 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Transfer from Pre-trained Language Models to Cif-based Speech Recognizers via Hierarchical Distillation
Paper and Code

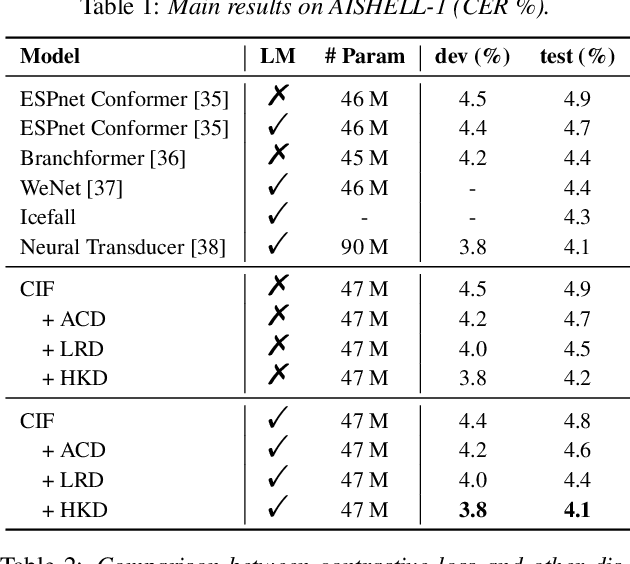

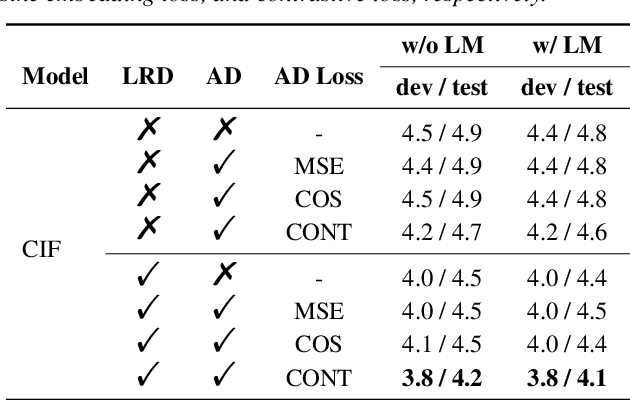
Large-scale pre-trained language models (PLMs) with powerful language modeling capabilities have been widely used in natural language processing. For automatic speech recognition (ASR), leveraging PLMs to improve performance has also become a promising research trend. However, most previous works may suffer from the inflexible sizes and structures of PLMs, along with the insufficient utilization of the knowledge in PLMs. To alleviate these problems, we propose the hierarchical knowledge distillation on the continuous integrate-and-fire (CIF) based ASR models. Specifically, we distill the knowledge from PLMs to the ASR model by applying cross-modal distillation with contrastive loss at the acoustic level and applying distillation with regression loss at the linguistic level. On the AISHELL-1 dataset, our method achieves 15% relative error rate reduction over the original CIF-based model and achieves comparable performance (3.8%/4.1% on dev/test) to the state-of-the-art model.