 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoReview: Learning Peer Review from the Echoes of Scientific Citations
Jan 31, 2026As the volume of scientific submissions continues to grow rapidly, traditional peer review systems are facing unprecedented scalability pressures, highlighting the urgent need for automated reviewing methods that are both scalable and reliable. Existing supervised fine-tuning approaches based on real review data are fundamentally constrained by single-source of data as well as the inherent subjectivity and inconsistency of human reviews, limiting their ability to support high-quality automated reviewers. To address these issues, we propose EchoReview, a citation-context-driven data synthesis framework that systematically mines implicit collective evaluative signals from academic citations and transforms scientific community's long-term judgments into structured review-style data. Based on this pipeline, we construct EchoReview-16K, the first large-scale, cross-conference, and cross-year citation-driven review dataset, and train an automated reviewer, EchoReviewer-7B. Experimental results demonstrate that EchoReviewer-7B can achieve significant and stable improvements on core review dimensions such as evidence support and review comprehensiveness, validating citation context as a robust and effective data paradigm for reliable automated peer review.
Fun-Audio-Chat Technical Report
Dec 23, 2025Recent advancements in joint speech-text models show great potential for seamless voice interactions. However, existing models face critical challenges: temporal resolution mismatch between speech tokens (25Hz) and text tokens (~3Hz) dilutes semantic information, incurs high computational costs, and causes catastrophic forgetting of text LLM knowledge. We introduce Fun-Audio-Chat, a Large Audio Language Model addressing these limitations via two innovations from our previous work DrVoice. First, Dual-Resolution Speech Representations (DRSR): the Shared LLM processes audio at efficient 5Hz (via token grouping), while the Speech Refined Head generates high-quality tokens at 25Hz, balancing efficiency (~50% GPU reduction) and quality. Second, Core-Cocktail Training, a two-stage fine-tuning with intermediate merging that mitigates catastrophic forgetting. We then apply Multi-Task DPO Training to enhance robustness, audio understanding, instruction-following and voice empathy. This multi-stage post-training enables Fun-Audio-Chat to retain text LLM knowledge while gaining powerful audio understanding, reasoning, and generation. Unlike recent LALMs requiring large-scale audio-text pre-training, Fun-Audio-Chat leverages pre-trained models and extensive post-training. Fun-Audio-Chat 8B and MoE 30B-A3B achieve competitive performance on Speech-to-Text and Speech-to-Speech tasks, ranking top among similar-scale models on Spoken QA benchmarks. They also achieve competitive to superior performance on Audio Understanding, Speech Function Calling, Instruction-Following and Voice Empathy. We develop Fun-Audio-Chat-Duplex, a full-duplex variant with strong performance on Spoken QA and full-duplex interactions. We open-source Fun-Audio-Chat-8B with training and inference code, and provide an interactive demo.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
CoSDH: Communication-Efficient Collaborative Perception via Supply-Demand Awareness and Intermediate-Late Hybridization
Mar 05, 2025



Multi-agent collaborative perception enhances perceptual capabilities by utilizing information from multiple agents and is considered a fundamental solution to the problem of weak single-vehicle perception in autonomous driving. However, existing collaborative perception methods face a dilemma between communication efficiency and perception accuracy. To address this issue, we propose a novel communication-efficient collaborative perception framework based on supply-demand awareness and intermediate-late hybridization, dubbed as \mymethodname. By modeling the supply-demand relationship between agents, the framework refines the selection of collaboration regions, reducing unnecessary communication cost while maintaining accuracy. In addition, we innovatively introduce the intermediate-late hybrid collaboration mode, where late-stage collaboration compensates for the performance degradation in collaborative perception under low communication bandwidth. Extensive experiments on multiple datasets, including both simulated and real-world scenarios, demonstrate that \mymethodname~ achieves state-of-the-art detection accuracy and optimal bandwidth trade-offs, delivering superior detection precision under real communication bandwidths, thus proving its effectiveness and practical applicability. The code will be released at https://github.com/Xu2729/CoSDH.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
StreetviewLLM: Extracting Geographic Information Using a Chain-of-Thought Multimodal Large Language Model
Nov 19, 2024



Geospatial predictions are crucial for diverse fields such as disaster management, urban planning, and public health. Traditional machine learning methods often face limitations when handling unstructured or multi-modal data like street view imagery. To address these challenges, we propose StreetViewLLM, a novel framework that integrates a large language model with the chain-of-thought reasoning and multimodal data sources. By combining street view imagery with geographic coordinates and textual data, StreetViewLLM improves the precision and granularity of geospatial predictions. Using retrieval-augmented generation techniques, our approach enhances geographic information extraction, enabling a detailed analysis of urban environments. The model has been applied to seven global cities, including Hong Kong, Tokyo, Singapore, Los Angeles, New York, London, and Paris, demonstrating superior performance in predicting urban indicators, including population density, accessibility to healthcare, normalized difference vegetation index, building height, and impervious surface. The results show that StreetViewLLM consistently outperforms baseline models, offering improved predictive accuracy and deeper insights into the built environment. This research opens new opportunities for integrating the large language model into urban analytics, decision-making in urban planning, infrastructure management, and environmental monitoring.
MooER: LLM-based Speech Recognition and Translation Models from Moore Threads
Aug 09, 2024In this paper, we present MooER, a LLM-based large-scale automatic speech recognition (ASR) / automatic speech translation (AST) model of Moore Threads. A 5000h pseudo labeled dataset containing open source and self collected speech data is used for training. We achieve performance comparable to other open source models trained with up to hundreds of thousands of hours of labeled speech data. Meanwhile, experiments conducted on Covost2 Zh2en testset suggest that our model outperforms other open source Speech LLMs. A BLEU score of 25.2 can be obtained. The main contributions of this paper are summarized as follows. First, this paper presents a training strategy for encoders and LLMs on speech related tasks (including ASR and AST) using a small size of pseudo labeled data without any extra manual annotation and selection. Second, we release our ASR and AST models and plan to open-source our training code and strategy in the near future. Moreover, a model trained on 8wh scale training data is planned to be released later on.
Vision-based 3D occupancy prediction in autonomous driving: a review and outlook
May 04, 2024



In recent years, autonomous driving has garnered escalating attention for its potential to relieve drivers' burdens and improve driving safety. Vision-based 3D occupancy prediction, which predicts the spatial occupancy status and semantics of 3D voxel grids around the autonomous vehicle from image inputs, is an emerging perception task suitable for cost-effective perception system of autonomous driving. Although numerous studies have demonstrated the greater advantages of 3D occupancy prediction over object-centric perception tasks, there is still a lack of a dedicated review focusing on this rapidly developing field. In this paper, we first introduce the background of vision-based 3D occupancy prediction and discuss the challenges in this task. Secondly, we conduct a comprehensive survey of the progress in vision-based 3D occupancy prediction from three aspects: feature enhancement, deployment friendliness and label efficiency, and provide an in-depth analysis of the potentials and challenges of each category of methods. Finally, we present a summary of prevailing research trends and propose some inspiring future outlooks. To provide a valuable reference for researchers, a regularly updated collection of related papers, datasets, and codes is organized at https://github.com/zya3d/Awesome-3D-Occupancy-Prediction.
The Future of Combating Rumors? Retrieval, Discrimination, and Generation
Mar 29, 2024
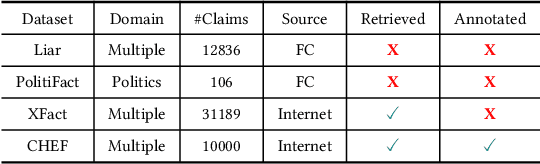
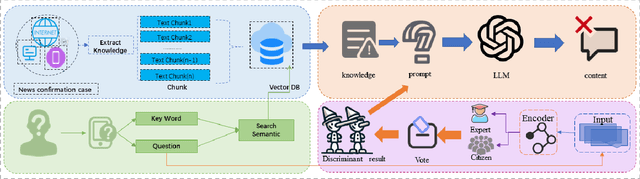
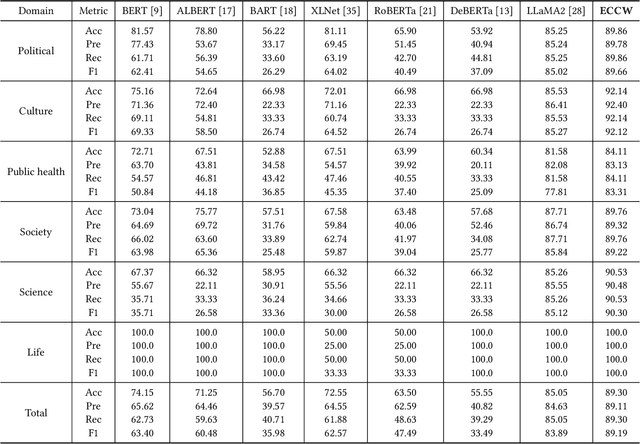
Artificial Intelligence Generated Content (AIGC) technology development has facilitated the creation of rumors with misinformation, impacting societal, economic, and political ecosystems, challenging democracy. Current rumor detection efforts fall short by merely labeling potentially misinformation (classification task), inadequately addressing the issue, and it is unrealistic to have authoritative institutions debunk every piece of information on social media. Our proposed comprehensive debunking process not only detects rumors but also provides explanatory generated content to refute the authenticity of the information. The Expert-Citizen Collective Wisdom (ECCW) module we designed aensures high-precision assessment of the credibility of information and the retrieval module is responsible for retrieving relevant knowledge from a Real-time updated debunking database based on information keywords. By using prompt engineering techniques, we feed results and knowledge into a LLM (Large Language Model), achieving satisfactory discrimination and explanatory effects while eliminating the need for fine-tuning, saving computational costs, and contributing to debunking efforts.
Bayesian Neural Network Language Modeling for Speech Recognition
Aug 28, 2022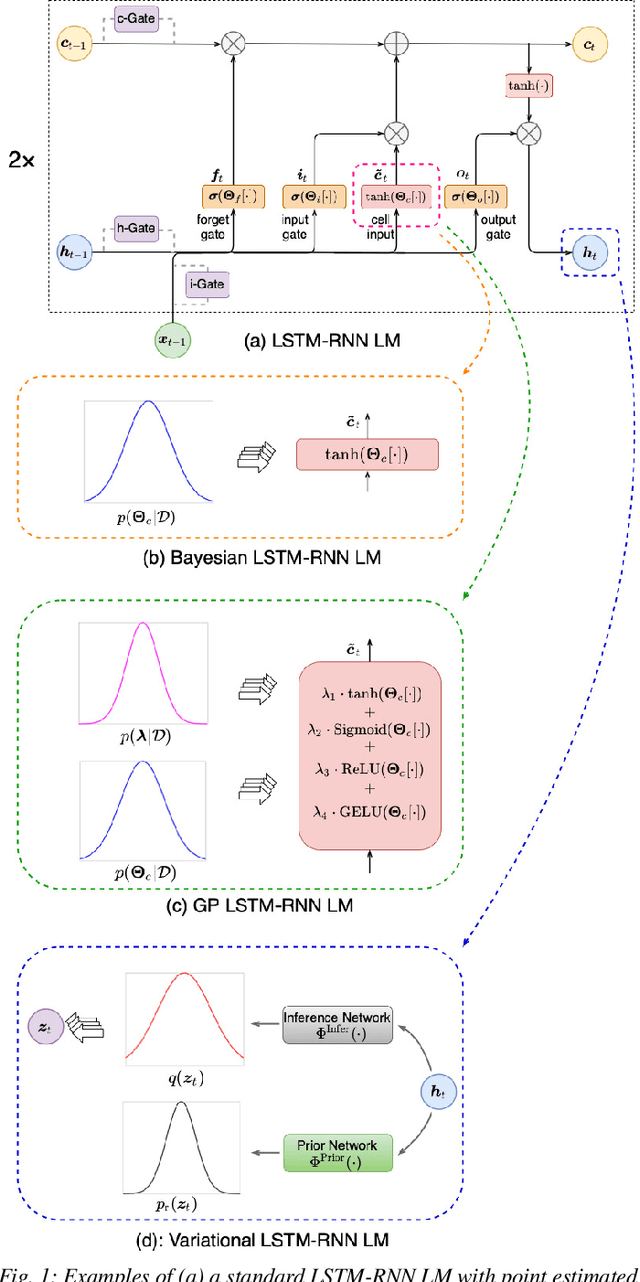



State-of-the-art neural network language models (NNLMs) represented by long short term memory recurrent neural networks (LSTM-RNNs) and Transformers are becoming highly complex. They are prone to overfitting and poor generalization when given limited training data. To this end, an overarching full Bayesian learning framework encompassing three methods is proposed in this paper to account for the underlying uncertainty in LSTM-RNN and Transformer LMs. The uncertainty over their model parameters, choice of neural activations and hidden output representations are modeled using Bayesian, Gaussian Process and variational LSTM-RNN or Transformer LMs respectively. Efficient inference approaches were used to automatically select the optimal network internal components to be Bayesian learned using neural architecture search. A minimal number of Monte Carlo parameter samples as low as one was also used. These allow the computational costs incurred in Bayesian NNLM training and evaluation to be minimized. Experiments are conducted on two tasks: AMI meeting transcription and Oxford-BBC LipReading Sentences 2 (LRS2) overlapped speech recognition using state-of-the-art LF-MMI trained factored TDNN systems featuring data augmentation, speaker adaptation and audio-visual multi-channel beamforming for overlapped speech. Consistent performance improvements over the baseline LSTM-RNN and Transformer LMs with point estimated model parameters and drop-out regularization were obtained across both tasks in terms of perplexity and word error rate (WER). In particular, on the LRS2 data, statistically significant WER reductions up to 1.3% and 1.2% absolute (12.1% and 11.3% relative) were obtained over the baseline LSTM-RNN and Transformer LMs respectively after model combination between Bayesian NNLMs and their respective baselines.