 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-free Spikformer: Mixing Spike Sequences with Simple Linear Transforms
Paper and Code
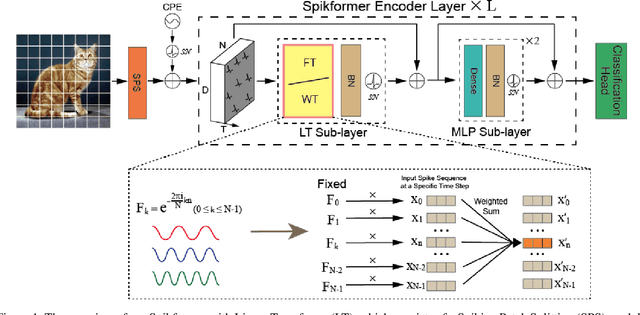

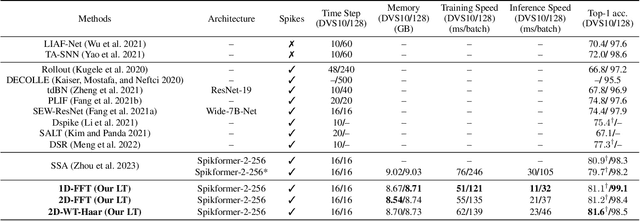
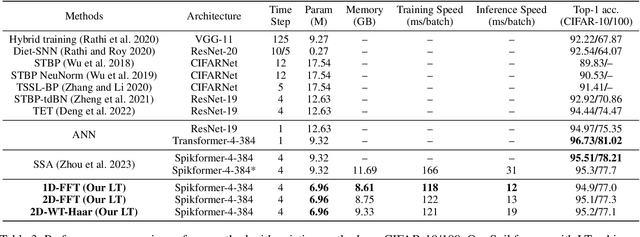
By integrating the self-attention capability and the biological properties of Spiking Neural Networks (SNNs), Spikformer applies the flourishing Transformer architecture to SNNs design. It introduces a Spiking Self-Attention (SSA) module to mix sparse visual features using spike-form Query, Key, and Value, resulting in the State-Of-The-Art (SOTA) performance on numerous datasets compared to previous SNN-like frameworks. In this paper, we demonstrate that the Spikformer architecture can be accelerated by replacing the SSA with an unparameterized Linear Transform (LT) such as Fourier and Wavelet transforms. These transforms are utilized to mix spike sequences, reducing the quadratic time complexity to log-linear time complexity. They alternate between the frequency and time domains to extract sparse visual features, showcasing powerful performance and efficiency. We conduct extensive experiments on image classification using both neuromorphic and static datasets. The results indicate that compared to the SOTA Spikformer with SSA, Spikformer with LT achieves higher Top-1 accuracy on neuromorphic datasets (i.e., CIFAR10-DVS and DVS128 Gesture) and comparable Top-1 accuracy on static datasets (i.e., CIFAR-10 and CIFAR-100). Furthermore, Spikformer with LT achieves approximately 29-51% improvement in training speed, 61-70% improvement in inference speed, and reduces memory usage by 4-26% due to not requiring learnable parameters.