 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier or Wavelet bases as counterpart self-attention in spikformer for efficient visual classification
Paper and Code
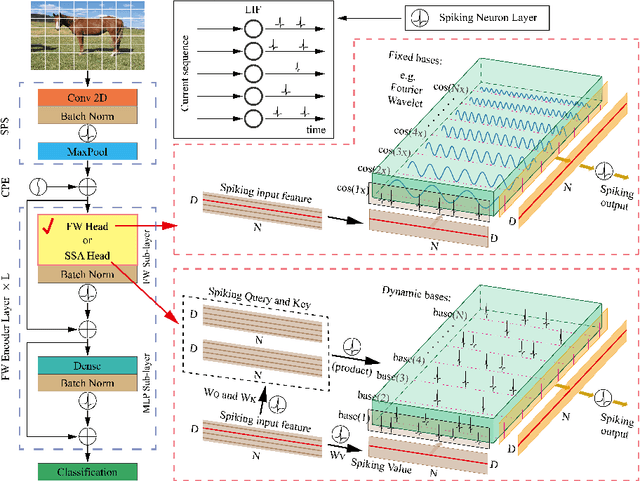


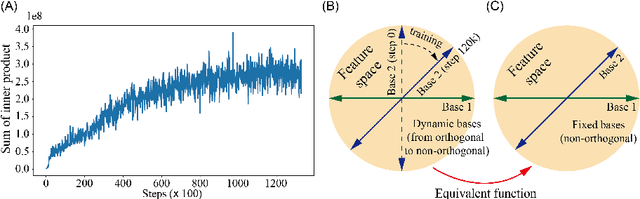
Energy-efficient spikformer has been proposed by integrating the biologically plausible spiking neural network (SNN) and artificial Transformer, whereby the Spiking Self-Attention (SSA) is used to achieve both higher accuracy and lower computational cost. However, it seems that self-attention is not always necessary, especially in sparse spike-form calculation manners. In this paper, we innovatively replace vanilla SSA (using dynamic bases calculating from Query and Key) with spike-form Fourier Transform, Wavelet Transform, and their combinations (using fixed triangular or wavelets bases), based on a key hypothesis that both of them use a set of basis functions for information transformation. Hence, the Fourier-or-Wavelet-based spikformer (FWformer) is proposed and verified in visual classification tasks, including both static image and event-based video datasets. The FWformer can achieve comparable or even higher accuracies ($0.4\%$-$1.5\%$), higher running speed ($9\%$-$51\%$ for training and $19\%$-$70\%$ for inference), reduced theoretical energy consumption ($20\%$-$25\%$), and reduced GPU memory usage ($4\%$-$26\%$), compared to the standard spikformer. Our result indicates the continuous refinement of new Transformers, that are inspired either by biological discovery (spike-form), or information theory (Fourier or Wavelet Transform), is promising.