 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSP: Pre-trained Soft Prompts for Few-Shot Abstractive Summarization
Paper and Code
Apr 09, 2022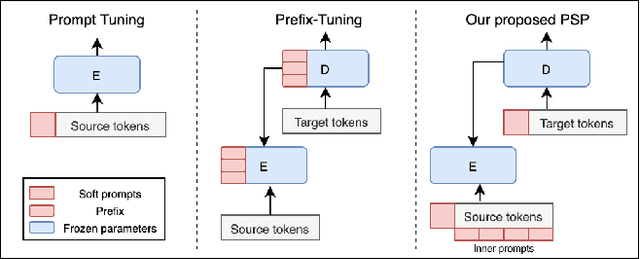
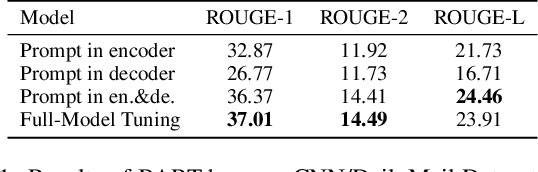
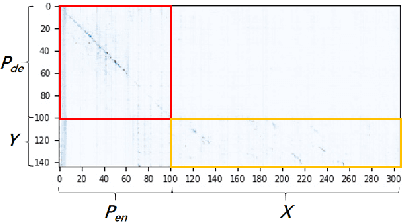
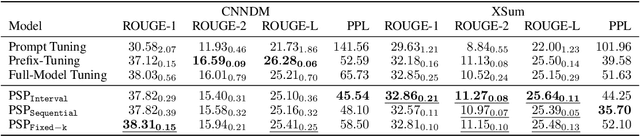
Few-shot abstractive summarization has become a challenging task in natural language generation. To support it, we designed a novel soft prompts architecture coupled with a prompt pre-training plus fine-tuning paradigm that is effective and tunes only extremely light parameters. The soft prompts include continuous input embeddings across an encoder and a decoder to fit the structure of the generation models. Importantly, a novel inner-prompt placed in the text is introduced to capture document-level information. The aim is to devote attention to understanding the document that better prompts the model to generate document-related content. The first step in the summarization procedure is to conduct prompt pre-training with self-supervised pseudo-data. This teaches the model basic summarizing capabilities. The model is then fine-tuned with few-shot examples. Experimental results on the CNN/DailyMail and XSum datasets show that our method, with only 0.1% of the parameters, outperforms full-model tuning where all model parameters are tuned. It also surpasses Prompt Tuning by a large margin and delivers competitive results against Prefix-Tuning with 3% of the parameters.