 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Regularized Generative Auto-Bidding: From Suboptimal Trajectories to Optimal Policies
Jan 06, 2026With the rapid development of e-commerce, auto-bidding has become a key asset in optimizing advertising performance under diverse advertiser environments. The current approaches focus on reinforcement learning (RL) and generative models. These efforts imitate offline historical behaviors by utilizing a complex structure with expensive hyperparameter tuning. The suboptimal trajectories further exacerbate the difficulty of policy learning. To address these challenges, we proposes QGA, a novel Q-value regularized Generative Auto-bidding method. In QGA, we propose to plug a Q-value regularization with double Q-learning strategy into the Decision Transformer backbone. This design enables joint optimization of policy imitation and action-value maximization, allowing the learned bidding policy to both leverage experience from the dataset and alleviate the adverse impact of the suboptimal trajectories. Furthermore, to safely explore the policy space beyond the data distribution, we propose a Q-value guided dual-exploration mechanism, in which the DT model is conditioned on multiple return-to-go targets and locally perturbed actions. This entire exploration process is dynamically guided by the aforementioned Q-value module, which provides principled evaluation for each candidate action. Experiments on public benchmarks and simulation environments demonstrate that QGA consistently achieves superior or highly competitive results compared to existing alternatives. Notably, in large-scale real-world A/B testing, QGA achieves a 3.27% increase in Ad GMV and a 2.49% improvement in Ad ROI.
COMPARE: Clinical Optimization with Modular Planning and Assessment via RAG-Enhanced AI-OCT: Superior Decision Support for Percutaneous Coronary Intervention Compared to ChatGPT-5 and Junior Operators
Dec 11, 2025Background: While intravascular imaging, particularly optical coherence tomography (OCT), improves percutaneous coronary intervention (PCI) outcomes, its interpretation is operator-dependent. General-purpose artificial intelligence (AI) shows promise but lacks domain-specific reliability. We evaluated the performance of CA-GPT, a novel large model deployed on an AI-OCT system, against that of the general-purpose ChatGPT-5 and junior physicians for OCT-guided PCI planning and assessment. Methods: In this single-center analysis of 96 patients who underwent OCT-guided PCI, the procedural decisions generated by the CA-GPT, ChatGPT-5, and junior physicians were compared with an expert-derived procedural record. Agreement was assessed using ten pre-specified metrics across pre-PCI and post-PCI phases. Results: For pre-PCI planning, CA-GPT demonstrated significantly higher median agreement scores (5[IQR 3.75-5]) compared to both ChatGPT-5 (3[2-4], P<0.001) and junior physicians (4[3-4], P<0.001). CA-GPT significantly outperformed ChatGPT-5 across all individual pre-PCI metrics and showed superior performance to junior physicians in stent diameter (90.3% vs. 72.2%, P<0.05) and length selection (80.6% vs. 52.8%, P<0.01). In post-PCI assessment, CA-GPT maintained excellent overall agreement (5[4.75-5]), significantly higher than both ChatGPT-5 (4[4-5], P<0.001) and junior physicians (5[4-5], P<0.05). Subgroup analysis confirmed CA-GPT's robust performance advantage in complex scenarios. Conclusion: The CA-GPT-based AI-OCT system achieved superior decision-making agreement versus a general-purpose large language model and junior physicians across both PCI planning and assessment phases. This approach provides a standardized and reliable method for intravascular imaging interpretation, demonstrating significant potential to augment operator expertise and optimize OCT-guided PCI.
A Survey on Remote Sensing Foundation Models: From Vision to Multimodality
Mar 28, 2025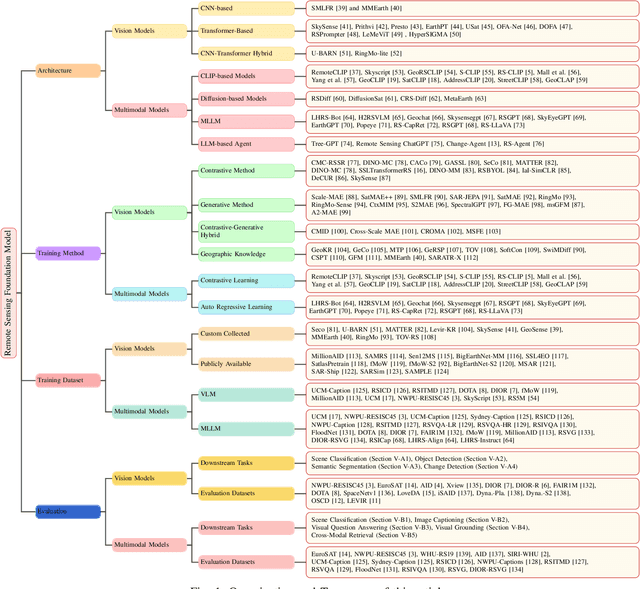
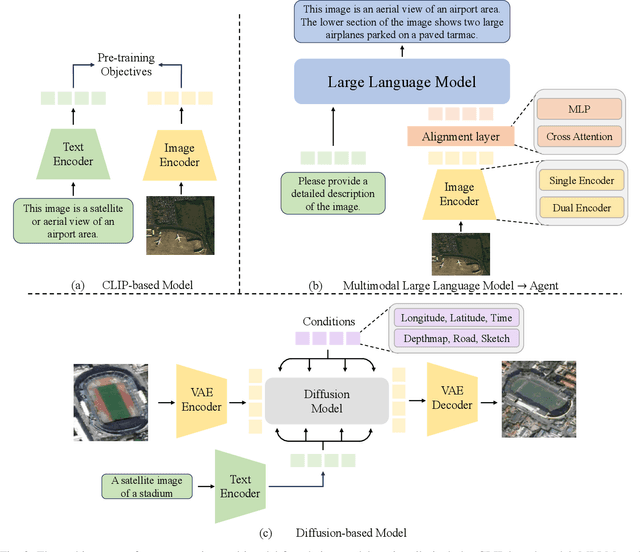

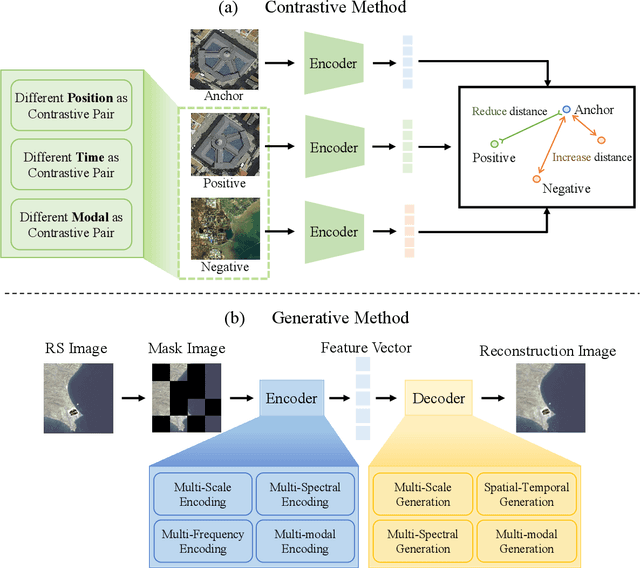
The rapid advancement of remote sensing foundation models, particularly vision and multimodal models, has significantly enhanced the capabilities of intelligent geospatial data interpretation. These models combine various data modalities, such as optical, radar, and LiDAR imagery, with textual and geographic information, enabling more comprehensive analysis and understanding of remote sensing data. The integration of multiple modalities allows for improved performance in tasks like object detection, land cover classification, and change detection, which are often challenged by the complex and heterogeneous nature of remote sensing data. However, despite these advancements, several challenges remain. The diversity in data types, the need for large-scale annotated datasets, and the complexity of multimodal fusion techniques pose significant obstacles to the effective deployment of these models. Moreover, the computational demands of training and fine-tuning multimodal models require significant resources, further complicating their practical application in remote sensing image interpretation tasks. This paper provides a comprehensive review of the state-of-the-art in vision and multimodal foundation models for remote sensing, focusing on their architecture, training methods, datasets and application scenarios. We discuss the key challenges these models face, such as data alignment, cross-modal transfer learning, and scalability, while also identifying emerging research directions aimed at overcoming these limitations. Our goal is to provide a clear understanding of the current landscape of remote sensing foundation models and inspire future research that can push the boundaries of what these models can achieve in real-world applications. The list of resources collected by the paper can be found in the https://github.com/IRIP-BUAA/A-Review-for-remote-sensing-vision-language-models.
Pushing DSP-Free Coherent Interconnect to the Last Inch by Optically Analog Signal Processing
Mar 14, 2025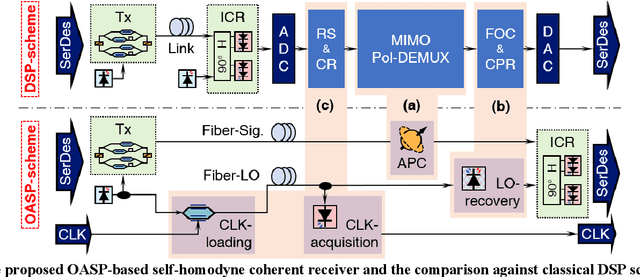
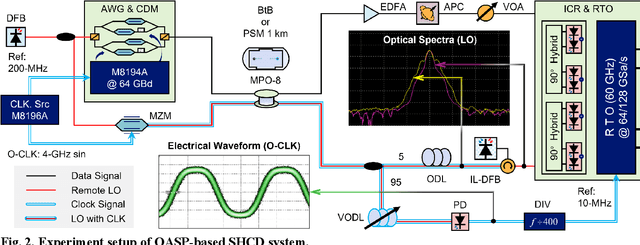
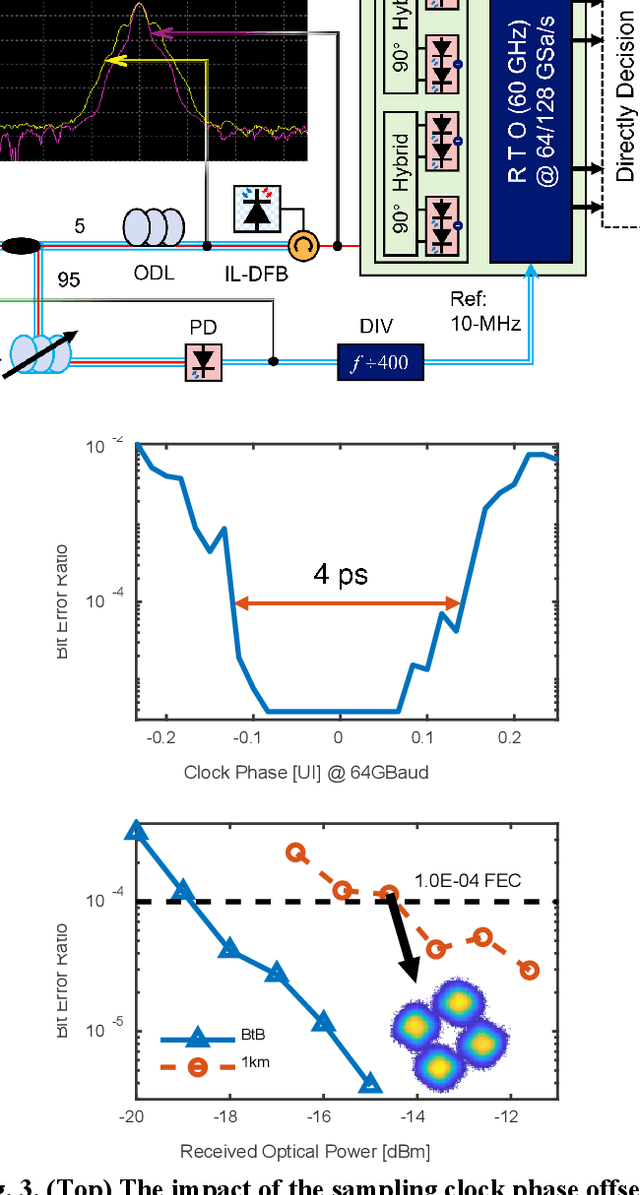
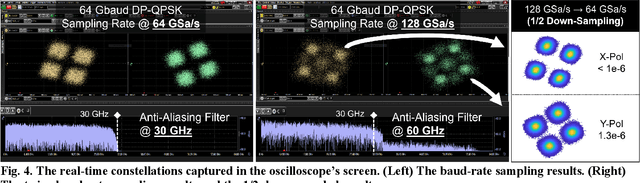
To support the boosting interconnect capacity of the AI-related data centers, novel techniques enabled high-speed and low-cost optics are continuously emerging. When the baud rate approaches 200 GBaud per lane, the bottle-neck of traditional intensity modulation direct detection (IM-DD) architectures becomes increasingly evident. The simplified coherent solutions are widely discussed and considered as one of the most promising candidates. In this paper, a novel coherent architecture based on self-homodyne coherent detection and optically analog signal processing (OASP) is demonstrated. Proved by experiment, the first DSP-free baud-rate sampled 64-GBaud QPSK/16-QAM receptions are achieved, with BERs of 1e-6 and 2e-2, respectively. Even with 1-km fiber link propagation, the BER for QPSK reception remains at 3.6e-6. When an ultra-simple 1-sps SISO filter is utilized, the performance degradation of the proposed scheme is less than 1 dB compared to legacy DSP-based coherent reception. The proposed results pave the way for the ultra-high-speed coherent optical interconnections, offering high power and cost efficiency.
Anti-Degeneracy Scheme for Lidar SLAM based on Particle Filter in Geometry Feature-Less Environments
Feb 17, 2025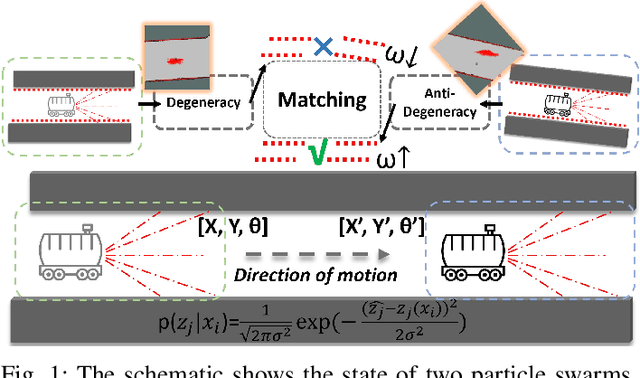

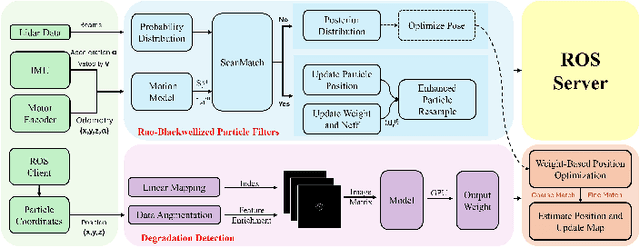
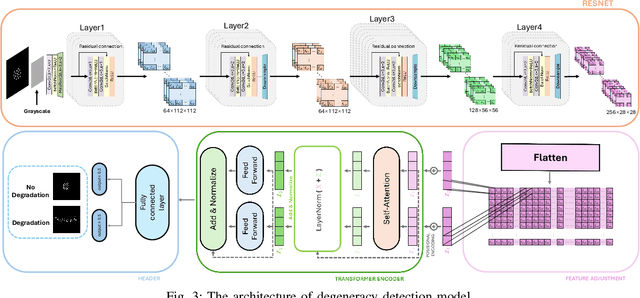
Simultaneous localization and mapping (SLAM) based on particle filtering has been extensively employed in indoor scenarios due to its high efficiency. However, in geometry feature-less scenes, the accuracy is severely reduced due to lack of constraints. In this article, we propose an anti-degeneracy system based on deep learning. Firstly, we design a scale-invariant linear mapping to convert coordinates in continuous space into discrete indexes, in which a data augmentation method based on Gaussian model is proposed to ensure the model performance by effectively mitigating the impact of changes in the number of particles on the feature distribution. Secondly, we develop a degeneracy detection model using residual neural networks (ResNet) and transformer which is able to identify degeneracy by scrutinizing the distribution of the particle population. Thirdly, an adaptive anti-degeneracy strategy is designed, which first performs fusion and perturbation on the resample process to provide rich and accurate initial values for the pose optimization, and use a hierarchical pose optimization combining coarse and fine matching, which is able to adaptively adjust the optimization frequency and the sensor trustworthiness according to the degree of degeneracy, in order to enhance the ability of searching the global optimal pose. Finally, we demonstrate the optimality of the model, as well as the improvement of the image matrix method and GPU on the computation time through ablation experiments, and verify the performance of the anti-degeneracy system in different scenarios through simulation experiments and real experiments. This work has been submitted to IEEE for publication. Copyright may be transferred without notice, after which this version may no longer be available.
AIGT: AI Generative Table Based on Prompt
Dec 24, 2024



Tabular data, which accounts for over 80% of enterprise data assets, is vital in various fields. With growing concerns about privacy protection and data-sharing restrictions, generating high-quality synthetic tabular data has become essential. Recent advancements show that large language models (LLMs) can effectively gener-ate realistic tabular data by leveraging semantic information and overcoming the challenges of high-dimensional data that arise from one-hot encoding. However, current methods do not fully utilize the rich information available in tables. To address this, we introduce AI Generative Table (AIGT) based on prompt enhancement, a novel approach that utilizes meta data information, such as table descriptions and schemas, as prompts to generate ultra-high quality synthetic data. To overcome the token limit constraints of LLMs, we propose long-token partitioning algorithms that enable AIGT to model tables of any scale. AIGT achieves state-of-the-art performance on 14 out of 20 public datasets and two real industry datasets within the Alipay risk control system.
Beyond Tree Models: A Hybrid Model of KAN and gMLP for Large-Scale Financial Tabular Data
Dec 03, 2024



Tabular data plays a critical role in real-world financial scenarios. Traditionally, tree models have dominated in handling tabular data. However, financial datasets in the industry often encounter some challenges, such as data heterogeneity, the predominance of numerical features and the large scale of the data, which can range from tens of millions to hundreds of millions of records. These challenges can lead to significant memory and computational issues when using tree-based models. Consequently, there is a growing need for neural network-based solutions that can outperform these models. In this paper, we introduce TKGMLP, an hybrid network for tabular data that combines shallow Kolmogorov Arnold Networks with Gated Multilayer Perceptron. This model leverages the strengths of both architectures to improve performance and scalability. We validate TKGMLP on a real-world credit scoring dataset, where it achieves state-of-the-art results and outperforms current benchmarks. Furthermore, our findings demonstrate that the model continues to improve as the dataset size increases, making it highly scalable. Additionally, we propose a novel feature encoding method for numerical data, specifically designed to address the predominance of numerical features in financial datasets. The integration of this feature encoding method within TKGMLP significantly improves prediction accuracy. This research not only advances table prediction technology but also offers a practical and effective solution for handling large-scale numerical tabular data in various industrial applications.
Fermat Number Transform Based Chromatic Dispersion Compensation and Adaptive Equalization Algorithm
May 07, 2024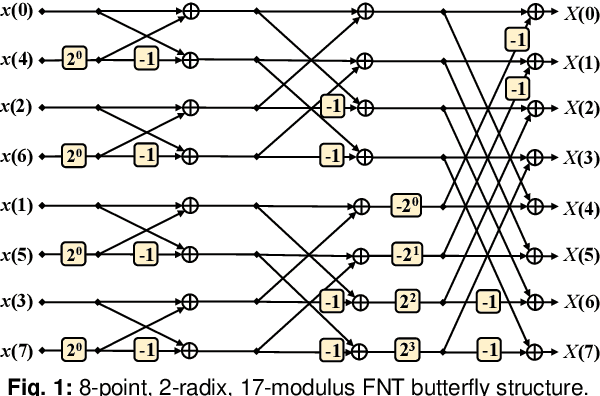
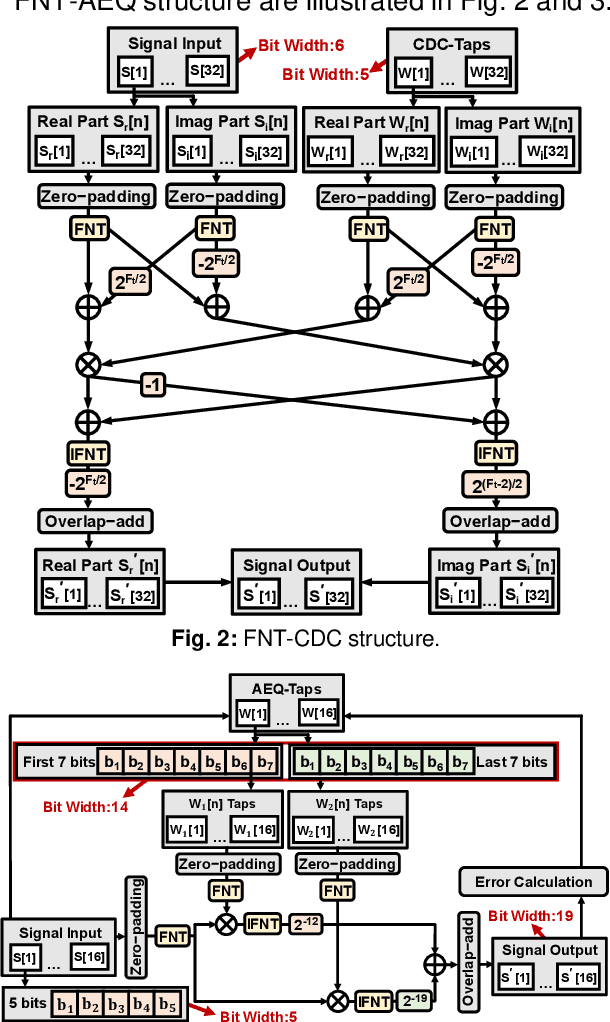
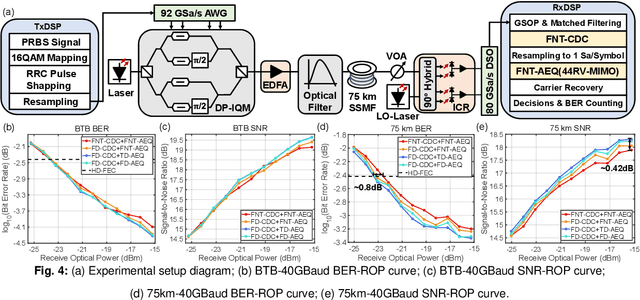
By introducing the Fermat number transform into chromatic dispersion compensation and adaptive equalization, the computational complexity has been reduced by 68% compared with the con?ventional implementation. Experimental results validate its transmission performance with only 0.8 dB receiver sensitivity penalty in a 75 km-40 GBaud-PDM-16QAM system.
Generic Knowledge Boosted Pre-training For Remote Sensing Images
Jan 21, 2024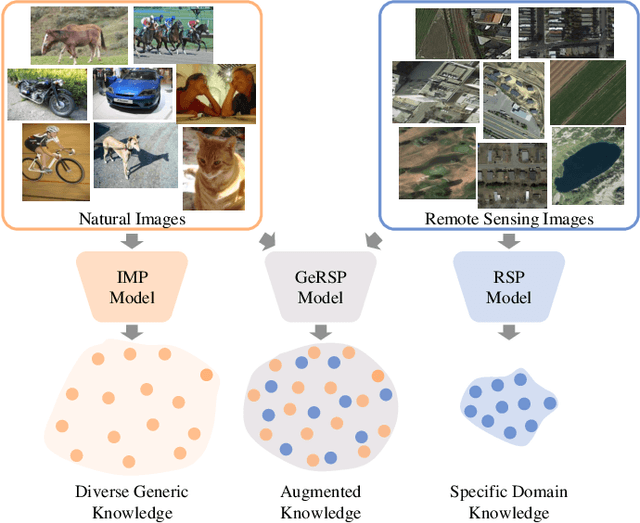
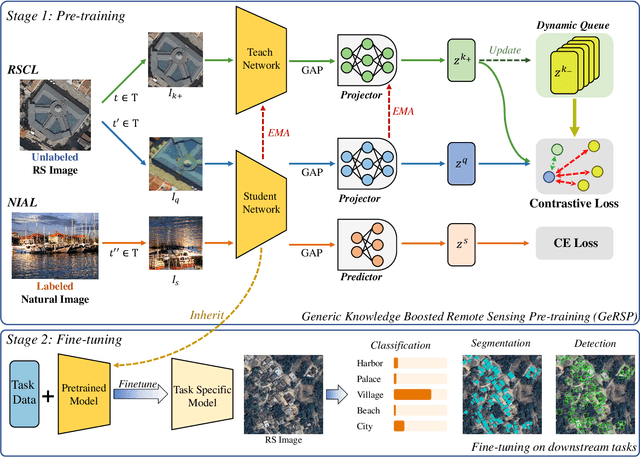
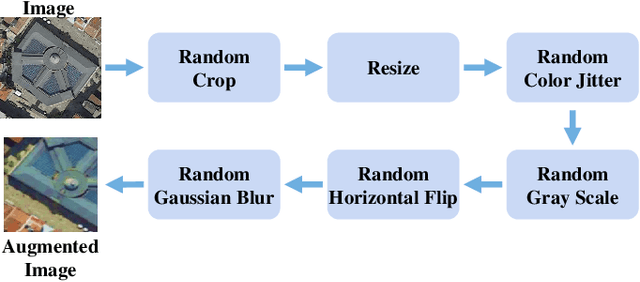
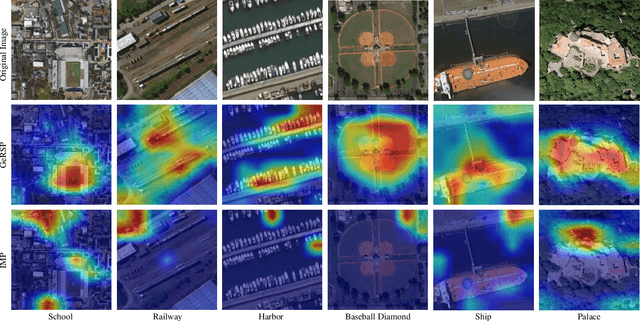
Deep learning models are essential for scene classification, change detection, land cover segmentation, and other remote sensing image understanding tasks. Most backbones of existing remote sensing deep learning models are typically initialized by pre-trained weights obtained from ImageNet pre-training (IMP). However, domain gaps exist between remote sensing images and natural images (e.g., ImageNet), making deep learning models initialized by pre-trained weights of IMP perform poorly for remote sensing image understanding. Although some pre-training methods are studied in the remote sensing community, current remote sensing pre-training methods face the problem of vague generalization by only using remote sensing images. In this paper, we propose a novel remote sensing pre-training framework, Generic Knowledge Boosted Remote Sensing Pre-training (GeRSP), to learn robust representations from remote sensing and natural images for remote sensing understanding tasks. GeRSP contains two pre-training branches: (1) A self-supervised pre-training branch is adopted to learn domain-related representations from unlabeled remote sensing images. (2) A supervised pre-training branch is integrated into GeRSP for general knowledge learning from labeled natural images. Moreover, GeRSP combines two pre-training branches using a teacher-student architecture to simultaneously learn representations with general and special knowledge, which generates a powerful pre-trained model for deep learning model initialization. Finally, we evaluate GeRSP and other remote sensing pre-training methods on three downstream tasks, i.e., object detection, semantic segmentation, and scene classification. The extensive experimental results consistently demonstrate that GeRSP can effectively learn robust representations in a unified manner, improving the performance of remote sensing downstream tasks.
A Spatio-Temporal Graph Convolutional Network for Gesture Recognition from High-Density Electromyography
Dec 01, 2023Accurate hand gesture prediction is crucial for effective upper-limb prosthetic limbs control. As the high flexibility and multiple degrees of freedom exhibited by human hands, there has been a growing interest in integrating deep networks with high-density surface electromyography (HD-sEMG) grids to enhance gesture recognition capabilities. However, many existing methods fall short in fully exploit the specific spatial topology and temporal dependencies present in HD-sEMG data. Additionally, these studies are often limited number of gestures and lack generality. Hence, this study introduces a novel gesture recognition method, named STGCN-GR, which leverages spatio-temporal graph convolution networks for HD-sEMG-based human-machine interfaces. Firstly, we construct muscle networks based on functional connectivity between channels, creating a graph representation of HD-sEMG recordings. Subsequently, a temporal convolution module is applied to capture the temporal dependences in the HD-sEMG series and a spatial graph convolution module is employed to effectively learn the intrinsic spatial topology information among distinct HD-sEMG channels. We evaluate our proposed model on a public HD-sEMG dataset comprising a substantial number of gestures (i.e., 65). Our results demonstrate the remarkable capability of the STGCN-GR method, achieving an impressive accuracy of 91.07% in predicting gestures, which surpasses state-of-the-art deep learning methods applied to the same dataset.