 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeTracker: Event-based Continuous Point Tracking for Video Frame Interpolation with Non-linear Motion
May 06, 2025Video frame interpolation (VFI) that leverages the bio-inspired event cameras as guidance has recently shown better performance and memory efficiency than the frame-based methods, thanks to the event cameras' advantages, such as high temporal resolution. A hurdle for event-based VFI is how to effectively deal with non-linear motion, caused by the dynamic changes in motion direction and speed within the scene. Existing methods either use events to estimate sparse optical flow or fuse events with image features to estimate dense optical flow. Unfortunately, motion errors often degrade the VFI quality as the continuous motion cues from events do not align with the dense spatial information of images in the temporal dimension. In this paper, we find that object motion is continuous in space, tracking local regions over continuous time enables more accurate identification of spatiotemporal feature correlations. In light of this, we propose a novel continuous point tracking-based VFI framework, named TimeTracker. Specifically, we first design a Scene-Aware Region Segmentation (SARS) module to divide the scene into similar patches. Then, a Continuous Trajectory guided Motion Estimation (CTME) module is proposed to track the continuous motion trajectory of each patch through events. Finally, intermediate frames at any given time are generated through global motion optimization and frame refinement. Moreover, we collect a real-world dataset that features fast non-linear motion. Extensive experiments show that our method outperforms prior arts in both motion estimation and frame interpolation quality.
X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages
May 10, 2023
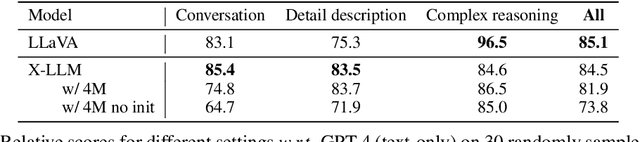


Large language models (LLMs) have demonstrated remarkable language abilities. GPT-4, based on advanced LLMs, exhibits extraordinary multimodal capabilities beyond previous visual language models. We attribute this to the use of more advanced LLMs compared with previous multimodal models. Unfortunately, the model architecture and training strategies of GPT-4 are unknown. To endow LLMs with multimodal capabilities, we propose X-LLM, which converts Multi-modalities (images, speech, videos) into foreign languages using X2L interfaces and inputs them into a large Language model (ChatGLM). Specifically, X-LLM aligns multiple frozen single-modal encoders and a frozen LLM using X2L interfaces, where ``X'' denotes multi-modalities such as image, speech, and videos, and ``L'' denotes languages. X-LLM's training consists of three stages: (1) Converting Multimodal Information: The first stage trains each X2L interface to align with its respective single-modal encoder separately to convert multimodal information into languages. (2) Aligning X2L representations with the LLM: single-modal encoders are aligned with the LLM through X2L interfaces independently. (3) Integrating multiple modalities: all single-modal encoders are aligned with the LLM through X2L interfaces to integrate multimodal capabilities into the LLM. Our experiments show that X-LLM demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 84.5\% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. And we also conduct quantitative tests on using LLM for ASR and multimodal ASR, hoping to promote the era of LLM-based speech recognition.