 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiologically-Plausible Topology Improved Spiking Actor Network for Efficient Deep Reinforcement Learning
Mar 29, 2024The success of Deep Reinforcement Learning (DRL) is largely attributed to utilizing Artificial Neural Networks (ANNs) as function approximators. Recent advances in neuroscience have unveiled that the human brain achieves efficient reward-based learning, at least by integrating spiking neurons with spatial-temporal dynamics and network topologies with biologically-plausible connectivity patterns. This integration process allows spiking neurons to efficiently combine information across and within layers via nonlinear dendritic trees and lateral interactions. The fusion of these two topologies enhances the network's information-processing ability, crucial for grasping intricate perceptions and guiding decision-making procedures. However, ANNs and brain networks differ significantly. ANNs lack intricate dynamical neurons and only feature inter-layer connections, typically achieved by direct linear summation, without intra-layer connections. This limitation leads to constrained network expressivity. To address this, we propose a novel alternative for function approximator, the Biologically-Plausible Topology improved Spiking Actor Network (BPT-SAN), tailored for efficient decision-making in DRL. The BPT-SAN incorporates spiking neurons with intricate spatial-temporal dynamics and introduces intra-layer connections, enhancing spatial-temporal state representation and facilitating more precise biological simulations. Diverging from the conventional direct linear weighted sum, the BPT-SAN models the local nonlinearities of dendritic trees within the inter-layer connections. For the intra-layer connections, the BPT-SAN introduces lateral interactions between adjacent neurons, integrating them into the membrane potential formula to ensure accurate spike firing.
Fourier or Wavelet bases as counterpart self-attention in spikformer for efficient visual classification
Mar 27, 2024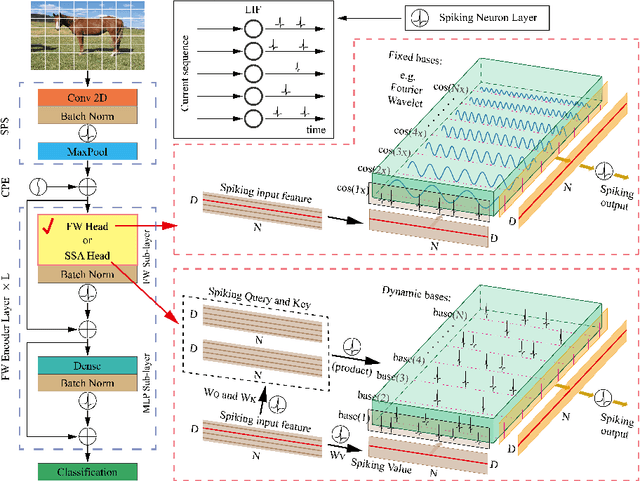


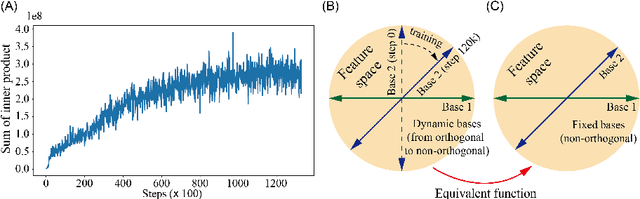
Energy-efficient spikformer has been proposed by integrating the biologically plausible spiking neural network (SNN) and artificial Transformer, whereby the Spiking Self-Attention (SSA) is used to achieve both higher accuracy and lower computational cost. However, it seems that self-attention is not always necessary, especially in sparse spike-form calculation manners. In this paper, we innovatively replace vanilla SSA (using dynamic bases calculating from Query and Key) with spike-form Fourier Transform, Wavelet Transform, and their combinations (using fixed triangular or wavelets bases), based on a key hypothesis that both of them use a set of basis functions for information transformation. Hence, the Fourier-or-Wavelet-based spikformer (FWformer) is proposed and verified in visual classification tasks, including both static image and event-based video datasets. The FWformer can achieve comparable or even higher accuracies ($0.4\%$-$1.5\%$), higher running speed ($9\%$-$51\%$ for training and $19\%$-$70\%$ for inference), reduced theoretical energy consumption ($20\%$-$25\%$), and reduced GPU memory usage ($4\%$-$26\%$), compared to the standard spikformer. Our result indicates the continuous refinement of new Transformers, that are inspired either by biological discovery (spike-form), or information theory (Fourier or Wavelet Transform), is promising.
Machine Translation Testing via Syntactic Tree Pruning
Jan 01, 2024Machine translation systems have been widely adopted in our daily life, making life easier and more convenient. Unfortunately, erroneous translations may result in severe consequences, such as financial losses. This requires to improve the accuracy and the reliability of machine translation systems. However, it is challenging to test machine translation systems because of the complexity and intractability of the underlying neural models. To tackle these challenges, we propose a novel metamorphic testing approach by syntactic tree pruning (STP) to validate machine translation systems. Our key insight is that a pruned sentence should have similar crucial semantics compared with the original sentence. Specifically, STP (1) proposes a core semantics-preserving pruning strategy by basic sentence structure and dependency relations on the level of syntactic tree representation; (2) generates source sentence pairs based on the metamorphic relation; (3) reports suspicious issues whose translations break the consistency property by a bag-of-words model. We further evaluate STP on two state-of-the-art machine translation systems (i.e., Google Translate and Bing Microsoft Translator) with 1,200 source sentences as inputs. The results show that STP can accurately find 5,073 unique erroneous translations in Google Translate and 5,100 unique erroneous translations in Bing Microsoft Translator (400% more than state-of-the-art techniques), with 64.5% and 65.4% precision, respectively. The reported erroneous translations vary in types and more than 90% of them cannot be found by state-of-the-art techniques. There are 9,393 erroneous translations unique to STP, which is 711.9% more than state-of-the-art techniques. Moreover, STP is quite effective to detect translation errors for the original sentences with a recall reaching 74.0%, improving state-of-the-art techniques by 55.1% on average.
Attention-free Spikformer: Mixing Spike Sequences with Simple Linear Transforms
Aug 17, 2023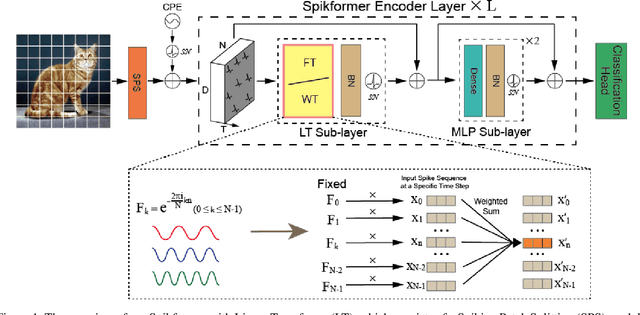

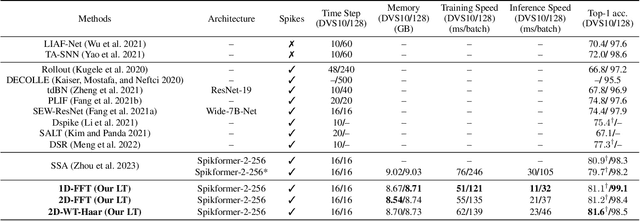
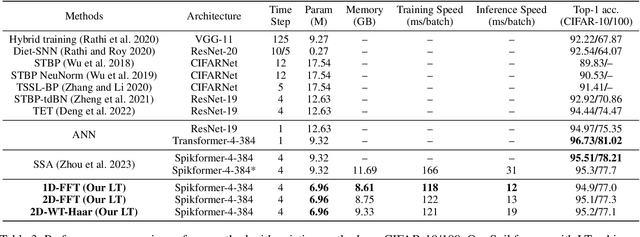
By integrating the self-attention capability and the biological properties of Spiking Neural Networks (SNNs), Spikformer applies the flourishing Transformer architecture to SNNs design. It introduces a Spiking Self-Attention (SSA) module to mix sparse visual features using spike-form Query, Key, and Value, resulting in the State-Of-The-Art (SOTA) performance on numerous datasets compared to previous SNN-like frameworks. In this paper, we demonstrate that the Spikformer architecture can be accelerated by replacing the SSA with an unparameterized Linear Transform (LT) such as Fourier and Wavelet transforms. These transforms are utilized to mix spike sequences, reducing the quadratic time complexity to log-linear time complexity. They alternate between the frequency and time domains to extract sparse visual features, showcasing powerful performance and efficiency. We conduct extensive experiments on image classification using both neuromorphic and static datasets. The results indicate that compared to the SOTA Spikformer with SSA, Spikformer with LT achieves higher Top-1 accuracy on neuromorphic datasets (i.e., CIFAR10-DVS and DVS128 Gesture) and comparable Top-1 accuracy on static datasets (i.e., CIFAR-10 and CIFAR-100). Furthermore, Spikformer with LT achieves approximately 29-51% improvement in training speed, 61-70% improvement in inference speed, and reduces memory usage by 4-26% due to not requiring learnable parameters.
Complex Dynamic Neurons Improved Spiking Transformer Network for Efficient Automatic Speech Recognition
Feb 02, 2023The spiking neural network (SNN) using leaky-integrated-and-fire (LIF) neurons has been commonly used in automatic speech recognition (ASR) tasks. However, the LIF neuron is still relatively simple compared to that in the biological brain. Further research on more types of neurons with different scales of neuronal dynamics is necessary. Here we introduce four types of neuronal dynamics to post-process the sequential patterns generated from the spiking transformer to get the complex dynamic neuron improved spiking transformer neural network (DyTr-SNN). We found that the DyTr-SNN could handle the non-toy automatic speech recognition task well, representing a lower phoneme error rate, lower computational cost, and higher robustness. These results indicate that the further cooperation of SNNs and neural dynamics at the neuron and network scales might have much in store for the future, especially on the ASR tasks.
Universal adversarial perturbation for remote sensing images
Feb 22, 2022
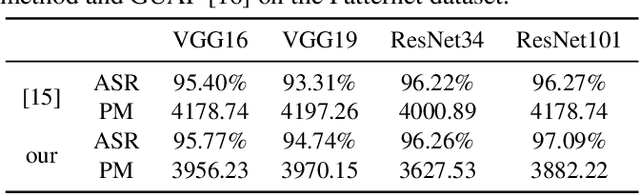
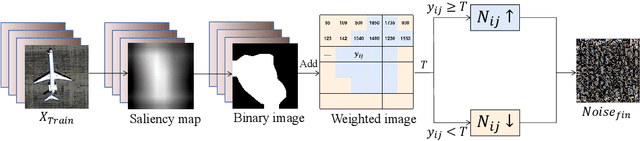
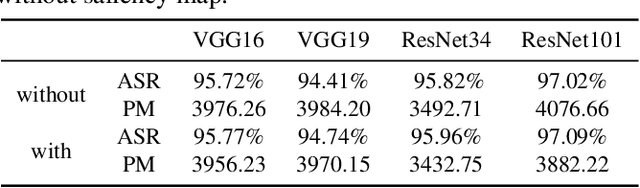
Recently, with the application of deep learning in the remote sensing image (RSI) field, the classification accuracy of the RSI has been greatly improved compared with traditional technology. However, even state-of-the-art object recognition convolutional neural networks are fooled by the universal adversarial perturbation (UAP). To verify that UAP makes the RSI classification model error classification, this paper proposes a novel method combining an encoder-decoder network with an attention mechanism. Firstly, the former can learn the distribution of perturbations better, then the latter is used to find the main regions concerned by the RSI classification model. Finally, the generated regions are used to fine-tune the perturbations making the model misclassified with fewer perturbations. The experimental results show that the UAP can make the RSI misclassify, and the attack success rate (ASR) of our proposed method on the RSI data set is as high as 97.35%.
PlantStereo: A Stereo Matching Benchmark for Plant Surface Dense Reconstruction
Nov 30, 2021


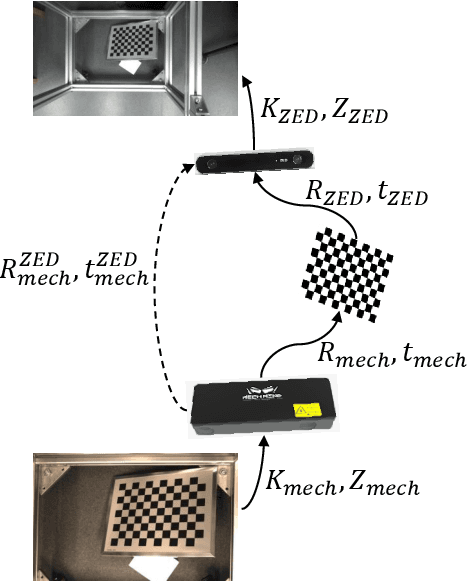
Stereo matching is an important task in computer vision which has drawn tremendous research attention for decades. While in terms of disparity accuracy, density and data size, public stereo datasets are difficult to meet the requirements of models. In this paper, we aim to address the issue between datasets and models and propose a large scale stereo dataset with high accuracy disparity ground truth named PlantStereo. We used a semi-automatic way to construct the dataset: after camera calibration and image registration, high accuracy disparity images can be obtained from the depth images. In total, PlantStereo contains 812 image pairs covering a diverse set of plants: spinach, tomato, pepper and pumpkin. We firstly evaluated our PlantStereo dataset on four different stereo matching methods. Extensive experiments on different models and plants show that compared with ground truth in integer accuracy, high accuracy disparity images provided by PlantStereo can remarkably improve the training effect of deep learning models. This paper provided a feasible and reliable method to realize plant surface dense reconstruction. The PlantStereo dataset and relative code are available at: https://www.github.com/wangqingyu985/PlantStereo