 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to beat a Bayesian adversary
Jul 11, 2024



Deep neural networks and other modern machine learning models are often susceptible to adversarial attacks. Indeed, an adversary may often be able to change a model's prediction through a small, directed perturbation of the model's input - an issue in safety-critical applications. Adversarially robust machine learning is usually based on a minmax optimisation problem that minimises the machine learning loss under maximisation-based adversarial attacks. In this work, we study adversaries that determine their attack using a Bayesian statistical approach rather than maximisation. The resulting Bayesian adversarial robustness problem is a relaxation of the usual minmax problem. To solve this problem, we propose Abram - a continuous-time particle system that shall approximate the gradient flow corresponding to the underlying learning problem. We show that Abram approximates a McKean-Vlasov process and justify the use of Abram by giving assumptions under which the McKean-Vlasov process finds the minimiser of the Bayesian adversarial robustness problem. We discuss two ways to discretise Abram and show its suitability in benchmark adversarial deep learning experiments.
DSGD-CECA: Decentralized SGD with Communication-Optimal Exact Consensus Algorithm
Jun 01, 2023



Decentralized Stochastic Gradient Descent (SGD) is an emerging neural network training approach that enables multiple agents to train a model collaboratively and simultaneously. Rather than using a central parameter server to collect gradients from all the agents, each agent keeps a copy of the model parameters and communicates with a small number of other agents to exchange model updates. Their communication, governed by the communication topology and gossip weight matrices, facilitates the exchange of model updates. The state-of-the-art approach uses the dynamic one-peer exponential-2 topology, achieving faster training times and improved scalability than the ring, grid, torus, and hypercube topologies. However, this approach requires a power-of-2 number of agents, which is impractical at scale. In this paper, we remove this restriction and propose \underline{D}ecentralized \underline{SGD} with \underline{C}ommunication-optimal \underline{E}xact \underline{C}onsensus \underline{A}lgorithm (DSGD-CECA), which works for any number of agents while still achieving state-of-the-art properties. In particular, DSGD-CECA incurs a unit per-iteration communication overhead and an $\tilde{O}(n^3)$ transient iteration complexity. Our proof is based on newly discovered properties of gossip weight matrices and a novel approach to combine them with DSGD's convergence analysis. Numerical experiments show the efficiency of DSGD-CECA.
Subsampling Error in Stochastic Gradient Langevin Diffusions
May 23, 2023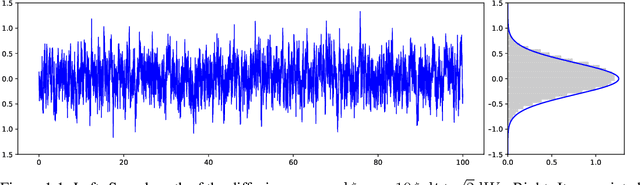
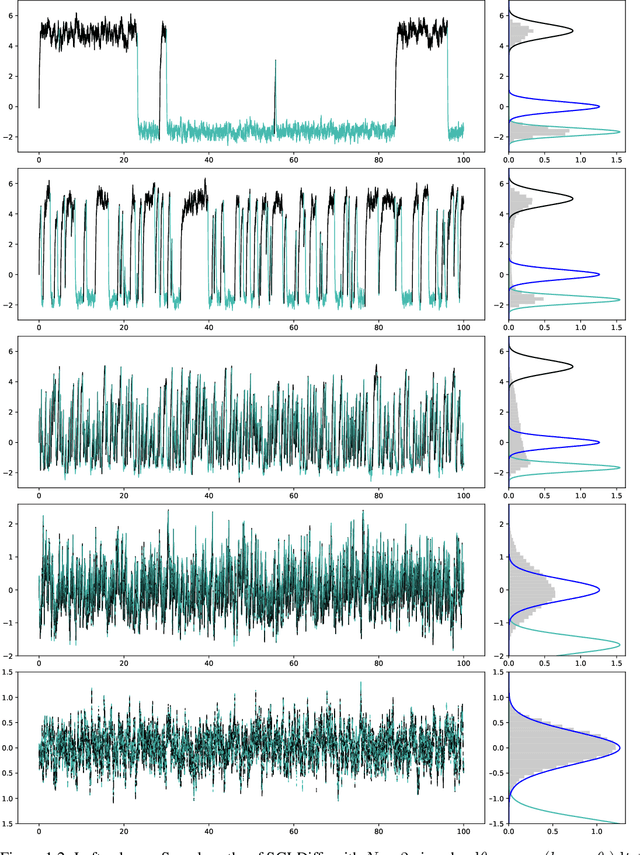
The Stochastic Gradient Langevin Dynamics (SGLD) are popularly used to approximate Bayesian posterior distributions in statistical learning procedures with large-scale data. As opposed to many usual Markov chain Monte Carlo (MCMC) algorithms, SGLD is not stationary with respect to the posterior distribution; two sources of error appear: The first error is introduced by an Euler--Maruyama discretisation of a Langevin diffusion process, the second error comes from the data subsampling that enables its use in large-scale data settings. In this work, we consider an idealised version of SGLD to analyse the method's pure subsampling error that we then see as a best-case error for diffusion-based subsampling MCMC methods. Indeed, we introduce and study the Stochastic Gradient Langevin Diffusion (SGLDiff), a continuous-time Markov process that follows the Langevin diffusion corresponding to a data subset and switches this data subset after exponential waiting times. There, we show that the Wasserstein distance between the posterior and the limiting distribution of SGLDiff is bounded above by a fractional power of the mean waiting time. Importantly, this fractional power does not depend on the dimension of the state space. We bring our results into context with other analyses of SGLD.
AdaNPC: Exploring Non-Parametric Classifier for Test-Time Adaptation
Apr 25, 2023



Many recent machine learning tasks focus to develop models that can generalize to unseen distributions. Domain generalization (DG) has become one of the key topics in various fields. Several literatures show that DG can be arbitrarily hard without exploiting target domain information. To address this issue, test-time adaptive (TTA) methods are proposed. Existing TTA methods require offline target data or extra sophisticated optimization procedures during the inference stage. In this work, we adopt Non-Parametric Classifier to perform the test-time Adaptation (AdaNPC). In particular, we construct a memory that contains the feature and label pairs from training domains. During inference, given a test instance, AdaNPC first recalls K closed samples from the memory to vote for the prediction, and then the test feature and predicted label are added to the memory. In this way, the sample distribution in the memory can be gradually changed from the training distribution towards the test distribution with very little extra computation cost. We theoretically justify the rationality behind the proposed method. Besides, we test our model on extensive numerical experiments. AdaNPC significantly outperforms competitive baselines on various DG benchmarks. In particular, when the adaptation target is a series of domains, the adaptation accuracy of AdaNPC is 50% higher than advanced TTA methods. The code is available at https://github.com/yfzhang114/AdaNPC.
* 30 pages, 12 figures
Communication-Efficient Topologies for Decentralized Learning with $O(1)$ Consensus Rate
Oct 14, 2022
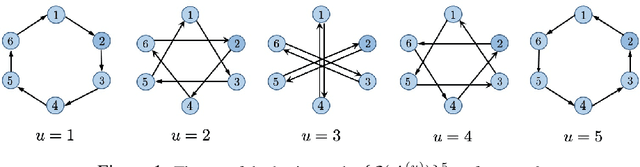
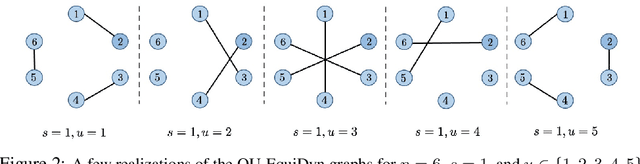

Decentralized optimization is an emerging paradigm in distributed learning in which agents achieve network-wide solutions by peer-to-peer communication without the central server. Since communication tends to be slower than computation, when each agent communicates with only a few neighboring agents per iteration, they can complete iterations faster than with more agents or a central server. However, the total number of iterations to reach a network-wide solution is affected by the speed at which the agents' information is ``mixed'' by communication. We found that popular communication topologies either have large maximum degrees (such as stars and complete graphs) or are ineffective at mixing information (such as rings and grids). To address this problem, we propose a new family of topologies, EquiTopo, which has an (almost) constant degree and a network-size-independent consensus rate that is used to measure the mixing efficiency. In the proposed family, EquiStatic has a degree of $\Theta(\ln(n))$, where $n$ is the network size, and a series of time-dependent one-peer topologies, EquiDyn, has a constant degree of 1. We generate EquiDyn through a certain random sampling procedure. Both of them achieve an $n$-independent consensus rate. We apply them to decentralized SGD and decentralized gradient tracking and obtain faster communication and better convergence, theoretically and empirically. Our code is implemented through BlueFog and available at \url{https://github.com/kexinjinnn/EquiTopo}
Losing momentum in continuous-time stochastic optimisation
Sep 08, 2022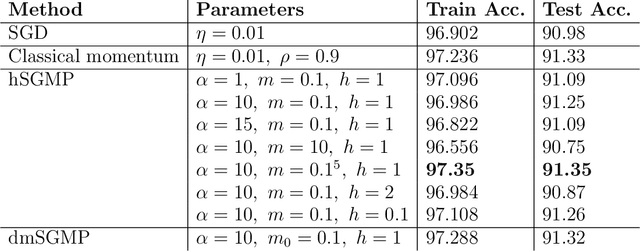
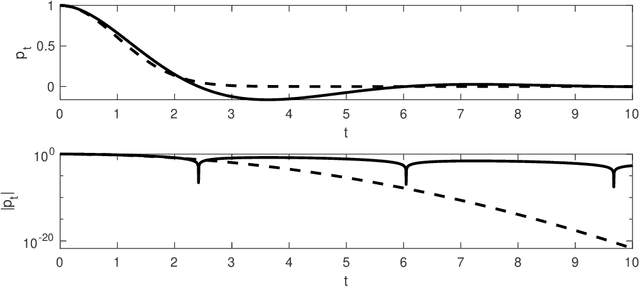
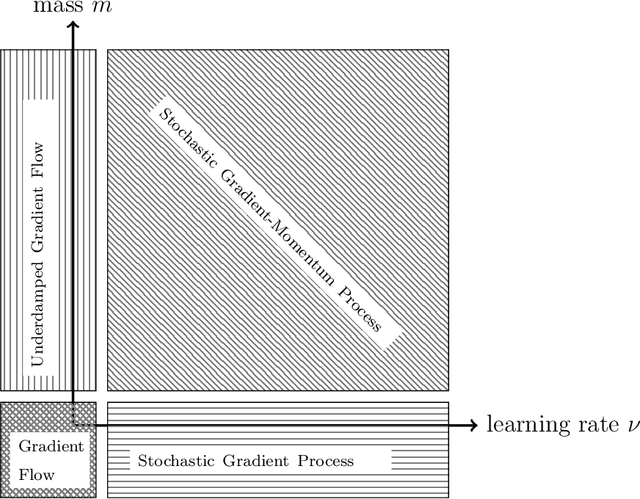
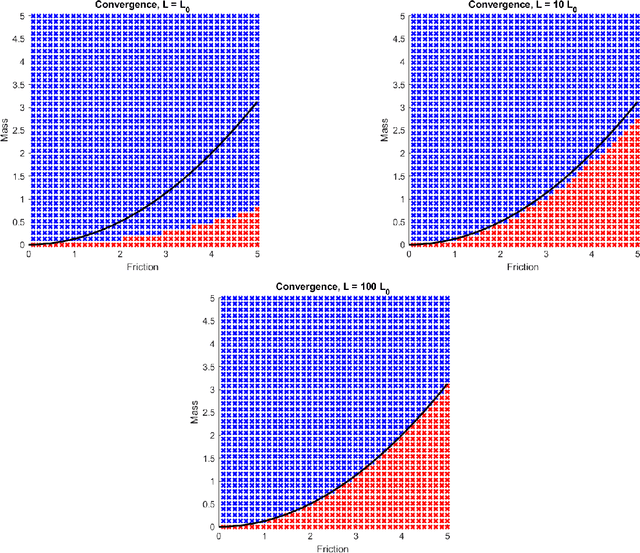
The training of deep neural networks and other modern machine learning models usually consists in solving non-convex optimisation problems that are high-dimensional and subject to large-scale data. Here, momentum-based stochastic optimisation algorithms have become especially popular in recent years. The stochasticity arises from data subsampling which reduces computational cost. Moreover, both, momentum and stochasticity are supposed to help the algorithm to overcome local minimisers and, hopefully, converge globally. Theoretically, this combination of stochasticity and momentum is badly understood. In this work, we propose and analyse a continuous-time model for stochastic gradient descent with momentum. This model is a piecewise-deterministic Markov process that represents the particle movement by an underdamped dynamical system and the data subsampling through a stochastic switching of the dynamical system. In our analysis, we investigate longtime limits, the subsampling-to-no-subsampling limit, and the momentum-to-no-momentum limit. We are particularly interested in the case of reducing the momentum over time: intuitively, the momentum helps to overcome local minimisers in the initial phase of the algorithm, but prohibits fast convergence to a global minimiser later. Under convexity assumptions, we show convergence of our dynamical system to the global minimiser when reducing momentum over time and let the subsampling rate go to infinity. We then propose a stable, symplectic discretisation scheme to construct an algorithm from our continuous-time dynamical system. In numerical experiments, we study our discretisation scheme in convex and non-convex test problems. Additionally, we train a convolutional neural network to solve the CIFAR-10 image classification problem. Here, our algorithm reaches competitive results compared to stochastic gradient descent with momentum.
A Continuous-time Stochastic Gradient Descent Method for Continuous Data
Dec 07, 2021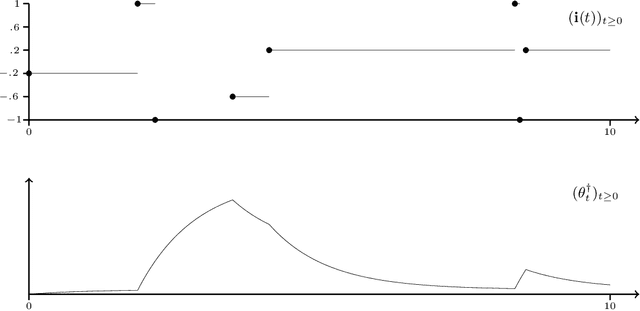
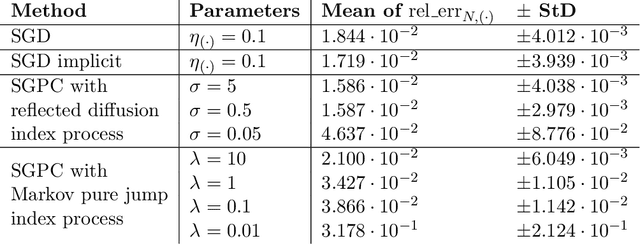
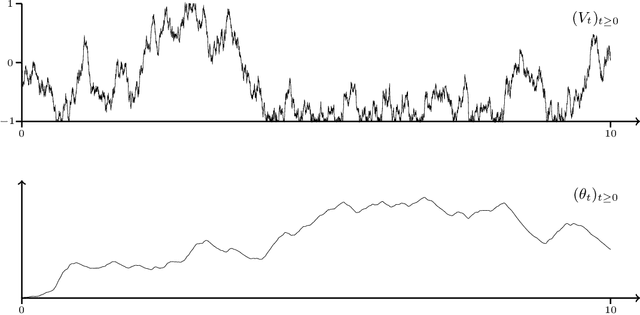
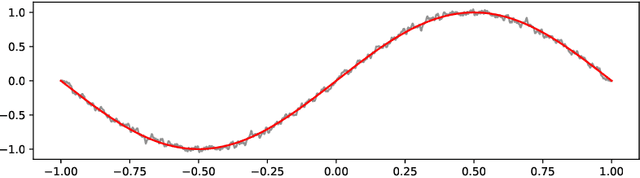
Optimization problems with continuous data appear in, e.g., robust machine learning, functional data analysis, and variational inference. Here, the target function is given as an integral over a family of (continuously) indexed target functions - integrated with respect to a probability measure. Such problems can often be solved by stochastic optimization methods: performing optimization steps with respect to the indexed target function with randomly switched indices. In this work, we study a continuous-time variant of the stochastic gradient descent algorithm for optimization problems with continuous data. This so-called stochastic gradient process consists in a gradient flow minimizing an indexed target function that is coupled with a continuous-time index process determining the index. Index processes are, e.g., reflected diffusions, pure jump processes, or other L\'evy processes on compact spaces. Thus, we study multiple sampling patterns for the continuous data space and allow for data simulated or streamed at runtime of the algorithm. We analyze the approximation properties of the stochastic gradient process and study its longtime behavior and ergodicity under constant and decreasing learning rates. We end with illustrating the applicability of the stochastic gradient process in a polynomial regression problem with noisy functional data, as well as in a physics-informed neural network.