a feedback-looped OTA control problem, and a sensing-centric method mitigating transmission-induced interference for accurate object sensing. For the downlink, a non-convex problem is formulated and solved to minimize control signal dispatch (transmission) error while maintaining a minimum sensing signal-to-noise ratio (SNR). Simulation results show that the proposed ISAC-OTA controller achieves control performance comparable to the benchmark optimal control algorithm while maintaining high sensing accuracy, despite OTA transmission interference. Moreover, it eliminates the need for per-UAV bandwidth allocation, showcasing a spectrum-efficient method for cooperative control in future wireless systems.
PACF: Prototype Augmented Compact Features for Improving Domain Adaptive Object Detection
Jan 15, 2025In recent years, there has been significant advancement in object detection. However, applying off-the-shelf detectors to a new domain leads to significant performance drop, caused by the domain gap. These detectors exhibit higher-variance class-conditional distributions in the target domain than that in the source domain, along with mean shift. To address this problem, we propose the Prototype Augmented Compact Features (PACF) framework to regularize the distribution of intra-class features. Specifically, we provide an in-depth theoretical analysis on the lower bound of the target features-related likelihood and derive the prototype cross entropy loss to further calibrate the distribution of target RoI features. Furthermore, a mutual regularization strategy is designed to enable the linear and prototype-based classifiers to learn from each other, promoting feature compactness while enhancing discriminability. Thanks to this PACF framework, we have obtained a more compact cross-domain feature space, within which the variance of the target features' class-conditional distributions has significantly decreased, and the class-mean shift between the two domains has also been further reduced. The results on different adaptation settings are state-of-the-art, which demonstrate the board applicability and effectiveness of the proposed approach.
How to beat a Bayesian adversary
Jul 11, 2024



Deep neural networks and other modern machine learning models are often susceptible to adversarial attacks. Indeed, an adversary may often be able to change a model's prediction through a small, directed perturbation of the model's input - an issue in safety-critical applications. Adversarially robust machine learning is usually based on a minmax optimisation problem that minimises the machine learning loss under maximisation-based adversarial attacks. In this work, we study adversaries that determine their attack using a Bayesian statistical approach rather than maximisation. The resulting Bayesian adversarial robustness problem is a relaxation of the usual minmax problem. To solve this problem, we propose Abram - a continuous-time particle system that shall approximate the gradient flow corresponding to the underlying learning problem. We show that Abram approximates a McKean-Vlasov process and justify the use of Abram by giving assumptions under which the McKean-Vlasov process finds the minimiser of the Bayesian adversarial robustness problem. We discuss two ways to discretise Abram and show its suitability in benchmark adversarial deep learning experiments.
YOLC: You Only Look Clusters for Tiny Object Detection in Aerial Images
Apr 09, 2024



Detecting objects from aerial images poses significant challenges due to the following factors: 1) Aerial images typically have very large sizes, generally with millions or even hundreds of millions of pixels, while computational resources are limited. 2) Small object size leads to insufficient information for effective detection. 3) Non-uniform object distribution leads to computational resource wastage. To address these issues, we propose YOLC (You Only Look Clusters), an efficient and effective framework that builds on an anchor-free object detector, CenterNet. To overcome the challenges posed by large-scale images and non-uniform object distribution, we introduce a Local Scale Module (LSM) that adaptively searches cluster regions for zooming in for accurate detection. Additionally, we modify the regression loss using Gaussian Wasserstein distance (GWD) to obtain high-quality bounding boxes. Deformable convolution and refinement methods are employed in the detection head to enhance the detection of small objects. We perform extensive experiments on two aerial image datasets, including Visdrone2019 and UAVDT, to demonstrate the effectiveness and superiority of our proposed approach.
Msmsfnet: a multi-stream and multi-scale fusion net for edge detection
Apr 07, 2024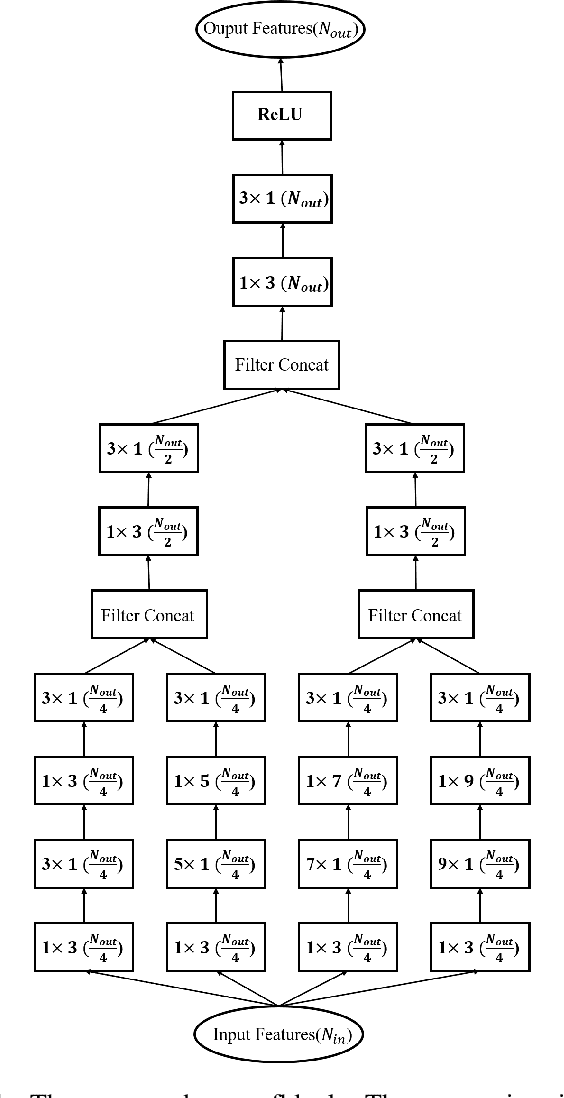



Edge detection is a long standing problem in computer vision. Recent deep learning based algorithms achieve state of-the-art performance in publicly available datasets. Despite the efficiency of these algorithms, their performance, however, relies heavily on the pretrained weights of the backbone network on the ImageNet dataset. This limits heavily the design space of deep learning based edge detectors. Whenever we want to devise a new model, we have to train this new model on the ImageNet dataset first, and then fine tune the model using the edge detection datasets. The comparison would be unfair otherwise. However, it is usually not feasible for many researchers to train a model on the ImageNet dataset due to the limited computation resources. In this work, we study the performance that can be achieved by state-of-the-art deep learning based edge detectors in publicly available datasets when they are trained from scratch, and devise a new network architecture, the multi-stream and multi scale fusion net (msmsfnet), for edge detection. We show in our experiments that by training all models from scratch to ensure the fairness of comparison, out model outperforms state-of-the art deep learning based edge detectors in three publicly available datasets.
Self-supervised Adaptive Weighting for Cooperative Perception in V2V Communications
Dec 16, 2023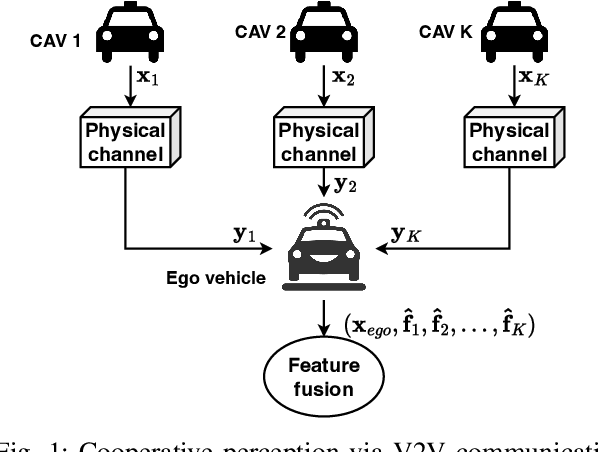
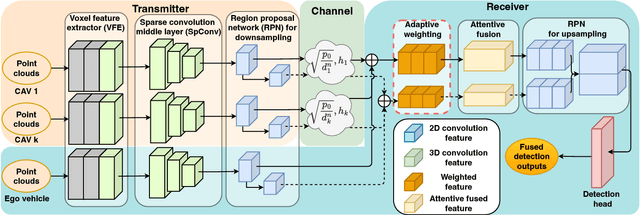
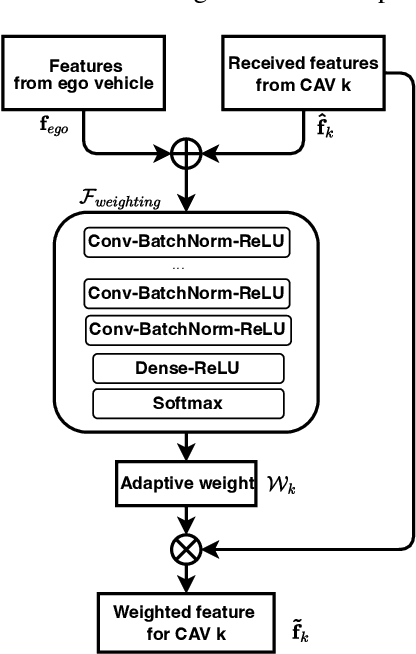
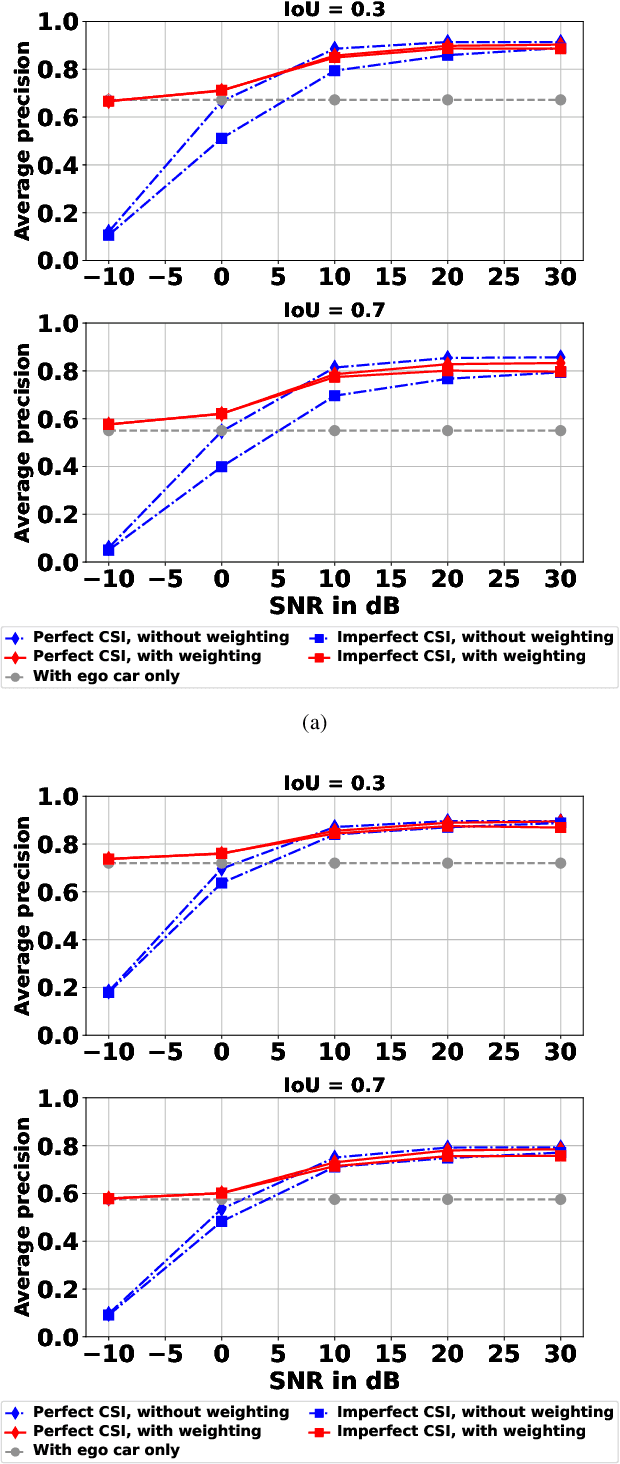
Perception of the driving environment is critical for collision avoidance and route planning to ensure driving safety. Cooperative perception has been widely studied as an effective approach to addressing the shortcomings of single-vehicle perception. However, the practical limitations of vehicle-to-vehicle (V2V) communications have not been adequately investigated. In particular, current cooperative fusion models rely on supervised models and do not address dynamic performance degradation caused by arbitrary channel impairments. In this paper, a self-supervised adaptive weighting model is proposed for intermediate fusion to mitigate the adverse effects of channel distortion. The performance of cooperative perception is investigated in different system settings. Rician fading and imperfect channel state information (CSI) are also considered. Numerical results demonstrate that the proposed adaptive weighting algorithm significantly outperforms the benchmarks without weighting. Visualization examples validate that the proposed weighting algorithm can flexibly adapt to various channel conditions. Moreover, the adaptive weighting algorithm demonstrates good generalization to untrained channels and test datasets from different domains.