 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Large-Scale Urban Parking Prediction: Graph Coarsening Based on Real-Time Parking Service Capability
Oct 05, 2024



With the sharp increase in the number of vehicles, the issue of parking difficulties has emerged as an urgent challenge that many cities need to address promptly. In the task of predicting large-scale urban parking data, existing research often lacks effective deep learning models and strategies. To tackle this challenge, this paper proposes an innovative framework for predicting large-scale urban parking graphs leveraging real-time service capabilities, aimed at improving the accuracy and efficiency of parking predictions. Specifically, we introduce a graph attention mechanism that assesses the real-time service capabilities of parking lots to construct a dynamic parking graph that accurately reflects real preferences in parking behavior. To effectively handle large-scale parking data, this study combines graph coarsening techniques with temporal convolutional autoencoders to achieve unified dimension reduction of the complex urban parking graph structure and features. Subsequently, we use a spatio-temporal graph convolutional model to make predictions based on the coarsened graph, and a pre-trained autoencoder-decoder module restores the predicted results to their original data dimensions, completing the task. Our methodology has been rigorously tested on a real dataset from parking lots in Shenzhen. The experimental results indicate that compared to traditional parking prediction models, our framework achieves improvements of 46.8\% and 30.5\% in accuracy and efficiency, respectively. Remarkably, with the expansion of the graph's scale, our framework's advantages become even more apparent, showcasing its substantial potential for solving complex urban parking dilemmas in practical scenarios.
Long-Tailed Out-of-Distribution Detection: Prioritizing Attention to Tail
Aug 13, 2024



Current out-of-distribution (OOD) detection methods typically assume balanced in-distribution (ID) data, while most real-world data follow a long-tailed distribution. Previous approaches to long-tailed OOD detection often involve balancing the ID data by reducing the semantics of head classes. However, this reduction can severely affect the classification accuracy of ID data. The main challenge of this task lies in the severe lack of features for tail classes, leading to confusion with OOD data. To tackle this issue, we introduce a novel Prioritizing Attention to Tail (PATT) method using augmentation instead of reduction. Our main intuition involves using a mixture of von Mises-Fisher (vMF) distributions to model the ID data and a temperature scaling module to boost the confidence of ID data. This enables us to generate infinite contrastive pairs, implicitly enhancing the semantics of ID classes while promoting differentiation between ID and OOD data. To further strengthen the detection of OOD data without compromising the classification performance of ID data, we propose feature calibration during the inference phase. By extracting an attention weight from the training set that prioritizes the tail classes and reduces the confidence in OOD data, we improve the OOD detection capability. Extensive experiments verified that our method outperforms the current state-of-the-art methods on various benchmarks.
A comparative study on machine learning models combining with outlier detection and balanced sampling methods for credit scoring
Dec 25, 2021



Peer-to-peer (P2P) lending platforms have grown rapidly over the past decade as the network infrastructure has improved and the demand for personal lending has grown. Such platforms allow users to create peer-to-peer lending relationships without the help of traditional financial institutions. Assessing the borrowers' credit is crucial to reduce the default rate and benign development of P2P platforms. Building a personal credit scoring machine learning model can effectively predict whether users will repay loans on the P2P platform. And the handling of data outliers and sample imbalance problems can affect the final effect of machine learning models. There have been some studies on balanced sampling methods, but the effect of outlier detection methods and their combination with balanced sampling methods on the effectiveness of machine learning models has not been fully studied. In this paper, the influence of using different outlier detection methods and balanced sampling methods on commonly used machine learning models is investigated. Experiments on 44,487 Lending Club samples show that proper outlier detection can improve the effectiveness of the machine learning model, and the balanced sampling method only has a good effect on a few machine learning models, such as MLP.
Managing dataset shift by adversarial validation for credit scoring
Dec 19, 2021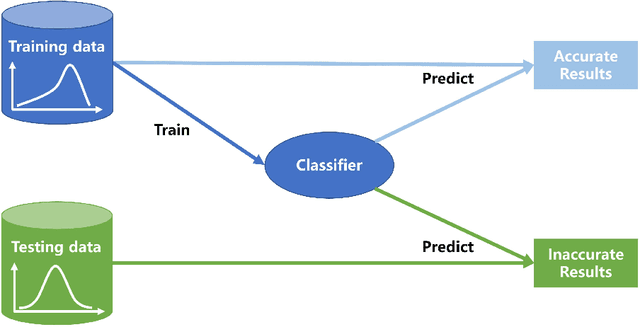
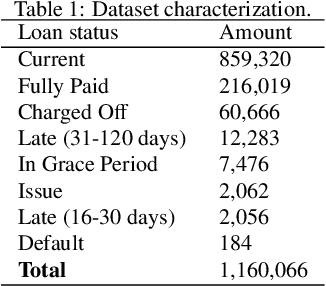
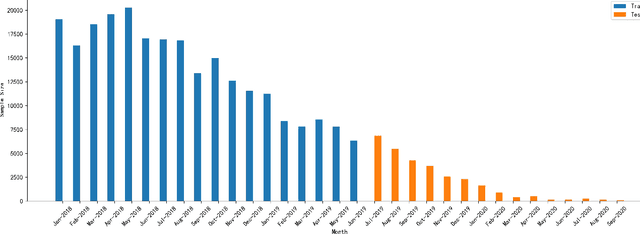

Dataset shift is common in credit scoring scenarios, and the inconsistency between the distribution of training data and the data that actually needs to be predicted is likely to cause poor model performance. However, most of the current studies do not take this into account, and they directly mix data from different time periods when training the models. This brings about two problems. Firstly, there is a risk of data leakage, i.e., using future data to predict the past. This can result in inflated results in offline validation, but unsatisfactory results in practical applications. Secondly, the macroeconomic environment and risk control strategies are likely to be different in different time periods, and the behavior patterns of borrowers may also change. The model trained with past data may not be applicable to the recent stage. Therefore, we propose a method based on adversarial validation to alleviate the dataset shift problem in credit scoring scenarios. In this method, partial training set samples with the closest distribution to the predicted data are selected for cross-validation by adversarial validation to ensure the generalization performance of the trained model on the predicted samples. In addition, through a simple splicing method, samples in the training data that are inconsistent with the test data distribution are also involved in the training process of cross-validation, which makes full use of all the data and further improves the model performance. To verify the effectiveness of the proposed method, comparative experiments with several other data split methods are conducted with the data provided by Lending Club. The experimental results demonstrate the importance of dataset shift in the field of credit scoring and the superiority of the proposed method.
A differential evolution-based optimization tool for interplanetary transfer trajectory design
Nov 17, 2020


The extremely sensitive and highly nonlinear search space of interplanetary transfer trajectory design bring about big challenges on global optimization. As a representative, the current known best solution of the global trajectory optimization problem (GTOP) designed by the European space agency (ESA) is very hard to be found. To deal with this difficulty, a powerful differential evolution-based optimization tool named COoperative Differential Evolution (CODE) is proposed in this paper. CODE employs a two-stage evolutionary process, which concentrates on learning global structure in the earlier process, and tends to self-adaptively learn the structures of different local spaces. Besides, considering the spatial distribution of global optimum on different problems and the gradient information on different variables, a multiple boundary check technique has been employed. Also, Covariance Matrix Adaptation Evolutionary Strategies (CMA-ES) is used as a local optimizer. The previous studies have shown that a specific swarm intelligent optimization algorithm usually can solve only one or two GTOP problems. However, the experimental test results show that CODE can find the current known best solutions of Cassini1 and Sagas directly, and the cooperation with CMA-ES can solve Cassini2, GTOC1, Messenger (reduced) and Rosetta. For the most complicated Messenger (full) problem, even though CODE cannot find the current known best solution, the found best solution with objective function equaling to 3.38 km/s is still a level that other swarm intelligent algorithms cannot easily reach.