 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Modeling in Protein Design: Neural Representations, Conditional Generation, and Evaluation Standards
Mar 27, 2026Generative modeling has become a central paradigm in protein research, extending machine learning beyond structure prediction toward sequence design, backbone generation, inverse folding, and biomolecular interaction modeling. However, the literature remains fragmented across representations, model classes, and task formulations, making it difficult to compare methods or identify appropriate evaluation standards. This survey provides a systematic synthesis of generative AI in protein research, organized around (i) foundational representations spanning sequence, geometric, and multimodal encodings; (ii) generative architectures including $\mathrm{SE}(3)$-equivariant diffusion, flow matching, and hybrid predictor-generator systems; and (iii) task settings from structure prediction and de novo design to protein-ligand and protein-protein interactions. Beyond cataloging methods, we compare assumptions, conditioning mechanisms, and controllability, and we synthesize evaluation best practices that emphasize leakage-aware splits, physical validity checks, and function-oriented benchmarks. We conclude with critical open challenges: modeling conformational dynamics and intrinsically disordered regions, scaling to large assemblies while maintaining efficiency, and developing robust safety frameworks for dual-use biosecurity risks. By unifying architectural advances with practical evaluation standards and responsible development considerations, this survey aims to accelerate the transition from predictive modeling to reliable, function-driven protein engineering.
ETimeline: An Extensive Timeline Generation Dataset based on Large Language Model
Feb 11, 2025
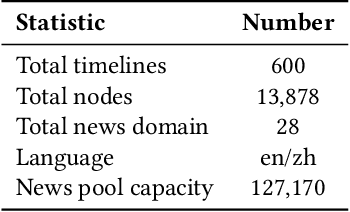
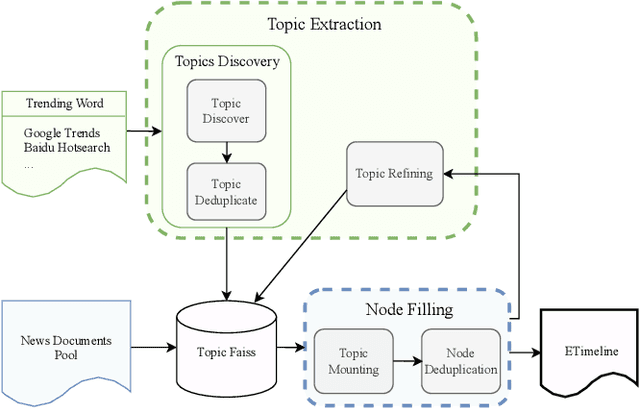

Timeline generation is of great significance for a comprehensive understanding of the development of events over time. Its goal is to organize news chronologically, which helps to identify patterns and trends that may be obscured when viewing news in isolation, making it easier to track the development of stories and understand the interrelationships between key events. Timelines are now common in various commercial products, but academic research in this area is notably scarce. Additionally, the current datasets are in need of refinement for enhanced utility and expanded coverage. In this paper, we propose ETimeline, which encompasses over $13,000$ news articles, spanning $600$ bilingual timelines across $28$ news domains. Specifically, we gather a candidate pool of more than $120,000$ news articles and employ the large language model (LLM) Pipeline to improve performance, ultimately yielding the ETimeline. The data analysis underscores the appeal of ETimeline. Additionally, we also provide the news pool data for further research and analysis. This work contributes to the advancement of timeline generation research and supports a wide range of tasks, including topic generation and event relationships. We believe that this dataset will serve as a catalyst for innovative research and bridge the gap between academia and industry in understanding the practical application of technology services. The dataset is available at https://zenodo.org/records/11392212
DeRisk: An Effective Deep Learning Framework for Credit Risk Prediction over Real-World Financial Data
Aug 07, 2023


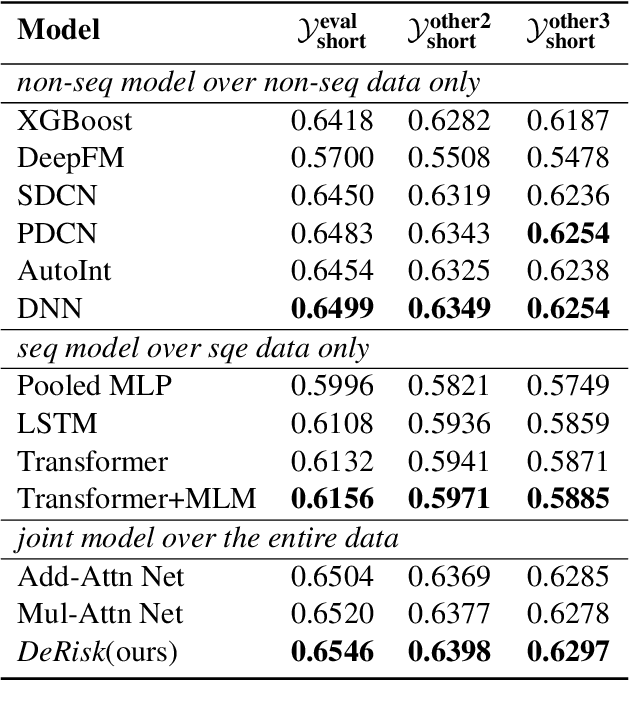
Despite the tremendous advances achieved over the past years by deep learning techniques, the latest risk prediction models for industrial applications still rely on highly handtuned stage-wised statistical learning tools, such as gradient boosting and random forest methods. Different from images or languages, real-world financial data are high-dimensional, sparse, noisy and extremely imbalanced, which makes deep neural network models particularly challenging to train and fragile in practice. In this work, we propose DeRisk, an effective deep learning risk prediction framework for credit risk prediction on real-world financial data. DeRisk is the first deep risk prediction model that outperforms statistical learning approaches deployed in our company's production system. We also perform extensive ablation studies on our method to present the most critical factors for the empirical success of DeRisk.
PSP: Pre-trained Soft Prompts for Few-Shot Abstractive Summarization
Apr 09, 2022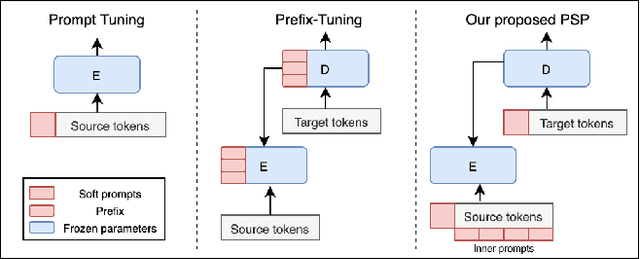
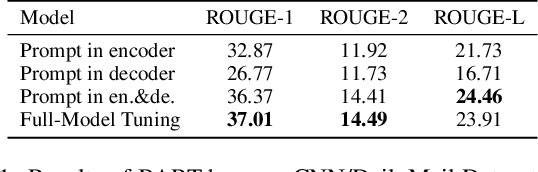
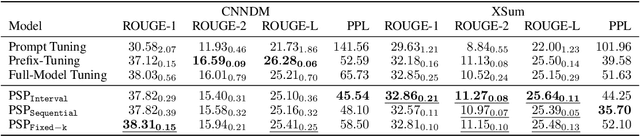
Few-shot abstractive summarization has become a challenging task in natural language generation. To support it, we designed a novel soft prompts architecture coupled with a prompt pre-training plus fine-tuning paradigm that is effective and tunes only extremely light parameters. The soft prompts include continuous input embeddings across an encoder and a decoder to fit the structure of the generation models. Importantly, a novel inner-prompt placed in the text is introduced to capture document-level information. The aim is to devote attention to understanding the document that better prompts the model to generate document-related content. The first step in the summarization procedure is to conduct prompt pre-training with self-supervised pseudo-data. This teaches the model basic summarizing capabilities. The model is then fine-tuned with few-shot examples. Experimental results on the CNN/DailyMail and XSum datasets show that our method, with only 0.1% of the parameters, outperforms full-model tuning where all model parameters are tuned. It also surpasses Prompt Tuning by a large margin and delivers competitive results against Prefix-Tuning with 3% of the parameters.
Efficient Pipelines for Vision-Based Context Sensing
Nov 01, 2020

Context awareness is an essential part of mobile and ubiquitous computing. Its goal is to unveil situational information about mobile users like locations and activities. The sensed context can enable many services like navigation, AR, and smarting shopping. Such context can be sensed in different ways including visual sensors. There is an emergence of vision sources deployed worldwide. The cameras could be installed on roadside, in-house, and on mobile platforms. This trend provides huge amount of vision data that could be used for context sensing. However, the vision data collection and analytics are still highly manual today. It is hard to deploy cameras at large scale for data collection. Organizing and labeling context from the data are also labor intensive. In recent years, advanced vision algorithms and deep neural networks are used to help analyze vision data. But this approach is limited by data quality, labeling effort, and dependency on hardware resources. In summary, there are three major challenges for today's vision-based context sensing systems: data collection and labeling at large scale, process large data volumes efficiently with limited hardware resources, and extract accurate context out of vision data. The thesis explores the design space that consists of three dimensions: sensing task, sensor types, and task locations. Our prior work explores several points in this design space. We make contributions by (1) developing efficient and scalable solutions for different points in the design space of vision-based sensing tasks; (2) achieving state-of-the-art accuracy in those applications; (3) and developing guidelines for designing such sensing systems.
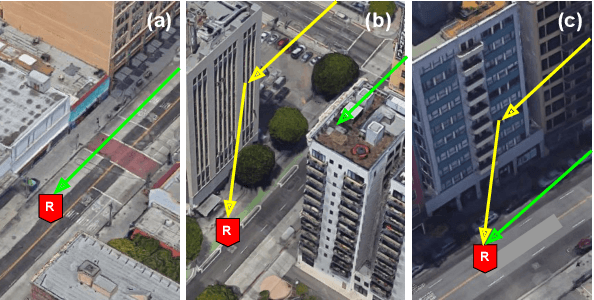
On Localizing a Camera from a Single Image
Mar 24, 2020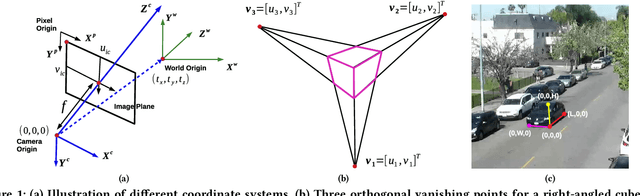



Public cameras often have limited metadata describing their attributes. A key missing attribute is the precise location of the camera, using which it is possible to precisely pinpoint the location of events seen in the camera. In this paper, we explore the following question: under what conditions is it possible to estimate the location of a camera from a single image taken by the camera? We show that, using a judicious combination of projective geometry, neural networks, and crowd-sourced annotations from human workers, it is possible to position 95% of the images in our test data set to within 12 m. This performance is two orders of magnitude better than PoseNet, a state-of-the-art neural network that, when trained on a large corpus of images in an area, can estimate the pose of a single image. Finally, we show that the camera's inferred position and intrinsic parameters can help design a number of virtual sensors, all of which are reasonably accurate.
Grab: Fast and Accurate Sensor Processing for Cashier-Free Shopping
Jan 04, 2020
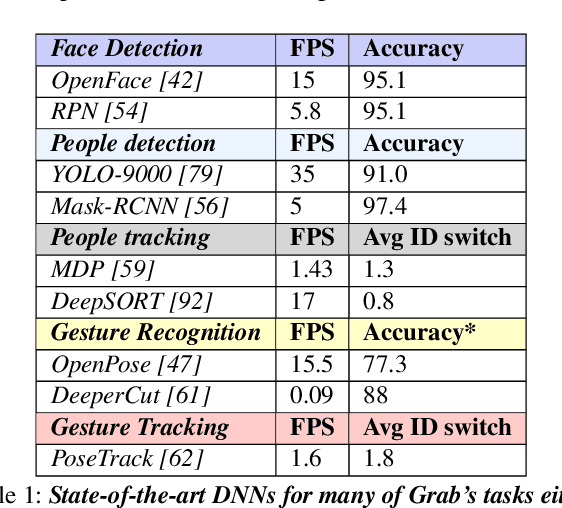
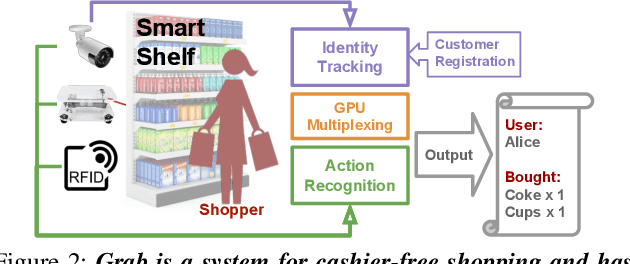
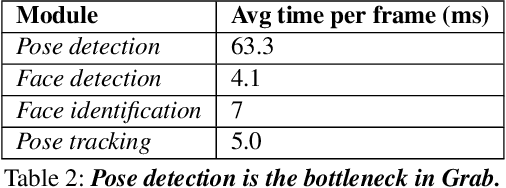
Cashier-free shopping systems like Amazon Go improve shopping experience, but can require significant store redesign. In this paper, we propose Grab, a practical system that leverages existing infrastructure and devices to enable cashier-free shopping. Grab needs to accurately identify and track customers, and associate each shopper with items he or she retrieves from shelves. To do this, it uses a keypoint-based pose tracker as a building block for identification and tracking, develops robust feature-based face trackers, and algorithms for associating and tracking arm movements. It also uses a probabilistic framework to fuse readings from camera, weight and RFID sensors in order to accurately assess which shopper picks up which item. In experiments from a pilot deployment in a retail store, Grab can achieve over 90% precision and recall even when 40% of shopping actions are designed to confuse the system. Moreover, Grab has optimizations that help reduce investment in computing infrastructure four-fold.