 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Attention with Lookahead Keys
Sep 09, 2025In standard causal attention, each token's query, key, and value (QKV) are static and encode only preceding context. We introduce CAuSal aTtention with Lookahead kEys (CASTLE), an attention mechanism that continually updates each token's keys as the context unfolds. We term these updated keys lookahead keys because they belong to earlier positions yet integrate information from tokens that appear later relative to those positions, while strictly preserving the autoregressive property. Although the mechanism appears sequential, we derive a mathematical equivalence that avoids explicitly materializing lookahead keys at each position and enables efficient parallel training. On language modeling benchmarks, CASTLE consistently outperforms standard causal attention across model scales, reducing validation perplexity and improving performance on a range of downstream tasks.
Can We Find Nash Equilibria at a Linear Rate in Markov Games?
Mar 03, 2023We study decentralized learning in two-player zero-sum discounted Markov games where the goal is to design a policy optimization algorithm for either agent satisfying two properties. First, the player does not need to know the policy of the opponent to update its policy. Second, when both players adopt the algorithm, their joint policy converges to a Nash equilibrium of the game. To this end, we construct a meta algorithm, dubbed as $\texttt{Homotopy-PO}$, which provably finds a Nash equilibrium at a global linear rate. In particular, $\texttt{Homotopy-PO}$ interweaves two base algorithms $\texttt{Local-Fast}$ and $\texttt{Global-Slow}$ via homotopy continuation. $\texttt{Local-Fast}$ is an algorithm that enjoys local linear convergence while $\texttt{Global-Slow}$ is an algorithm that converges globally but at a slower sublinear rate. By switching between these two base algorithms, $\texttt{Global-Slow}$ essentially serves as a ``guide'' which identifies a benign neighborhood where $\texttt{Local-Fast}$ enjoys fast convergence. However, since the exact size of such a neighborhood is unknown, we apply a doubling trick to switch between these two base algorithms. The switching scheme is delicately designed so that the aggregated performance of the algorithm is driven by $\texttt{Local-Fast}$. Furthermore, we prove that $\texttt{Local-Fast}$ and $\texttt{Global-Slow}$ can both be instantiated by variants of optimistic gradient descent/ascent (OGDA) method, which is of independent interest.
Communication-Efficient Topologies for Decentralized Learning with $O(1)$ Consensus Rate
Oct 14, 2022
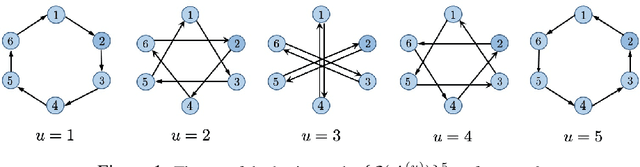
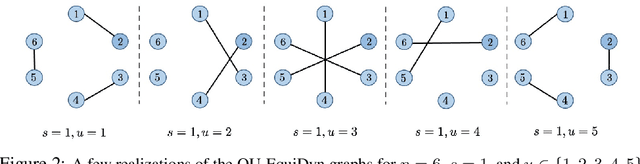

Decentralized optimization is an emerging paradigm in distributed learning in which agents achieve network-wide solutions by peer-to-peer communication without the central server. Since communication tends to be slower than computation, when each agent communicates with only a few neighboring agents per iteration, they can complete iterations faster than with more agents or a central server. However, the total number of iterations to reach a network-wide solution is affected by the speed at which the agents' information is ``mixed'' by communication. We found that popular communication topologies either have large maximum degrees (such as stars and complete graphs) or are ineffective at mixing information (such as rings and grids). To address this problem, we propose a new family of topologies, EquiTopo, which has an (almost) constant degree and a network-size-independent consensus rate that is used to measure the mixing efficiency. In the proposed family, EquiStatic has a degree of $\Theta(\ln(n))$, where $n$ is the network size, and a series of time-dependent one-peer topologies, EquiDyn, has a constant degree of 1. We generate EquiDyn through a certain random sampling procedure. Both of them achieve an $n$-independent consensus rate. We apply them to decentralized SGD and decentralized gradient tracking and obtain faster communication and better convergence, theoretically and empirically. Our code is implemented through BlueFog and available at \url{https://github.com/kexinjinnn/EquiTopo}
Provably Accelerated Decentralized Gradient Method Over Unbalanced Directed Graphs
Jul 26, 2021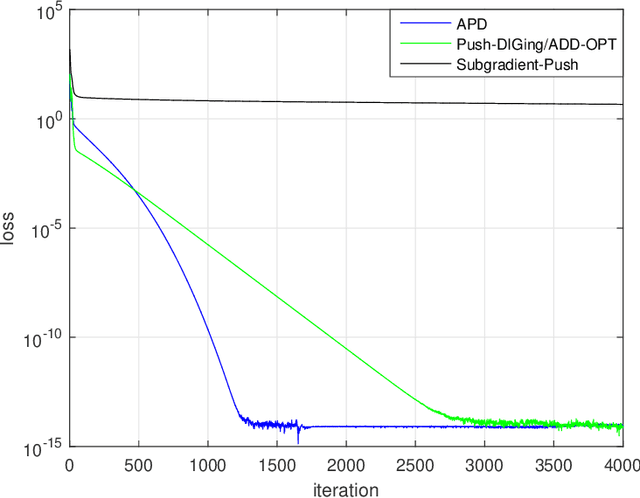
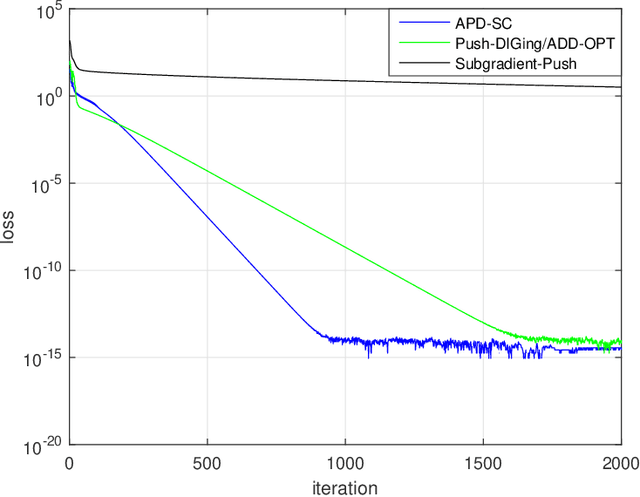
In this work, we consider the decentralized optimization problem in which a network of $n$ agents, each possessing a smooth and convex objective function, wish to collaboratively minimize the average of all the objective functions through peer-to-peer communication in a directed graph. To solve the problem, we propose two accelerated Push-DIGing methods termed APD and APD-SC for minimizing non-strongly convex objective functions and strongly convex ones, respectively. We show that APD and APD-SC respectively converge at the rates $O\left(\frac{1}{k^2}\right)$ and $O\left(\left(1 - C\sqrt{\frac{\mu}{L}}\right)^k\right)$ up to constant factors depending only on the mixing matrix. To the best of our knowledge, APD and APD-SC are the first decentralized methods to achieve provable acceleration over unbalanced directed graphs. Numerical experiments demonstrate the effectiveness of both methods.
Compressed Gradient Tracking for Decentralized Optimization Over General Directed Networks
Jun 14, 2021


In this paper, we propose two communication-efficient algorithms for decentralized optimization over a multi-agent network with general directed network topology. In the first part, we consider a novel communication-efficient gradient tracking based method, termed Compressed Push-Pull (CPP), which combines the Push-Pull method with communication compression. We show that CPP is applicable to a general class of unbiased compression operators and achieves linear convergence for strongly convex and smooth objective functions. In the second part, we propose a broadcast-like version of CPP (B-CPP), which also achieves linear convergence rate under the same conditions for the objective functions. B-CPP can be applied in an asynchronous broadcast setting and further reduce communication costs compared to CPP. Numerical experiments complement the theoretical analysis and confirm the effectiveness of the proposed methods.