 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Model for Object Detection and Segmentation: A Review and Evaluation
Apr 13, 2025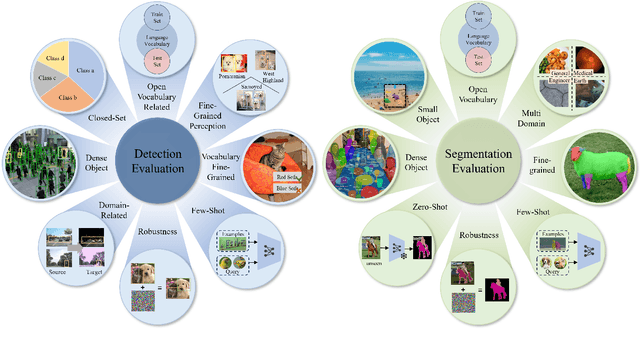
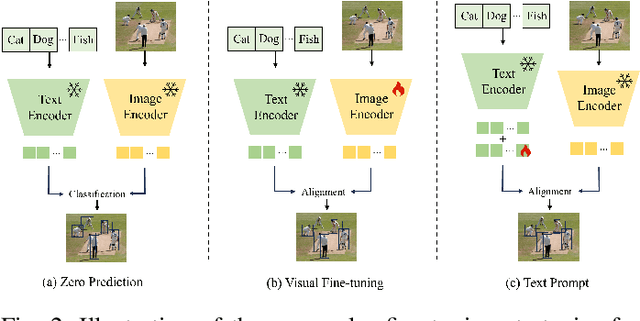
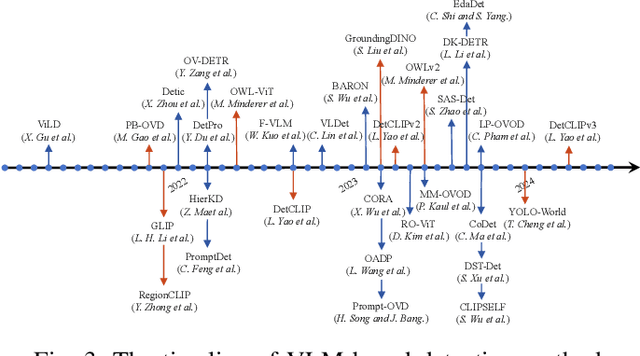
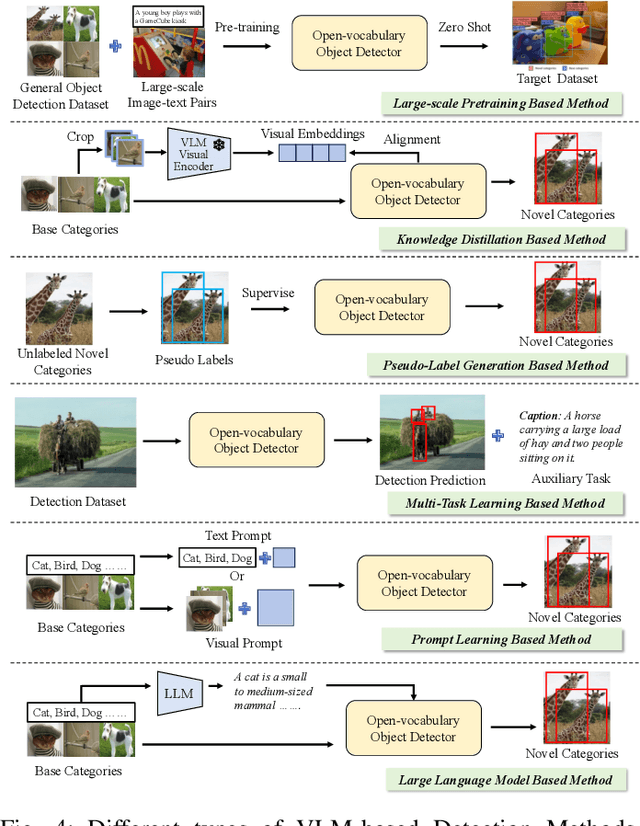
Vision-Language Model (VLM) have gained widespread adoption in Open-Vocabulary (OV) object detection and segmentation tasks. Despite they have shown promise on OV-related tasks, their effectiveness in conventional vision tasks has thus far been unevaluated. In this work, we present the systematic review of VLM-based detection and segmentation, view VLM as the foundational model and conduct comprehensive evaluations across multiple downstream tasks for the first time: 1) The evaluation spans eight detection scenarios (closed-set detection, domain adaptation, crowded objects, etc.) and eight segmentation scenarios (few-shot, open-world, small object, etc.), revealing distinct performance advantages and limitations of various VLM architectures across tasks. 2) As for detection tasks, we evaluate VLMs under three finetuning granularities: \textit{zero prediction}, \textit{visual fine-tuning}, and \textit{text prompt}, and further analyze how different finetuning strategies impact performance under varied task. 3) Based on empirical findings, we provide in-depth analysis of the correlations between task characteristics, model architectures, and training methodologies, offering insights for future VLM design. 4) We believe that this work shall be valuable to the pattern recognition experts working in the fields of computer vision, multimodal learning, and vision foundation models by introducing them to the problem, and familiarizing them with the current status of the progress while providing promising directions for future research. A project associated with this review and evaluation has been created at https://github.com/better-chao/perceptual_abilities_evaluation.
A Survey on Remote Sensing Foundation Models: From Vision to Multimodality
Mar 28, 2025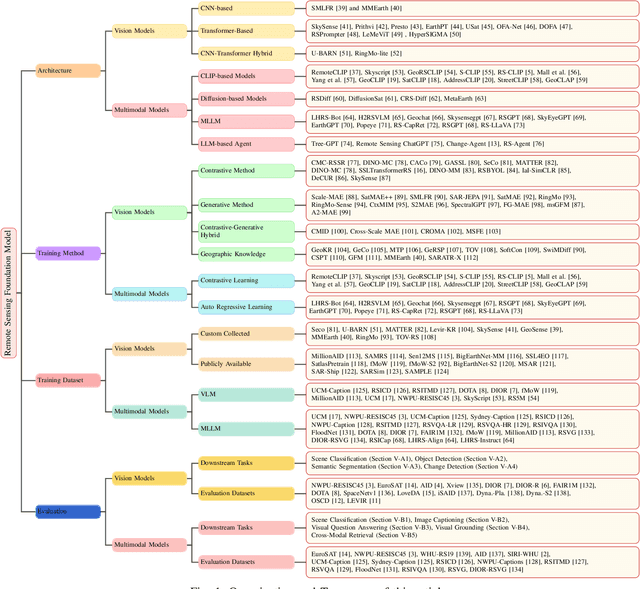
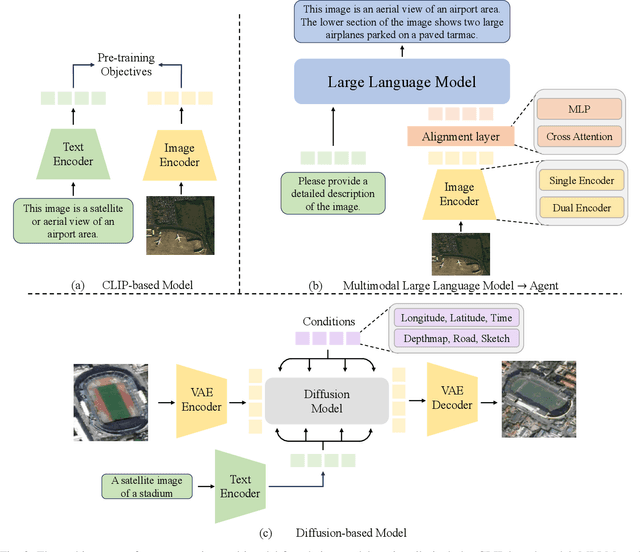

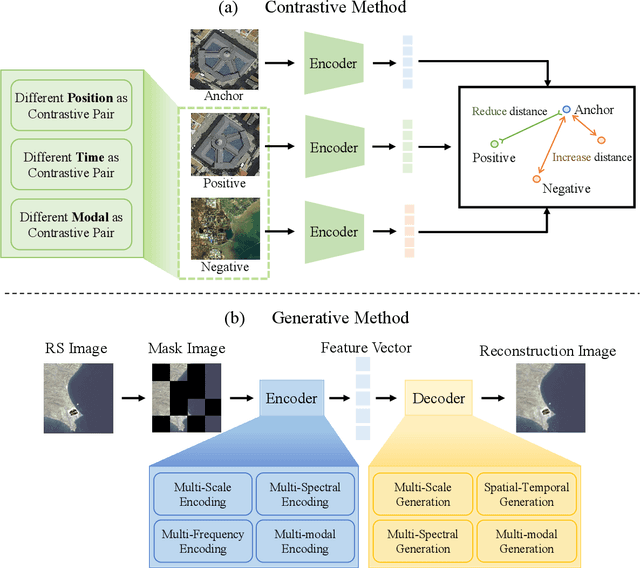
The rapid advancement of remote sensing foundation models, particularly vision and multimodal models, has significantly enhanced the capabilities of intelligent geospatial data interpretation. These models combine various data modalities, such as optical, radar, and LiDAR imagery, with textual and geographic information, enabling more comprehensive analysis and understanding of remote sensing data. The integration of multiple modalities allows for improved performance in tasks like object detection, land cover classification, and change detection, which are often challenged by the complex and heterogeneous nature of remote sensing data. However, despite these advancements, several challenges remain. The diversity in data types, the need for large-scale annotated datasets, and the complexity of multimodal fusion techniques pose significant obstacles to the effective deployment of these models. Moreover, the computational demands of training and fine-tuning multimodal models require significant resources, further complicating their practical application in remote sensing image interpretation tasks. This paper provides a comprehensive review of the state-of-the-art in vision and multimodal foundation models for remote sensing, focusing on their architecture, training methods, datasets and application scenarios. We discuss the key challenges these models face, such as data alignment, cross-modal transfer learning, and scalability, while also identifying emerging research directions aimed at overcoming these limitations. Our goal is to provide a clear understanding of the current landscape of remote sensing foundation models and inspire future research that can push the boundaries of what these models can achieve in real-world applications. The list of resources collected by the paper can be found in the https://github.com/IRIP-BUAA/A-Review-for-remote-sensing-vision-language-models.
A Survey on Data Synthesis and Augmentation for Large Language Models
Oct 16, 2024The success of Large Language Models (LLMs) is inherently linked to the availability of vast, diverse, and high-quality data for training and evaluation. However, the growth rate of high-quality data is significantly outpaced by the expansion of training datasets, leading to a looming data exhaustion crisis. This underscores the urgent need to enhance data efficiency and explore new data sources. In this context, synthetic data has emerged as a promising solution. Currently, data generation primarily consists of two major approaches: data augmentation and synthesis. This paper comprehensively reviews and summarizes data generation techniques throughout the lifecycle of LLMs, including data preparation, pre-training, fine-tuning, instruction-tuning, preference alignment, and applications. Furthermore, We discuss the current constraints faced by these methods and investigate potential pathways for future development and research. Our aspiration is to equip researchers with a clear understanding of these methodologies, enabling them to swiftly identify appropriate data generation strategies in the construction of LLMs, while providing valuable insights for future exploration.