 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Neural Network Language Modeling for Speech Recognition
Paper and Code
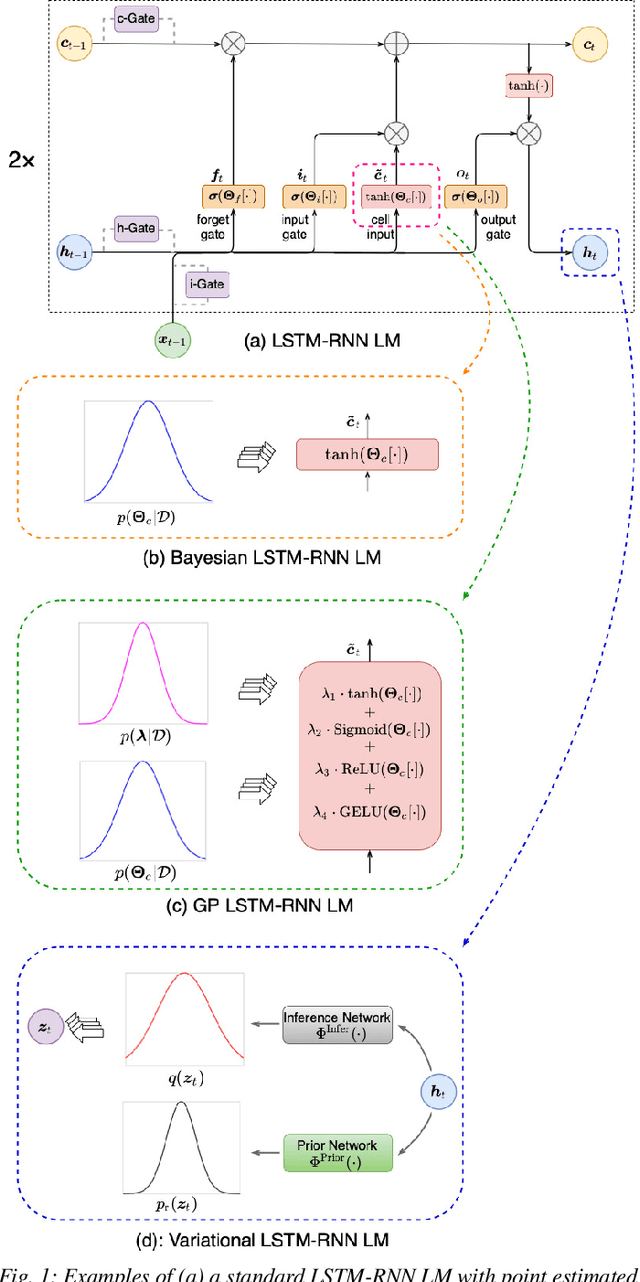



State-of-the-art neural network language models (NNLMs) represented by long short term memory recurrent neural networks (LSTM-RNNs) and Transformers are becoming highly complex. They are prone to overfitting and poor generalization when given limited training data. To this end, an overarching full Bayesian learning framework encompassing three methods is proposed in this paper to account for the underlying uncertainty in LSTM-RNN and Transformer LMs. The uncertainty over their model parameters, choice of neural activations and hidden output representations are modeled using Bayesian, Gaussian Process and variational LSTM-RNN or Transformer LMs respectively. Efficient inference approaches were used to automatically select the optimal network internal components to be Bayesian learned using neural architecture search. A minimal number of Monte Carlo parameter samples as low as one was also used. These allow the computational costs incurred in Bayesian NNLM training and evaluation to be minimized. Experiments are conducted on two tasks: AMI meeting transcription and Oxford-BBC LipReading Sentences 2 (LRS2) overlapped speech recognition using state-of-the-art LF-MMI trained factored TDNN systems featuring data augmentation, speaker adaptation and audio-visual multi-channel beamforming for overlapped speech. Consistent performance improvements over the baseline LSTM-RNN and Transformer LMs with point estimated model parameters and drop-out regularization were obtained across both tasks in terms of perplexity and word error rate (WER). In particular, on the LRS2 data, statistically significant WER reductions up to 1.3% and 1.2% absolute (12.1% and 11.3% relative) were obtained over the baseline LSTM-RNN and Transformer LMs respectively after model combination between Bayesian NNLMs and their respective baselines.