 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARBITER: Reasoning Trajectory Basins and Majority Vote Failures in Test-Time Sampling
May 25, 2026When language models use test-time sampling, they generate multiple reasoning trajectories and select an answer by majority vote. We show that these trajectories are not independent: for a given question, they concentrate into a small number of clusters, or reasoning basins, each defined by a normalized final answer and the solutions that reach it. A majority vote therefore selects the most stable basin rather than the most accurate one, which creates wrong-majority failures where the correct answer is present but outvoted. We introduce ARBITER, a model-agnostic approach that models interactions between basins using only the base model's own sampled outputs, hidden states, and derived evidence. Most direct correction strategies fail; ARBITER instead uses conservative additive evidence on top of consensus. In its simplest parameter-free form, ARBITER-Δ adds same-model evidence to the majority prior, while ARBITER-Enc augments this with bounded residual signals from hidden states over complete solutions. On GSM8K with Qwen3-4B, consensus over K=24 samples achieves around the mid-94% range, while a same-pool top-2 oracle reaches around the mid-96% range. ARBITER recovers a subset of these cases using zero external information. Across three model families and three math benchmarks, it yields consistent gains with no net-negative cases; for example, on Llama-3.1-8B MMLU-HS-Math, it improves accuracy from the mid-78% range to the mid-82% range, recovering about 22% of the available oracle headroom, indicating that this headroom can be partially recovered from the sample pool itself.
MooER: LLM-based Speech Recognition and Translation Models from Moore Threads
Aug 09, 2024In this paper, we present MooER, a LLM-based large-scale automatic speech recognition (ASR) / automatic speech translation (AST) model of Moore Threads. A 5000h pseudo labeled dataset containing open source and self collected speech data is used for training. We achieve performance comparable to other open source models trained with up to hundreds of thousands of hours of labeled speech data. Meanwhile, experiments conducted on Covost2 Zh2en testset suggest that our model outperforms other open source Speech LLMs. A BLEU score of 25.2 can be obtained. The main contributions of this paper are summarized as follows. First, this paper presents a training strategy for encoders and LLMs on speech related tasks (including ASR and AST) using a small size of pseudo labeled data without any extra manual annotation and selection. Second, we release our ASR and AST models and plan to open-source our training code and strategy in the near future. Moreover, a model trained on 8wh scale training data is planned to be released later on.
Building a digital twin of EDFA: a grey-box modeling approach
Jul 13, 2023



To enable intelligent and self-driving optical networks, high-accuracy physical layer models are required. The dynamic wavelength-dependent gain effects of non-constant-pump erbium-doped fiber amplifiers (EDFAs) remain a crucial problem in terms of modeling, as it determines optical-to-signal noise ratio as well as the magnitude of fiber nonlinearities. Black-box data-driven models have been widely studied, but it requires a large size of data for training and suffers from poor generalizability. In this paper, we derive the gain spectra of EDFAs as a simple univariable linear function, and then based on it we propose a grey-box EDFA gain modeling scheme. Experimental results show that for both automatic gain control (AGC) and automatic power control (APC) EDFAs, our model built with 8 data samples can achieve better performance than the neural network (NN) based model built with 900 data samples, which means the required data size for modeling can be reduced by at least two orders of magnitude. Moreover, in the experiment the proposed model demonstrates superior generalizability to unseen scenarios since it is based on the underlying physics of EDFAs. The results indicate that building a customized digital twin of each EDFA in optical networks become feasible, which is essential especially for next generation multi-band network operations.
Token-level Speaker Change Detection Using Speaker Difference and Speech Content via Continuous Integrate-and-fire
Nov 17, 2022In multi-talker scenarios such as meetings and conversations, speech processing systems are usually required to segment the audio and then transcribe each segmentation. These two stages are addressed separately by speaker change detection (SCD) and automatic speech recognition (ASR). Most previous SCD systems rely solely on speaker information and ignore the importance of speech content. In this paper, we propose a novel SCD system that considers both cues of speaker difference and speech content. These two cues are converted into token-level representations by the continuous integrate-and-fire (CIF) mechanism and then combined for detecting speaker changes on the token acoustic boundaries. We evaluate the performance of our approach on a public real-recorded meeting dataset, AISHELL-4. The experiment results show that our method outperforms a competitive frame-level baseline system by 2.45% equal coverage-purity (ECP). In addition, we demonstrate the importance of speech content and speaker difference to the SCD task, and the advantages of conducting SCD on the token acoustic boundaries compared with conducting SCD frame by frame.
Sequence-level Speaker Change Detection with Difference-based Continuous Integrate-and-fire
Jun 27, 2022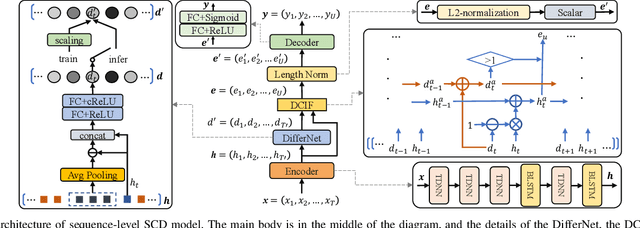
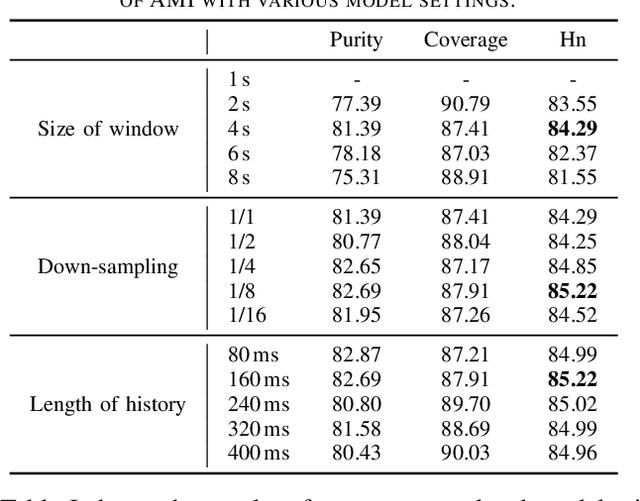
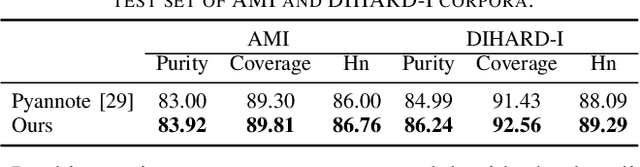
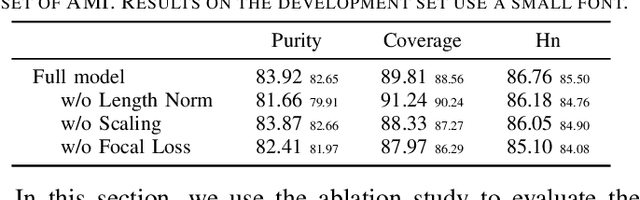
Speaker change detection is an important task in multi-party interactions such as meetings and conversations. In this paper, we address the speaker change detection task from the perspective of sequence transduction. Specifically, we propose a novel encoder-decoder framework that directly converts the input feature sequence to the speaker identity sequence. The difference-based continuous integrate-and-fire mechanism is designed to support this framework. It detects speaker changes by integrating the speaker difference between the encoder outputs frame-by-frame and transfers encoder outputs to segment-level speaker embeddings according to the detected speaker changes. The whole framework is supervised by the speaker identity sequence, a weaker label than the precise speaker change points. The experiments on the AMI and DIHARD-I corpora show that our sequence-level method consistently outperforms a strong frame-level baseline that uses the precise speaker change labels.
Improving End-to-End Contextual Speech Recognition with Fine-grained Contextual Knowledge Selection
Jan 30, 2022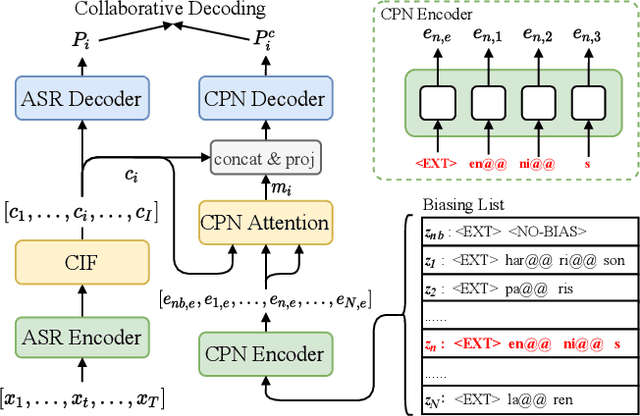
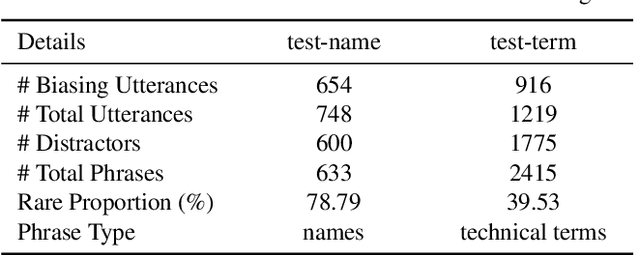
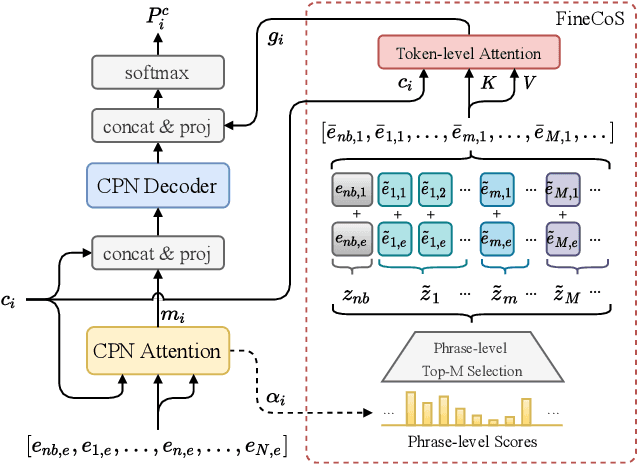
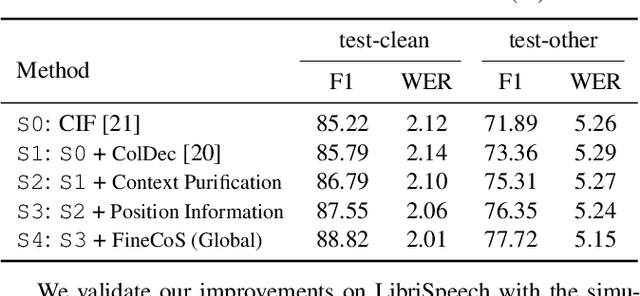
Nowadays, most methods in end-to-end contextual speech recognition bias the recognition process towards contextual knowledge. Since all-neural contextual biasing methods rely on phrase-level contextual modeling and attention-based relevance modeling, they may encounter confusion between similar context-specific phrases, which hurts predictions at the token level. In this work, we focus on mitigating confusion problems with fine-grained contextual knowledge selection (FineCoS). In FineCoS, we introduce fine-grained knowledge to reduce the uncertainty of token predictions. Specifically, we first apply phrase selection to narrow the range of phrase candidates, and then conduct token attention on the tokens in the selected phrase candidates. Moreover, we re-normalize the attention weights of most relevant phrases in inference to obtain more focused phrase-level contextual representations, and inject position information to better discriminate phrases or tokens. On LibriSpeech and an in-house 160,000-hour dataset, we explore the proposed methods based on a controllable all-neural biasing method, collaborative decoding (ColDec). The proposed methods provide at most 6.1% relative word error rate reduction on LibriSpeech and 16.4% relative character error rate reduction on the in-house dataset over ColDec.
Improving Pseudo-label Training For End-to-end Speech Recognition Using Gradient Mask
Oct 08, 2021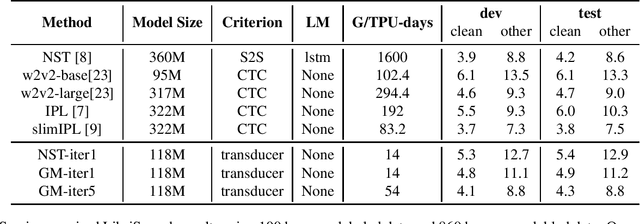
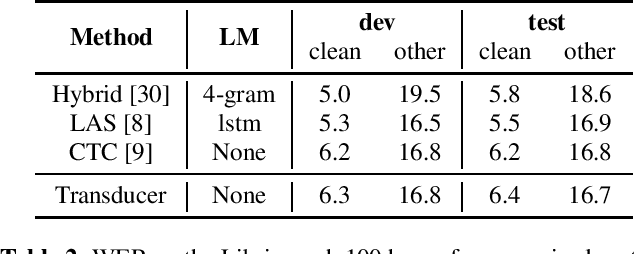
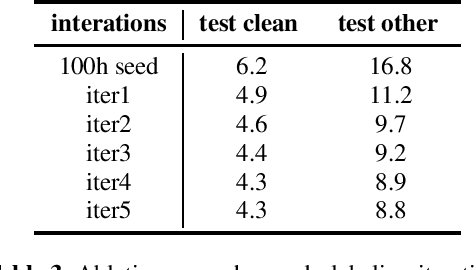
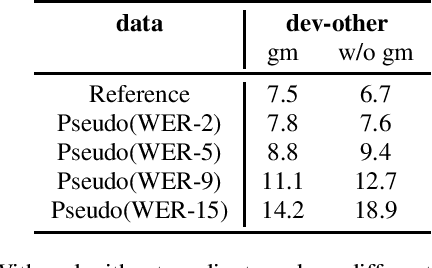
In the recent trend of semi-supervised speech recognition, both self-supervised representation learning and pseudo-labeling have shown promising results. In this paper, we propose a novel approach to combine their ideas for end-to-end speech recognition model. Without any extra loss function, we utilize the Gradient Mask to optimize the model when training on pseudo-label. This method forces the speech recognition model to predict from the masked input to learn strong acoustic representation and make training robust to label noise. In our semi-supervised experiments, the method can improve the model performance when training on pseudo-label and our method achieved competitive results comparing with other semi-supervised approaches on the Librispeech 100 hours experiments.
Application of Machine Learning in Fiber Nonlinearity Modeling and Monitoring for Elastic Optical Networks
Nov 23, 2018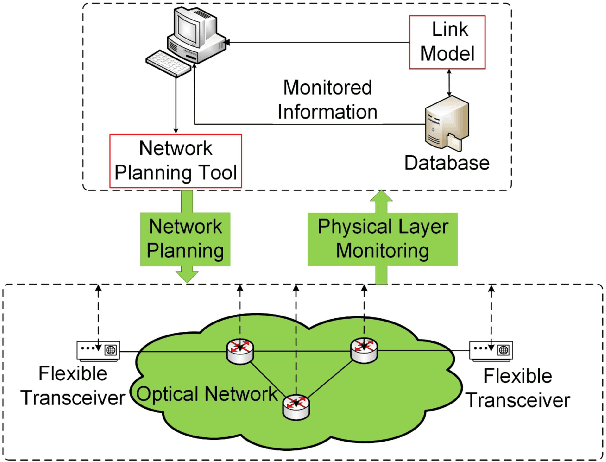
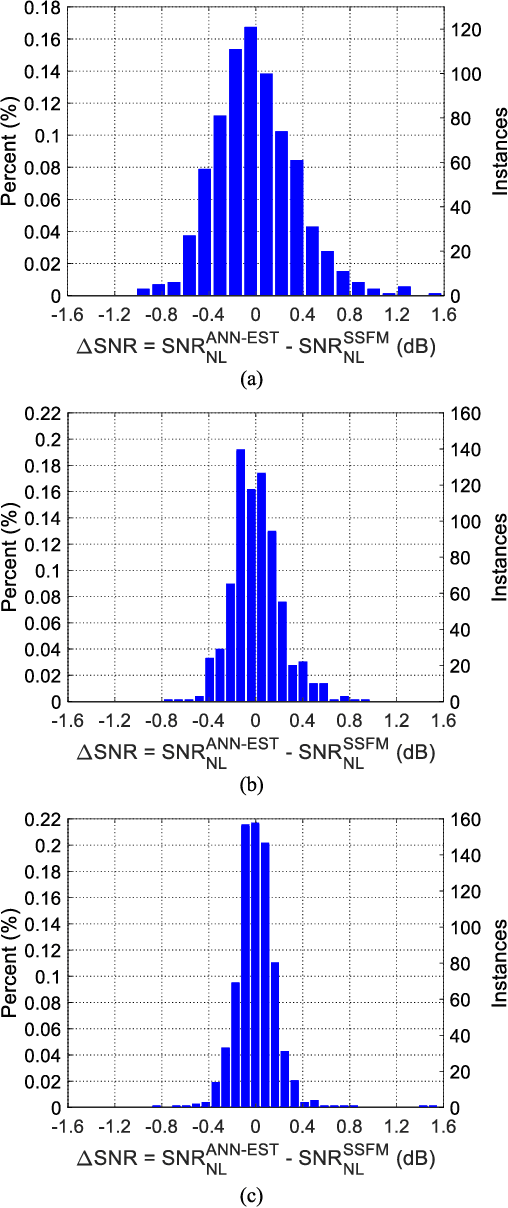
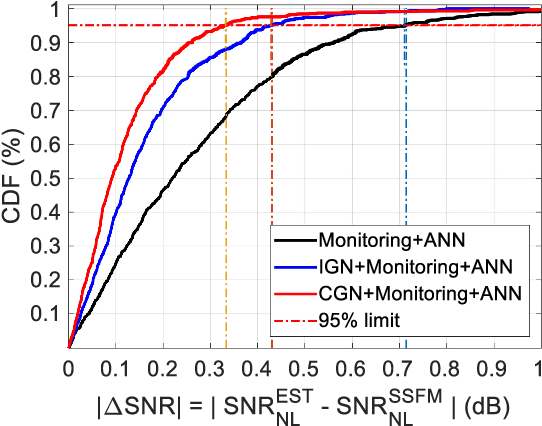
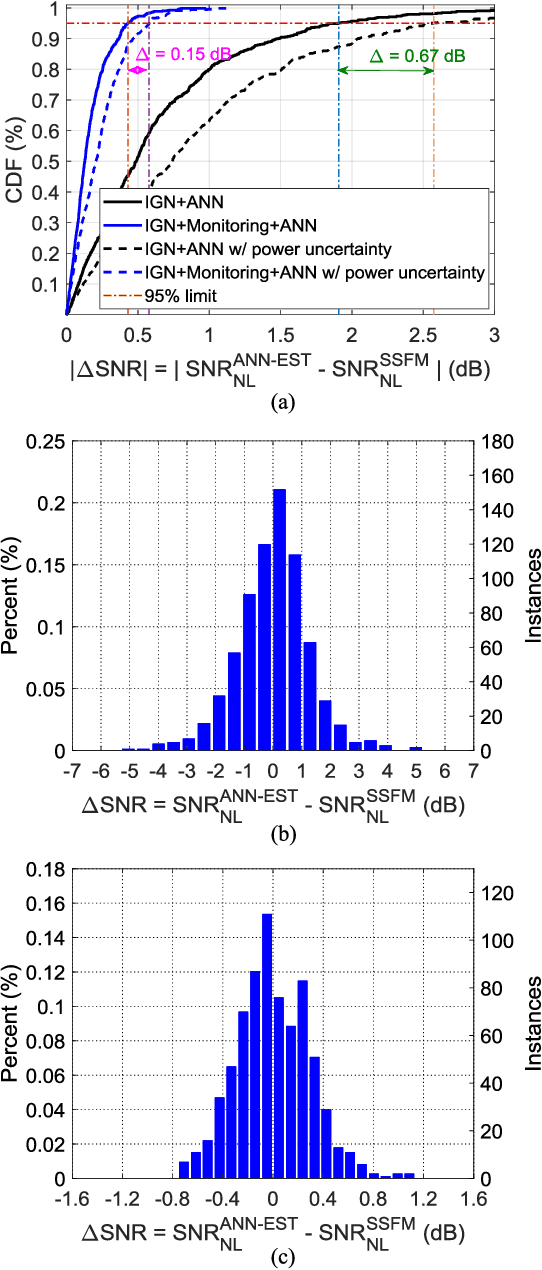
Fiber nonlinear interference (NLI) modeling and monitoring are the key building blocks to support elastic optical networks (EONs). In the past, they were normally developed and investigated separately. Moreover, the accuracy of the previously proposed methods still needs to be improved for heterogenous dynamic optical networks. In this paper, we present the application of machine learning (ML) in NLI modeling and monitoring. In particular, we first propose to use ML approaches to calibrate the errors of current fiber nonlinearity models. The Gaussian-noise (GN) model is used as an illustrative example, and significant improvement is demonstrated with the aid of an artificial neural network (ANN). Further, we propose to use ML to combine the modeling and monitoring schemes for a better estimation of NLI variance. Extensive simulations with 1603 links are conducted to evaluate and analyze the performance of various schemes, and the superior performance of the ML-aided combination of modeling and monitoring is demonstrated.