 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInnovating China's Intangible Cultural Heritage with DeepSeek + MidJourney: The Case of Yangliuqing theme Woodblock Prints
Jun 17, 2025Yangliuqing woodblock prints, a cornerstone of China's intangible cultural heritage, are celebrated for their intricate designs and vibrant colors. However, preserving these traditional art forms while fostering innovation presents significant challenges. This study explores the DeepSeek + MidJourney approach to generating creative, themed Yangliuqing woodblock prints focused on the fight against COVID-19 and depicting joyous winners. Using Fr\'echet Inception Distance (FID) scores for evaluation, the method that combined DeepSeek-generated thematic prompts, MidJourney-generated thematic images, original Yangliuqing prints, and DeepSeek-generated key prompts in MidJourney-generated outputs achieved the lowest mean FID score (150.2) with minimal variability ({\sigma} = 4.9). Additionally, feedback from 62 participants, collected via questionnaires, confirmed that this hybrid approach produced the most representative results. Moreover, the questionnaire data revealed that participants demonstrated the highest willingness to promote traditional culture and the strongest interest in consuming the AI-generated images produced through this method. These findings underscore the effectiveness of an innovative approach that seamlessly blends traditional artistic elements with modern AI-driven creativity, ensuring both cultural preservation and contemporary relevance.
Leveraging Large Language Models for Cost-Effective, Multilingual Depression Detection and Severity Assessment
Apr 07, 2025Depression is a prevalent mental health disorder that is difficult to detect early due to subjective symptom assessments. Recent advancements in large language models have offered efficient and cost-effective approaches for this objective. In this study, we evaluated the performance of four LLMs in depression detection using clinical interview data. We selected the best performing model and further tested it in the severity evaluation scenario and knowledge enhanced scenario. The robustness was evaluated in complex diagnostic scenarios using a dataset comprising 51074 statements from six different mental disorders. We found that DeepSeek V3 is the most reliable and cost-effective model for depression detection, performing well in both zero-shot and few-shot scenarios, with zero-shot being the most efficient choice. The evaluation of severity showed low agreement with the human evaluator, particularly for mild depression. The model maintains stably high AUCs for detecting depression in complex diagnostic scenarios. These findings highlight DeepSeek V3s strong potential for text-based depression detection in real-world clinical applications. However, they also underscore the need for further refinement in severity assessment and the mitigation of potential biases to enhance clinical reliability.
The Future of Combating Rumors? Retrieval, Discrimination, and Generation
Mar 29, 2024
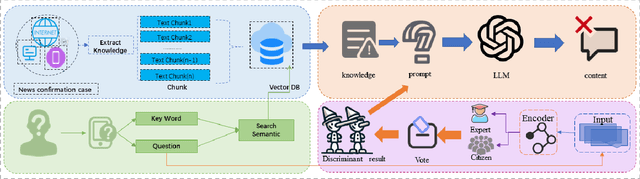
Artificial Intelligence Generated Content (AIGC) technology development has facilitated the creation of rumors with misinformation, impacting societal, economic, and political ecosystems, challenging democracy. Current rumor detection efforts fall short by merely labeling potentially misinformation (classification task), inadequately addressing the issue, and it is unrealistic to have authoritative institutions debunk every piece of information on social media. Our proposed comprehensive debunking process not only detects rumors but also provides explanatory generated content to refute the authenticity of the information. The Expert-Citizen Collective Wisdom (ECCW) module we designed aensures high-precision assessment of the credibility of information and the retrieval module is responsible for retrieving relevant knowledge from a Real-time updated debunking database based on information keywords. By using prompt engineering techniques, we feed results and knowledge into a LLM (Large Language Model), achieving satisfactory discrimination and explanatory effects while eliminating the need for fine-tuning, saving computational costs, and contributing to debunking efforts.