 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Model for Object Detection and Segmentation: A Review and Evaluation
Apr 13, 2025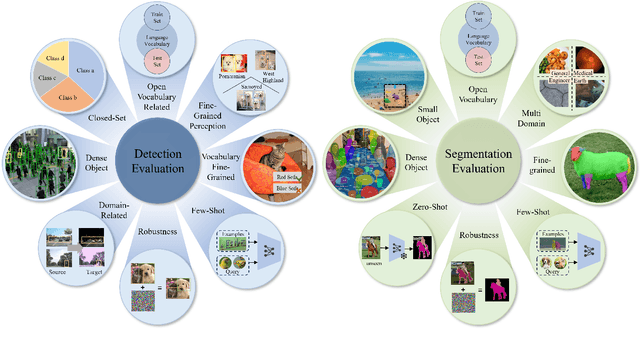
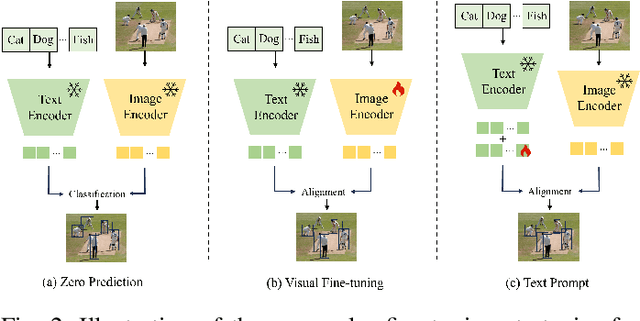
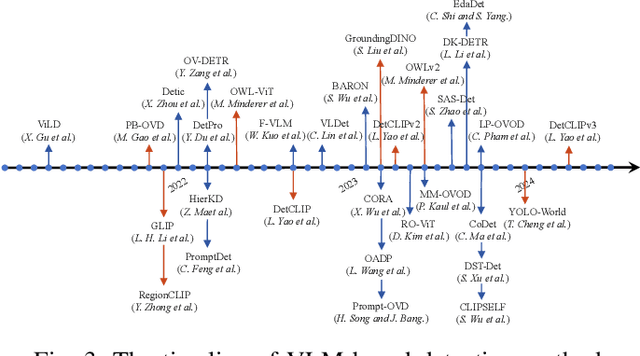
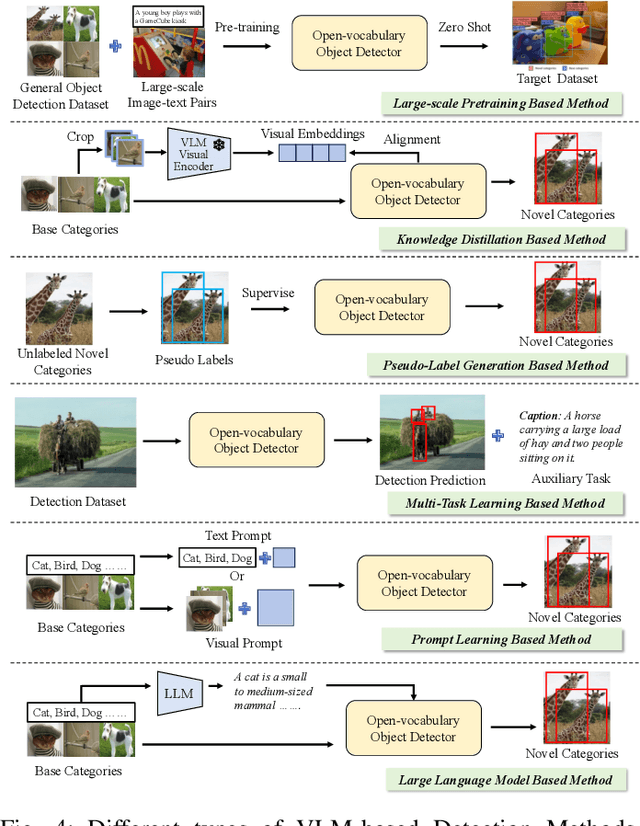
Vision-Language Model (VLM) have gained widespread adoption in Open-Vocabulary (OV) object detection and segmentation tasks. Despite they have shown promise on OV-related tasks, their effectiveness in conventional vision tasks has thus far been unevaluated. In this work, we present the systematic review of VLM-based detection and segmentation, view VLM as the foundational model and conduct comprehensive evaluations across multiple downstream tasks for the first time: 1) The evaluation spans eight detection scenarios (closed-set detection, domain adaptation, crowded objects, etc.) and eight segmentation scenarios (few-shot, open-world, small object, etc.), revealing distinct performance advantages and limitations of various VLM architectures across tasks. 2) As for detection tasks, we evaluate VLMs under three finetuning granularities: \textit{zero prediction}, \textit{visual fine-tuning}, and \textit{text prompt}, and further analyze how different finetuning strategies impact performance under varied task. 3) Based on empirical findings, we provide in-depth analysis of the correlations between task characteristics, model architectures, and training methodologies, offering insights for future VLM design. 4) We believe that this work shall be valuable to the pattern recognition experts working in the fields of computer vision, multimodal learning, and vision foundation models by introducing them to the problem, and familiarizing them with the current status of the progress while providing promising directions for future research. A project associated with this review and evaluation has been created at https://github.com/better-chao/perceptual_abilities_evaluation.
Lightweight Spatial Embedding for Vision-based 3D Occupancy Prediction
Dec 08, 2024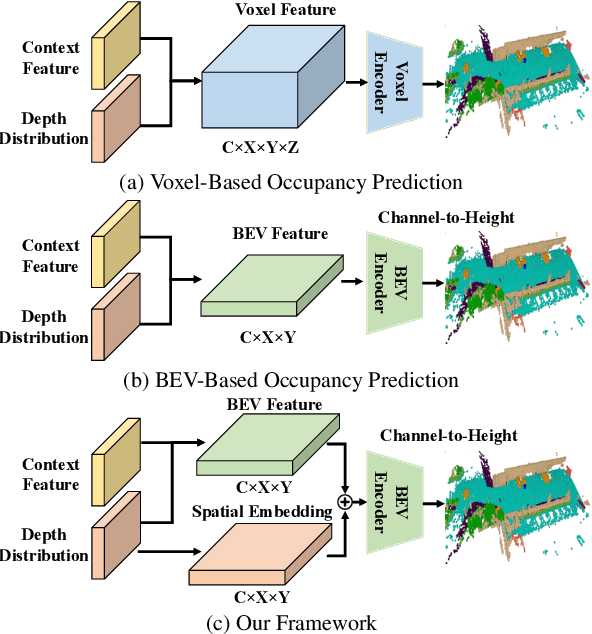
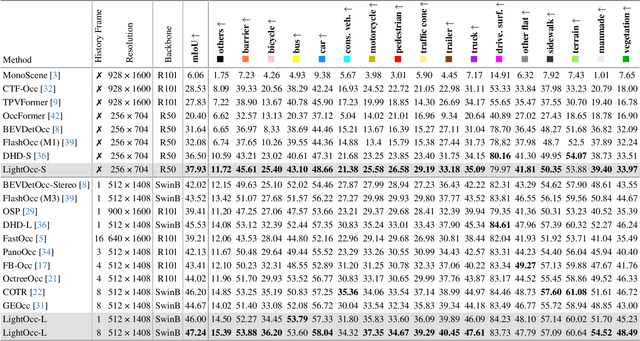
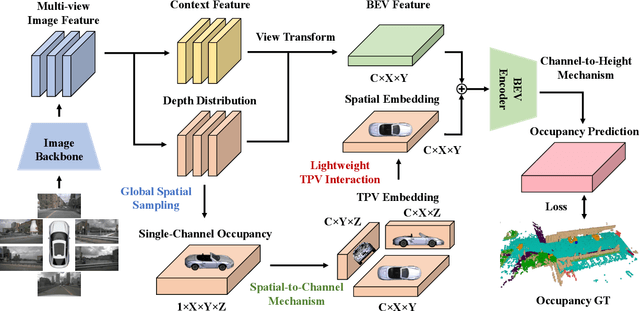
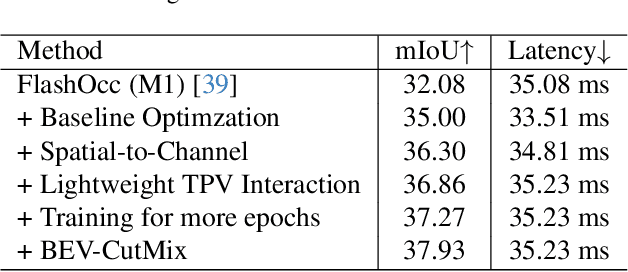
Occupancy prediction has garnered increasing attention in recent years for its comprehensive fine-grained environmental representation and strong generalization to open-set objects. However, cumbersome voxel features and 3D convolution operations inevitably introduce large overheads in both memory and computation, obstructing the deployment of occupancy prediction approaches in real-time autonomous driving systems. Although some methods attempt to efficiently predict 3D occupancy from 2D Bird's-Eye-View (BEV) features through the Channel-to-Height mechanism, BEV features are insufficient to store all the height information of the scene, which limits performance. This paper proposes LightOcc, an innovative 3D occupancy prediction framework that leverages Lightweight Spatial Embedding to effectively supplement the height clues for the BEV-based representation while maintaining its deployability. Firstly, Global Spatial Sampling is used to obtain the Single-Channel Occupancy from multi-view depth distribution. Spatial-to-Channel mechanism then takes the arbitrary spatial dimension of Single-Channel Occupancy as the feature dimension and extracts Tri-Perspective Views (TPV) Embeddings by 2D convolution. Finally, TPV Embeddings will interact with each other by Lightweight TPV Interaction module to obtain the Spatial Embedding that is optimal supplementary to BEV features. Sufficient experimental results show that LightOcc significantly increases the prediction accuracy of the baseline and achieves state-of-the-art performance on the Occ3D-nuScenes benchmark.
GeoBEV: Learning Geometric BEV Representation for Multi-view 3D Object Detection
Sep 03, 2024



Bird's-Eye-View (BEV) representation has emerged as a mainstream paradigm for multi-view 3D object detection, demonstrating impressive perceptual capabilities. However, existing methods overlook the geometric quality of BEV representation, leaving it in a low-resolution state and failing to restore the authentic geometric information of the scene. In this paper, we identify the reasons why previous approaches are constrained by low BEV representation resolution and propose Radial-Cartesian BEV Sampling (RC-Sampling), enabling efficient generation of high-resolution dense BEV representations without the need for complex operators. Additionally, we design a novel In-Box Label to substitute the traditional depth label generated from the LiDAR points. This label reflects the actual geometric structure of objects rather than just their surfaces, injecting real-world geometric information into the BEV representation. Furthermore, in conjunction with the In-Box Label, a Centroid-Aware Inner Loss (CAI Loss) is developed to capture the fine-grained inner geometric structure of objects. Finally, we integrate the aforementioned modules into a novel multi-view 3D object detection framework, dubbed GeoBEV. Extensive experiments on the nuScenes dataset exhibit that GeoBEV achieves state-of-the-art performance, highlighting its effectiveness.
FSD-BEV: Foreground Self-Distillation for Multi-view 3D Object Detection
Jul 14, 2024



Although multi-view 3D object detection based on the Bird's-Eye-View (BEV) paradigm has garnered widespread attention as an economical and deployment-friendly perception solution for autonomous driving, there is still a performance gap compared to LiDAR-based methods. In recent years, several cross-modal distillation methods have been proposed to transfer beneficial information from teacher models to student models, with the aim of enhancing performance. However, these methods face challenges due to discrepancies in feature distribution originating from different data modalities and network structures, making knowledge transfer exceptionally challenging. In this paper, we propose a Foreground Self-Distillation (FSD) scheme that effectively avoids the issue of distribution discrepancies, maintaining remarkable distillation effects without the need for pre-trained teacher models or cumbersome distillation strategies. Additionally, we design two Point Cloud Intensification (PCI) strategies to compensate for the sparsity of point clouds by frame combination and pseudo point assignment. Finally, we develop a Multi-Scale Foreground Enhancement (MSFE) module to extract and fuse multi-scale foreground features by predicted elliptical Gaussian heatmap, further improving the model's performance. We integrate all the above innovations into a unified framework named FSD-BEV. Extensive experiments on the nuScenes dataset exhibit that FSD-BEV achieves state-of-the-art performance, highlighting its effectiveness. The code and models are available at: https://github.com/CocoBoom/fsd-bev.
Vision-based 3D occupancy prediction in autonomous driving: a review and outlook
May 04, 2024



In recent years, autonomous driving has garnered escalating attention for its potential to relieve drivers' burdens and improve driving safety. Vision-based 3D occupancy prediction, which predicts the spatial occupancy status and semantics of 3D voxel grids around the autonomous vehicle from image inputs, is an emerging perception task suitable for cost-effective perception system of autonomous driving. Although numerous studies have demonstrated the greater advantages of 3D occupancy prediction over object-centric perception tasks, there is still a lack of a dedicated review focusing on this rapidly developing field. In this paper, we first introduce the background of vision-based 3D occupancy prediction and discuss the challenges in this task. Secondly, we conduct a comprehensive survey of the progress in vision-based 3D occupancy prediction from three aspects: feature enhancement, deployment friendliness and label efficiency, and provide an in-depth analysis of the potentials and challenges of each category of methods. Finally, we present a summary of prevailing research trends and propose some inspiring future outlooks. To provide a valuable reference for researchers, a regularly updated collection of related papers, datasets, and codes is organized at https://github.com/zya3d/Awesome-3D-Occupancy-Prediction.
SA-BEV: Generating Semantic-Aware Bird's-Eye-View Feature for Multi-view 3D Object Detection
Jul 21, 2023



Recently, the pure camera-based Bird's-Eye-View (BEV) perception provides a feasible solution for economical autonomous driving. However, the existing BEV-based multi-view 3D detectors generally transform all image features into BEV features, without considering the problem that the large proportion of background information may submerge the object information. In this paper, we propose Semantic-Aware BEV Pooling (SA-BEVPool), which can filter out background information according to the semantic segmentation of image features and transform image features into semantic-aware BEV features. Accordingly, we propose BEV-Paste, an effective data augmentation strategy that closely matches with semantic-aware BEV feature. In addition, we design a Multi-Scale Cross-Task (MSCT) head, which combines task-specific and cross-task information to predict depth distribution and semantic segmentation more accurately, further improving the quality of semantic-aware BEV feature. Finally, we integrate the above modules into a novel multi-view 3D object detection framework, namely SA-BEV. Experiments on nuScenes show that SA-BEV achieves state-of-the-art performance. Code has been available at https://github.com/mengtan00/SA-BEV.git.