 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the SSL-AL Barrier: A Synergistic Semi-Supervised Active Learning Framework for 3D Object Detection
Jan 26, 2025



To address the annotation burden in LiDAR-based 3D object detection, active learning (AL) methods offer a promising solution. However, traditional active learning approaches solely rely on a small amount of labeled data to train an initial model for data selection, overlooking the potential of leveraging the abundance of unlabeled data. Recently, attempts to integrate semi-supervised learning (SSL) into AL with the goal of leveraging unlabeled data have faced challenges in effectively resolving the conflict between the two paradigms, resulting in less satisfactory performance. To tackle this conflict, we propose a Synergistic Semi-Supervised Active Learning framework, dubbed as S-SSAL. Specifically, from the perspective of SSL, we propose a Collaborative PseudoScene Pre-training (CPSP) method that effectively learns from unlabeled data without introducing adverse effects. From the perspective of AL, we design a Collaborative Active Learning (CAL) method, which complements the uncertainty and diversity methods by model cascading. This allows us to fully exploit the potential of the CPSP pre-trained model. Extensive experiments conducted on KITTI and Waymo demonstrate the effectiveness of our S-SSAL framework. Notably, on the KITTI dataset, utilizing only 2% labeled data, S-SSAL can achieve performance comparable to models trained on the full dataset.
Vision-based 3D occupancy prediction in autonomous driving: a review and outlook
May 04, 2024



In recent years, autonomous driving has garnered escalating attention for its potential to relieve drivers' burdens and improve driving safety. Vision-based 3D occupancy prediction, which predicts the spatial occupancy status and semantics of 3D voxel grids around the autonomous vehicle from image inputs, is an emerging perception task suitable for cost-effective perception system of autonomous driving. Although numerous studies have demonstrated the greater advantages of 3D occupancy prediction over object-centric perception tasks, there is still a lack of a dedicated review focusing on this rapidly developing field. In this paper, we first introduce the background of vision-based 3D occupancy prediction and discuss the challenges in this task. Secondly, we conduct a comprehensive survey of the progress in vision-based 3D occupancy prediction from three aspects: feature enhancement, deployment friendliness and label efficiency, and provide an in-depth analysis of the potentials and challenges of each category of methods. Finally, we present a summary of prevailing research trends and propose some inspiring future outlooks. To provide a valuable reference for researchers, a regularly updated collection of related papers, datasets, and codes is organized at https://github.com/zya3d/Awesome-3D-Occupancy-Prediction.
STS: Surround-view Temporal Stereo for Multi-view 3D Detection
Aug 22, 2022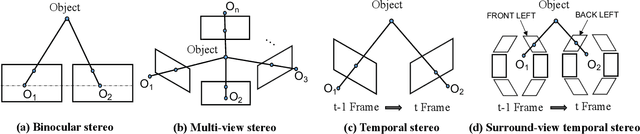
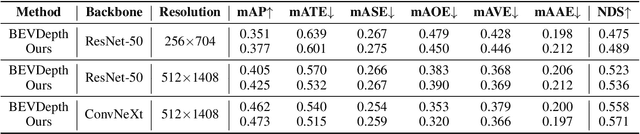
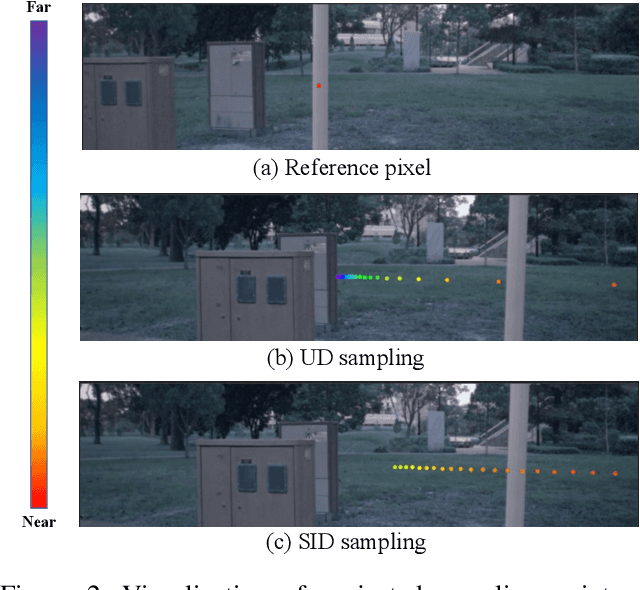
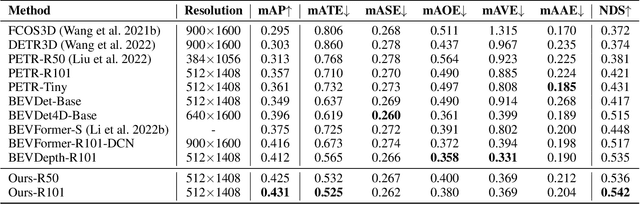
Learning accurate depth is essential to multi-view 3D object detection. Recent approaches mainly learn depth from monocular images, which confront inherent difficulties due to the ill-posed nature of monocular depth learning. Instead of using a sole monocular depth method, in this work, we propose a novel Surround-view Temporal Stereo (STS) technique that leverages the geometry correspondence between frames across time to facilitate accurate depth learning. Specifically, we regard the field of views from all cameras around the ego vehicle as a unified view, namely surroundview, and conduct temporal stereo matching on it. The resulting geometrical correspondence between different frames from STS is utilized and combined with the monocular depth to yield final depth prediction. Comprehensive experiments on nuScenes show that STS greatly boosts 3D detection ability, notably for medium and long distance objects. On BEVDepth with ResNet-50 backbone, STS improves mAP and NDS by 2.6% and 1.4%, respectively. Consistent improvements are observed when using a larger backbone and a larger image resolution, demonstrating its effectiveness
BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection
Jun 21, 2022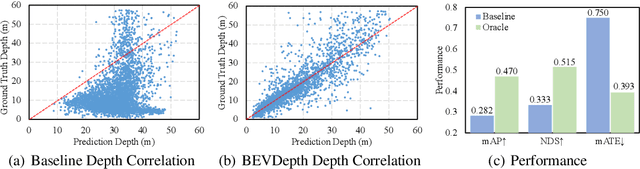
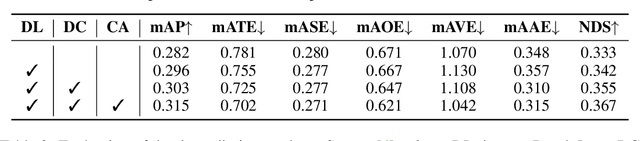
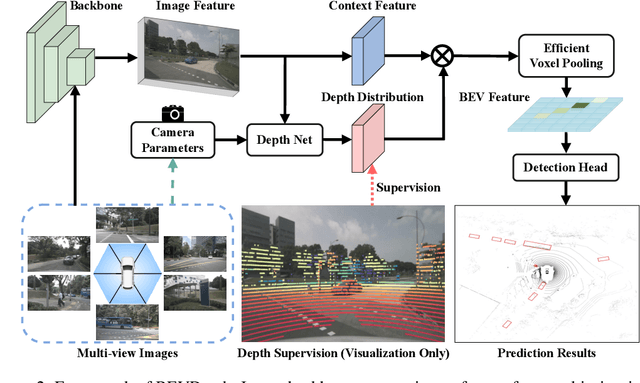
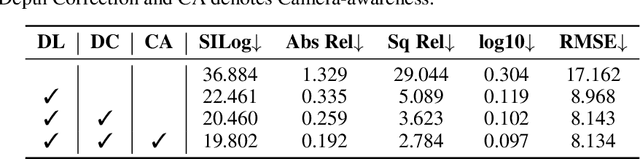
In this research, we propose a new 3D object detector with a trustworthy depth estimation, dubbed BEVDepth, for camera-based Bird's-Eye-View (BEV) 3D object detection. By a thorough analysis of recent approaches, we discover that the depth estimation is implicitly learned without camera information, making it the de-facto fake-depth for creating the following pseudo point cloud. BEVDepth gets explicit depth supervision utilizing encoded intrinsic and extrinsic parameters. A depth correction sub-network is further introduced to counteract projecting-induced disturbances in depth ground truth. To reduce the speed bottleneck while projecting features from image-view into BEV using estimated depth, a quick view-transform operation is also proposed. Besides, our BEVDepth can be easily extended with input from multi-frame. Without any bells and whistles, BEVDepth achieves the new state-of-the-art 60.0% NDS on the challenging nuScenes test set while maintaining high efficiency. For the first time, the performance gap between the camera and LiDAR is largely reduced within 10% NDS.