 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManaging dataset shift by adversarial validation for credit scoring
Paper and Code
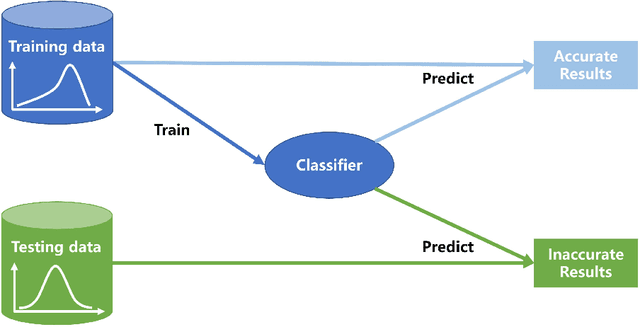
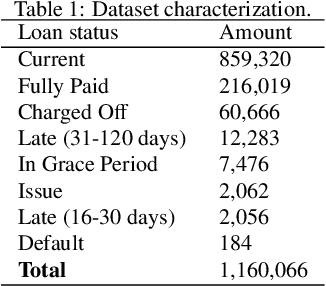
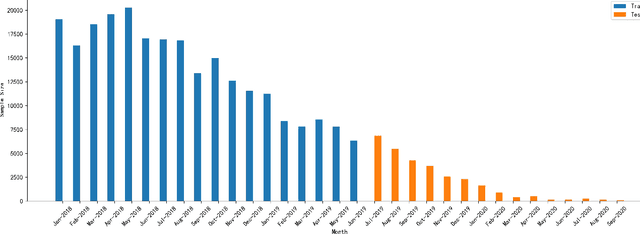

Dataset shift is common in credit scoring scenarios, and the inconsistency between the distribution of training data and the data that actually needs to be predicted is likely to cause poor model performance. However, most of the current studies do not take this into account, and they directly mix data from different time periods when training the models. This brings about two problems. Firstly, there is a risk of data leakage, i.e., using future data to predict the past. This can result in inflated results in offline validation, but unsatisfactory results in practical applications. Secondly, the macroeconomic environment and risk control strategies are likely to be different in different time periods, and the behavior patterns of borrowers may also change. The model trained with past data may not be applicable to the recent stage. Therefore, we propose a method based on adversarial validation to alleviate the dataset shift problem in credit scoring scenarios. In this method, partial training set samples with the closest distribution to the predicted data are selected for cross-validation by adversarial validation to ensure the generalization performance of the trained model on the predicted samples. In addition, through a simple splicing method, samples in the training data that are inconsistent with the test data distribution are also involved in the training process of cross-validation, which makes full use of all the data and further improves the model performance. To verify the effectiveness of the proposed method, comparative experiments with several other data split methods are conducted with the data provided by Lending Club. The experimental results demonstrate the importance of dataset shift in the field of credit scoring and the superiority of the proposed method.