 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSD-BEV: Foreground Self-Distillation for Multi-view 3D Object Detection
Jul 14, 2024



Although multi-view 3D object detection based on the Bird's-Eye-View (BEV) paradigm has garnered widespread attention as an economical and deployment-friendly perception solution for autonomous driving, there is still a performance gap compared to LiDAR-based methods. In recent years, several cross-modal distillation methods have been proposed to transfer beneficial information from teacher models to student models, with the aim of enhancing performance. However, these methods face challenges due to discrepancies in feature distribution originating from different data modalities and network structures, making knowledge transfer exceptionally challenging. In this paper, we propose a Foreground Self-Distillation (FSD) scheme that effectively avoids the issue of distribution discrepancies, maintaining remarkable distillation effects without the need for pre-trained teacher models or cumbersome distillation strategies. Additionally, we design two Point Cloud Intensification (PCI) strategies to compensate for the sparsity of point clouds by frame combination and pseudo point assignment. Finally, we develop a Multi-Scale Foreground Enhancement (MSFE) module to extract and fuse multi-scale foreground features by predicted elliptical Gaussian heatmap, further improving the model's performance. We integrate all the above innovations into a unified framework named FSD-BEV. Extensive experiments on the nuScenes dataset exhibit that FSD-BEV achieves state-of-the-art performance, highlighting its effectiveness. The code and models are available at: https://github.com/CocoBoom/fsd-bev.
A comparative study on machine learning models combining with outlier detection and balanced sampling methods for credit scoring
Dec 25, 2021



Peer-to-peer (P2P) lending platforms have grown rapidly over the past decade as the network infrastructure has improved and the demand for personal lending has grown. Such platforms allow users to create peer-to-peer lending relationships without the help of traditional financial institutions. Assessing the borrowers' credit is crucial to reduce the default rate and benign development of P2P platforms. Building a personal credit scoring machine learning model can effectively predict whether users will repay loans on the P2P platform. And the handling of data outliers and sample imbalance problems can affect the final effect of machine learning models. There have been some studies on balanced sampling methods, but the effect of outlier detection methods and their combination with balanced sampling methods on the effectiveness of machine learning models has not been fully studied. In this paper, the influence of using different outlier detection methods and balanced sampling methods on commonly used machine learning models is investigated. Experiments on 44,487 Lending Club samples show that proper outlier detection can improve the effectiveness of the machine learning model, and the balanced sampling method only has a good effect on a few machine learning models, such as MLP.
Managing dataset shift by adversarial validation for credit scoring
Dec 19, 2021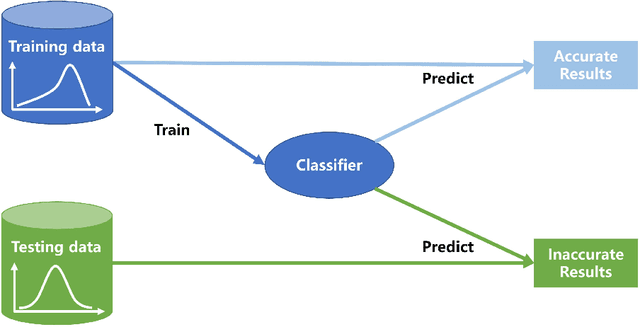
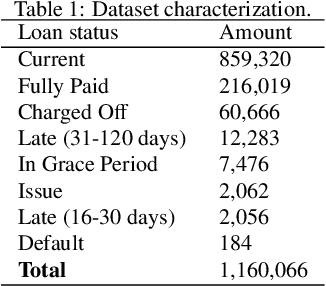
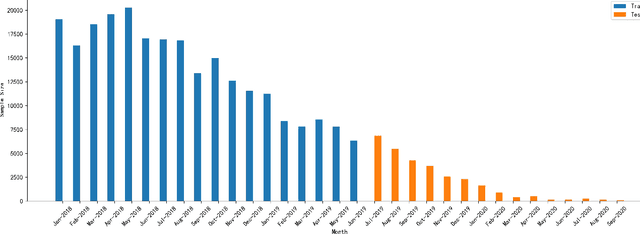

Dataset shift is common in credit scoring scenarios, and the inconsistency between the distribution of training data and the data that actually needs to be predicted is likely to cause poor model performance. However, most of the current studies do not take this into account, and they directly mix data from different time periods when training the models. This brings about two problems. Firstly, there is a risk of data leakage, i.e., using future data to predict the past. This can result in inflated results in offline validation, but unsatisfactory results in practical applications. Secondly, the macroeconomic environment and risk control strategies are likely to be different in different time periods, and the behavior patterns of borrowers may also change. The model trained with past data may not be applicable to the recent stage. Therefore, we propose a method based on adversarial validation to alleviate the dataset shift problem in credit scoring scenarios. In this method, partial training set samples with the closest distribution to the predicted data are selected for cross-validation by adversarial validation to ensure the generalization performance of the trained model on the predicted samples. In addition, through a simple splicing method, samples in the training data that are inconsistent with the test data distribution are also involved in the training process of cross-validation, which makes full use of all the data and further improves the model performance. To verify the effectiveness of the proposed method, comparative experiments with several other data split methods are conducted with the data provided by Lending Club. The experimental results demonstrate the importance of dataset shift in the field of credit scoring and the superiority of the proposed method.