 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLP: A Survey on Vision-Language Pre-training
Paper and Code
Feb 21, 2022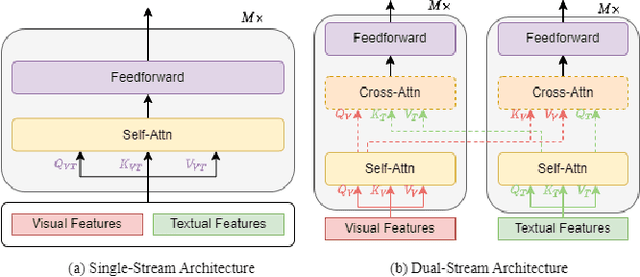
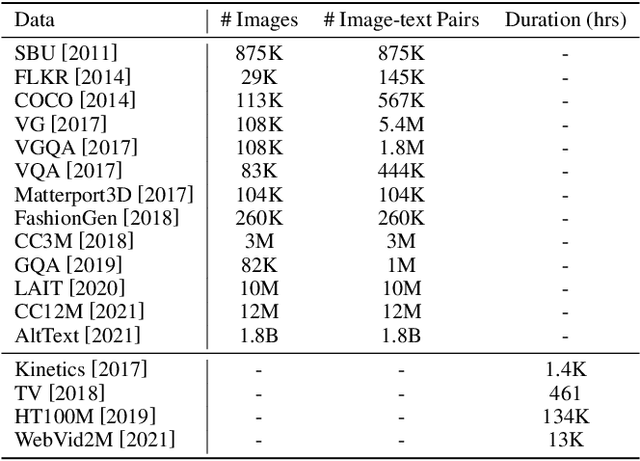
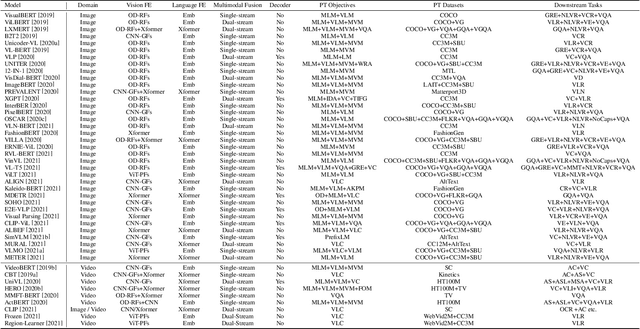
In the past few years, the emergence of pre-training models has brought uni-modal fields such as computer vision (CV) and natural language processing (NLP) to a new era. Substantial works have shown they are beneficial for downstream uni-modal tasks and avoid training a new model from scratch. So can such pre-trained models be applied to multi-modal tasks? Researchers have explored this problem and made significant progress. This paper surveys recent advances and new frontiers in vision-language pre-training (VLP), including image-text and video-text pre-training. To give readers a better overall grasp of VLP, we first review its recent advances from five aspects: feature extraction, model architecture, pre-training objectives, pre-training datasets, and downstream tasks. Then, we summarize the specific VLP models in detail. Finally, we discuss the new frontiers in VLP. To the best of our knowledge, this is the first survey on VLP. We hope that this survey can shed light on future research in the VLP field.