 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEST-RQ: Next Token Prediction for Speech Self-Supervised Pre-Training
Sep 13, 2024



Speech self-supervised pre-training can effectively improve the performance of downstream tasks. However, previous self-supervised learning (SSL) methods for speech, such as HuBERT and BEST-RQ, focus on utilizing non-causal encoders with bidirectional context, and lack sufficient support for downstream streaming models. To address this issue, we introduce the next token prediction based speech pre-training method with random-projection quantizer (NEST-RQ). NEST-RQ employs causal encoders with only left context and uses next token prediction (NTP) as the training task. On the large-scale dataset, compared to BEST-RQ, the proposed NEST-RQ achieves comparable performance on non-streaming automatic speech recognition (ASR) and better performance on streaming ASR. We also conduct analytical experiments in terms of the future context size of streaming ASR, the codebook quality of SSL and the model size of the encoder. In summary, the paper demonstrates the feasibility of the NTP in speech SSL and provides empirical evidence and insights for speech SSL research.
Seed-ASR: Understanding Diverse Speech and Contexts with LLM-based Speech Recognition
Jul 05, 2024



Modern automatic speech recognition (ASR) model is required to accurately transcribe diverse speech signals (from different domains, languages, accents, etc) given the specific contextual information in various application scenarios. Classic end-to-end models fused with extra language models perform well, but mainly in data matching scenarios and are gradually approaching a bottleneck. In this work, we introduce Seed-ASR, a large language model (LLM) based speech recognition model. Seed-ASR is developed based on the framework of audio conditioned LLM (AcLLM), leveraging the capabilities of LLMs by inputting continuous speech representations together with contextual information into the LLM. Through stage-wise large-scale training and the elicitation of context-aware capabilities in LLM, Seed-ASR demonstrates significant improvement over end-to-end models on comprehensive evaluation sets, including multiple domains, accents/dialects and languages. Additionally, Seed-ASR can be further deployed to support specific needs in various scenarios without requiring extra language models. Compared to recently released large ASR models, Seed-ASR achieves 10%-40% reduction in word (or character, for Chinese) error rates on Chinese and English public test sets, further demonstrating its powerful performance.
ViLaS: Integrating Vision and Language into Automatic Speech Recognition
May 31, 2023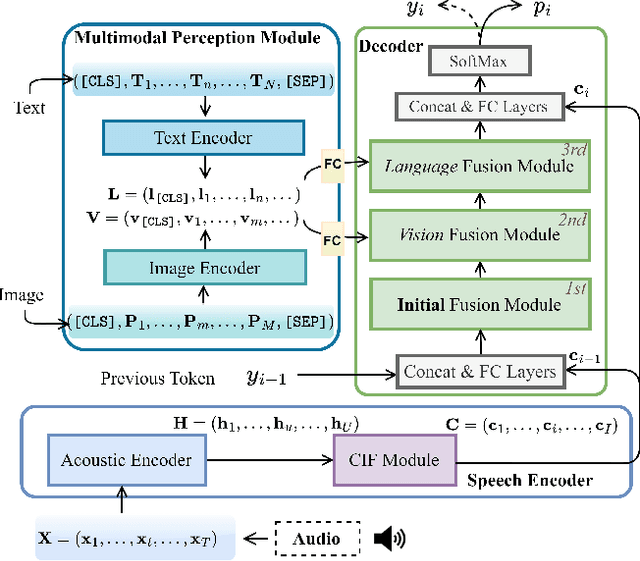
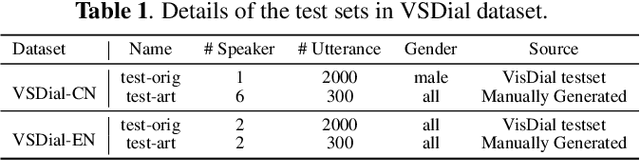
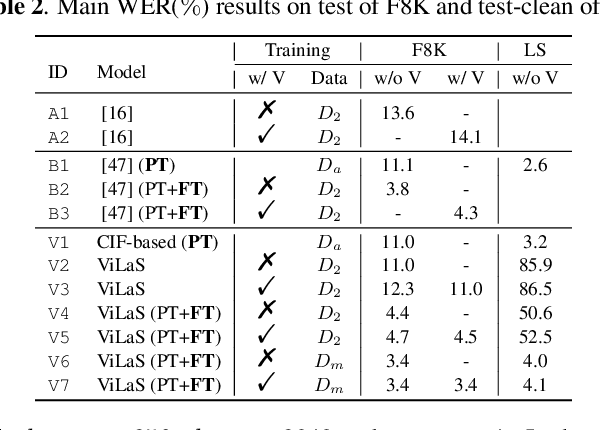
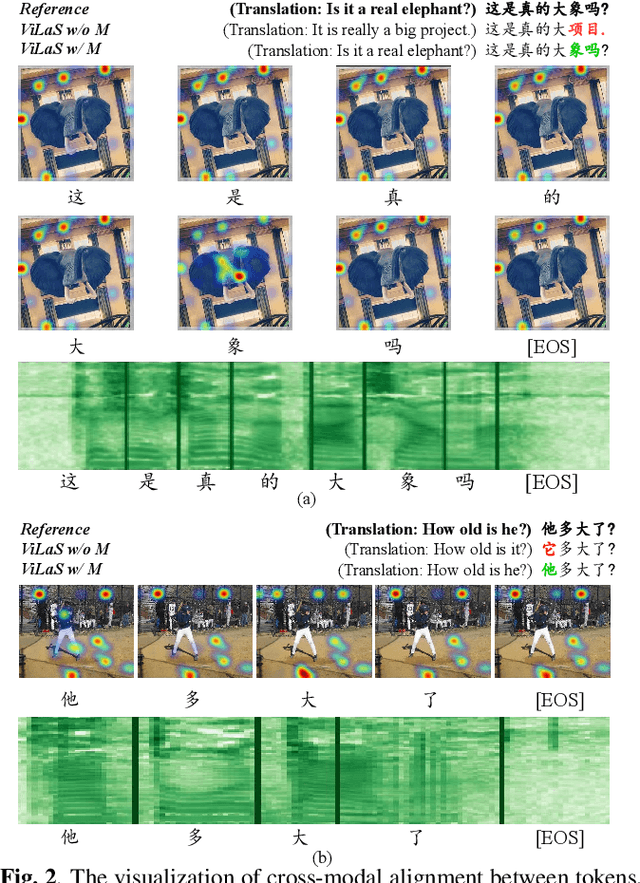
Employing additional multimodal information to improve automatic speech recognition (ASR) performance has been proven effective in previous works. However, many of these works focus only on the utilization of visual cues from human lip motion. In fact, context-dependent visual and linguistic cues can also be used to improve ASR performance in many scenarios. In this paper, we first propose a multimodal ASR model (ViLaS) that can simultaneously or separately integrate visual and linguistic cues to help recognize the input speech, and introduce a training strategy that can improve performance in modal-incomplete test scenarios. Then, we create a multimodal ASR dataset (VSDial) with visual and linguistic cues to explore the effects of integrating vision and language. Finally, we report empirical results on the public Flickr8K and self-constructed VSDial datasets, investigate cross-modal fusion schemes, and analyze fine-grained cross-modal alignment on VSDial.
X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages
May 10, 2023
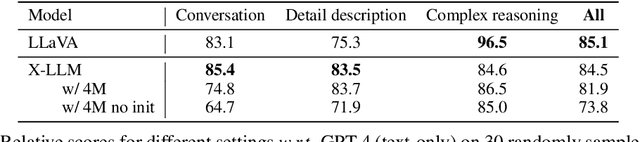


Large language models (LLMs) have demonstrated remarkable language abilities. GPT-4, based on advanced LLMs, exhibits extraordinary multimodal capabilities beyond previous visual language models. We attribute this to the use of more advanced LLMs compared with previous multimodal models. Unfortunately, the model architecture and training strategies of GPT-4 are unknown. To endow LLMs with multimodal capabilities, we propose X-LLM, which converts Multi-modalities (images, speech, videos) into foreign languages using X2L interfaces and inputs them into a large Language model (ChatGLM). Specifically, X-LLM aligns multiple frozen single-modal encoders and a frozen LLM using X2L interfaces, where ``X'' denotes multi-modalities such as image, speech, and videos, and ``L'' denotes languages. X-LLM's training consists of three stages: (1) Converting Multimodal Information: The first stage trains each X2L interface to align with its respective single-modal encoder separately to convert multimodal information into languages. (2) Aligning X2L representations with the LLM: single-modal encoders are aligned with the LLM through X2L interfaces independently. (3) Integrating multiple modalities: all single-modal encoders are aligned with the LLM through X2L interfaces to integrate multimodal capabilities into the LLM. Our experiments show that X-LLM demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 84.5\% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. And we also conduct quantitative tests on using LLM for ASR and multimodal ASR, hoping to promote the era of LLM-based speech recognition.
Matching-based Term Semantics Pre-training for Spoken Patient Query Understanding
Mar 02, 2023
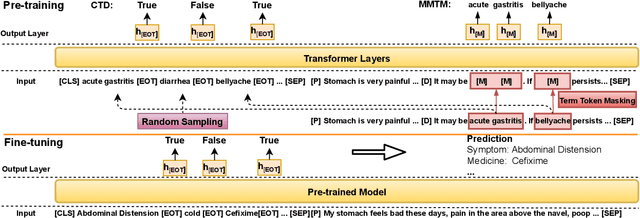
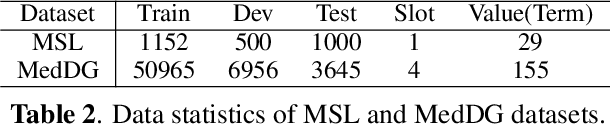
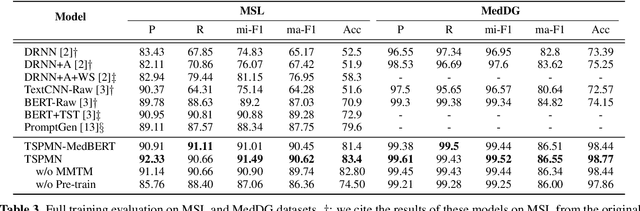
Medical Slot Filling (MSF) task aims to convert medical queries into structured information, playing an essential role in diagnosis dialogue systems. However, the lack of sufficient term semantics learning makes existing approaches hard to capture semantically identical but colloquial expressions of terms in medical conversations. In this work, we formalize MSF into a matching problem and propose a Term Semantics Pre-trained Matching Network (TSPMN) that takes both terms and queries as input to model their semantic interaction. To learn term semantics better, we further design two self-supervised objectives, including Contrastive Term Discrimination (CTD) and Matching-based Mask Term Modeling (MMTM). CTD determines whether it is the masked term in the dialogue for each given term, while MMTM directly predicts the masked ones. Experimental results on two Chinese benchmarks show that TSPMN outperforms strong baselines, especially in few-shot settings.
Complex Dynamic Neurons Improved Spiking Transformer Network for Efficient Automatic Speech Recognition
Feb 02, 2023The spiking neural network (SNN) using leaky-integrated-and-fire (LIF) neurons has been commonly used in automatic speech recognition (ASR) tasks. However, the LIF neuron is still relatively simple compared to that in the biological brain. Further research on more types of neurons with different scales of neuronal dynamics is necessary. Here we introduce four types of neuronal dynamics to post-process the sequential patterns generated from the spiking transformer to get the complex dynamic neuron improved spiking transformer neural network (DyTr-SNN). We found that the DyTr-SNN could handle the non-toy automatic speech recognition task well, representing a lower phoneme error rate, lower computational cost, and higher robustness. These results indicate that the further cooperation of SNNs and neural dynamics at the neuron and network scales might have much in store for the future, especially on the ASR tasks.
Knowledge Transfer from Pre-trained Language Models to Cif-based Speech Recognizers via Hierarchical Distillation
Jan 30, 2023
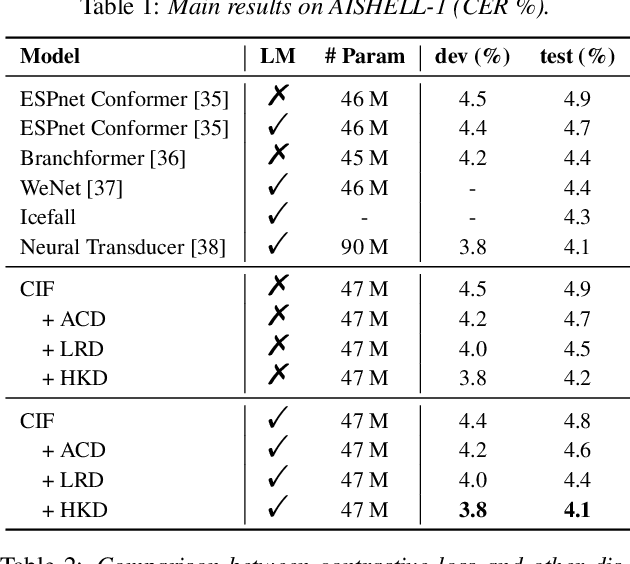

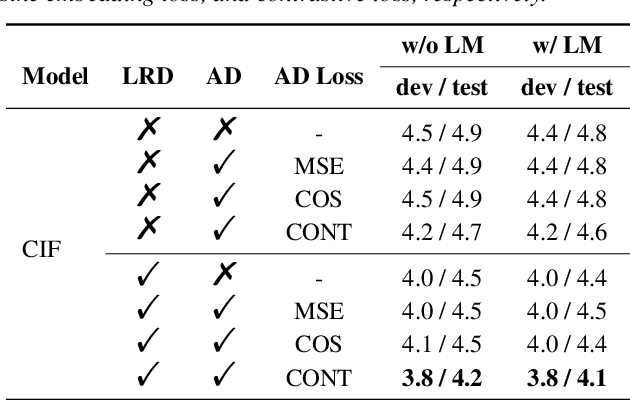
Large-scale pre-trained language models (PLMs) with powerful language modeling capabilities have been widely used in natural language processing. For automatic speech recognition (ASR), leveraging PLMs to improve performance has also become a promising research trend. However, most previous works may suffer from the inflexible sizes and structures of PLMs, along with the insufficient utilization of the knowledge in PLMs. To alleviate these problems, we propose the hierarchical knowledge distillation on the continuous integrate-and-fire (CIF) based ASR models. Specifically, we distill the knowledge from PLMs to the ASR model by applying cross-modal distillation with contrastive loss at the acoustic level and applying distillation with regression loss at the linguistic level. On the AISHELL-1 dataset, our method achieves 15% relative error rate reduction over the original CIF-based model and achieves comparable performance (3.8%/4.1% on dev/test) to the state-of-the-art model.
VLP: A Survey on Vision-Language Pre-training
Feb 21, 2022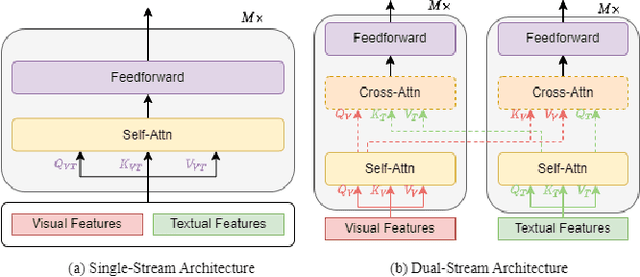
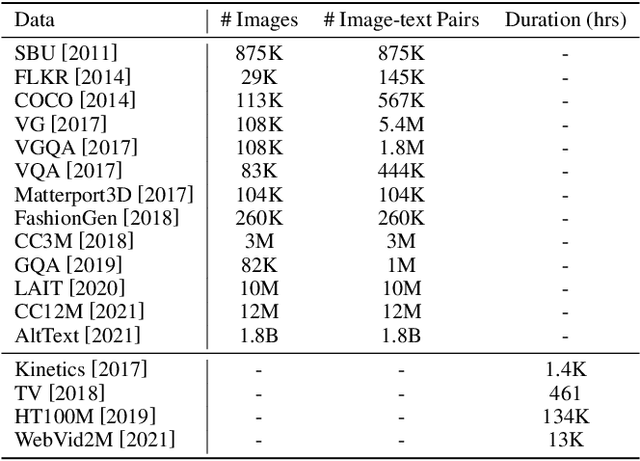
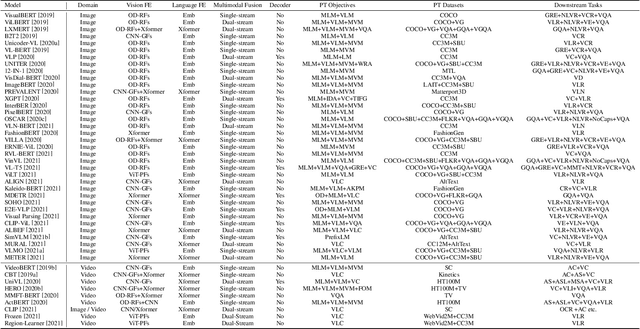
In the past few years, the emergence of pre-training models has brought uni-modal fields such as computer vision (CV) and natural language processing (NLP) to a new era. Substantial works have shown they are beneficial for downstream uni-modal tasks and avoid training a new model from scratch. So can such pre-trained models be applied to multi-modal tasks? Researchers have explored this problem and made significant progress. This paper surveys recent advances and new frontiers in vision-language pre-training (VLP), including image-text and video-text pre-training. To give readers a better overall grasp of VLP, we first review its recent advances from five aspects: feature extraction, model architecture, pre-training objectives, pre-training datasets, and downstream tasks. Then, we summarize the specific VLP models in detail. Finally, we discuss the new frontiers in VLP. To the best of our knowledge, this is the first survey on VLP. We hope that this survey can shed light on future research in the VLP field.
Improving End-to-End Contextual Speech Recognition with Fine-grained Contextual Knowledge Selection
Jan 30, 2022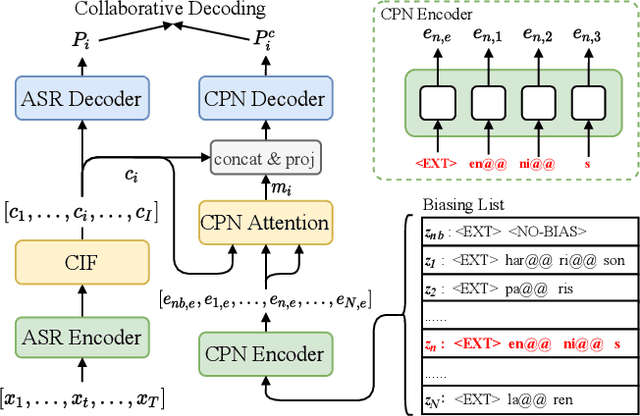
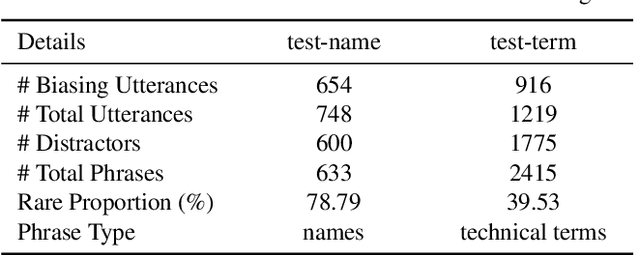
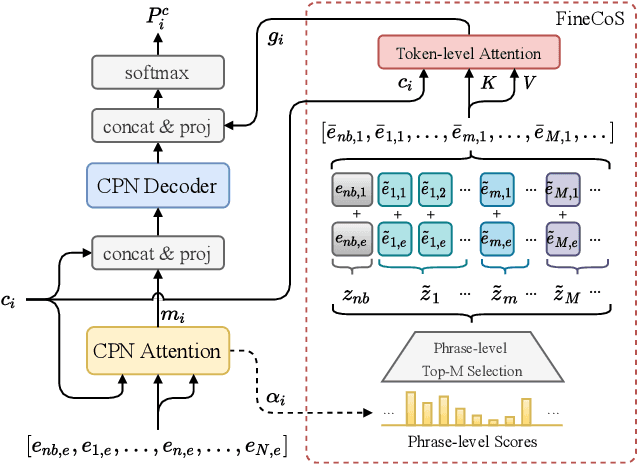
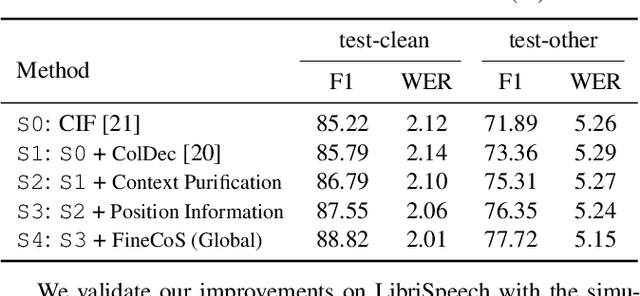
Nowadays, most methods in end-to-end contextual speech recognition bias the recognition process towards contextual knowledge. Since all-neural contextual biasing methods rely on phrase-level contextual modeling and attention-based relevance modeling, they may encounter confusion between similar context-specific phrases, which hurts predictions at the token level. In this work, we focus on mitigating confusion problems with fine-grained contextual knowledge selection (FineCoS). In FineCoS, we introduce fine-grained knowledge to reduce the uncertainty of token predictions. Specifically, we first apply phrase selection to narrow the range of phrase candidates, and then conduct token attention on the tokens in the selected phrase candidates. Moreover, we re-normalize the attention weights of most relevant phrases in inference to obtain more focused phrase-level contextual representations, and inject position information to better discriminate phrases or tokens. On LibriSpeech and an in-house 160,000-hour dataset, we explore the proposed methods based on a controllable all-neural biasing method, collaborative decoding (ColDec). The proposed methods provide at most 6.1% relative word error rate reduction on LibriSpeech and 16.4% relative character error rate reduction on the in-house dataset over ColDec.
cif-based collaborative decoding for end-to-end contextual speech recognition
Dec 17, 2020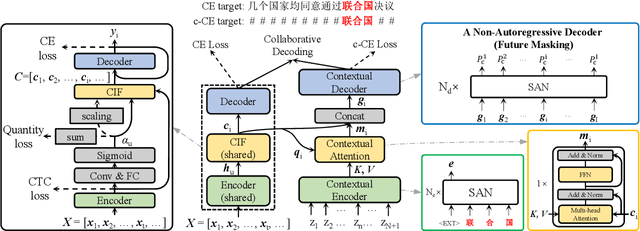
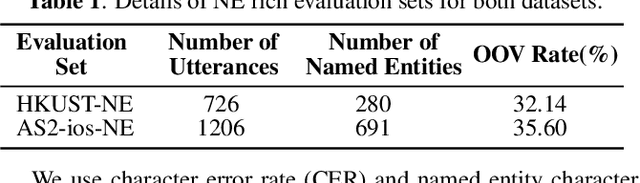
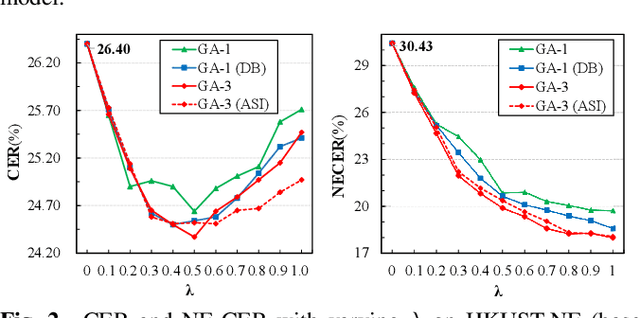
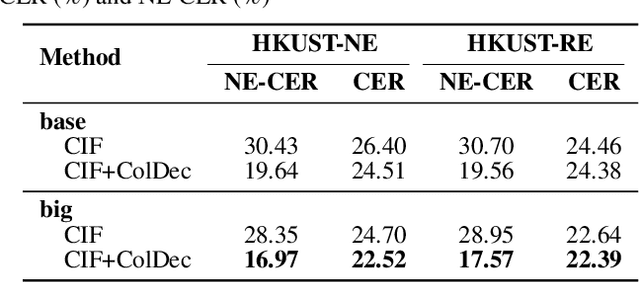
End-to-end (E2E) models have achieved promising results on multiple speech recognition benchmarks, and shown the potential to become the mainstream. However, the unified structure and the E2E training hamper injecting contextual information into them for contextual biasing. Though contextual LAS (CLAS) gives an excellent all-neural solution, the degree of biasing to given context information is not explicitly controllable. In this paper, we focus on incorporating context information into the continuous integrate-and-fire (CIF) based model that supports contextual biasing in a more controllable fashion. Specifically, an extra context processing network is introduced to extract contextual embeddings, integrate acoustically relevant context information and decode the contextual output distribution, thus forming a collaborative decoding with the decoder of the CIF-based model. Evaluated on the named entity rich evaluation sets of HKUST/AISHELL-2, our method brings relative character error rate (CER) reduction of 8.83%/21.13% and relative named entity character error rate (NE-CER) reduction of 40.14%/51.50% when compared with a strong baseline. Besides, it keeps the performance on original evaluation set without degradation.