 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-NFS: Bandwidth-adaptive Streaming of Dynamic Gaussian Splats and Point Clouds
Jun 04, 2026Dynamic 3D Gaussian Splatting (3DGS) holds great promise as a 3D video streaming technology since it can represent complex 3D scenes with high fidelity. In this approach, every frame in a 3D video represents the environment as a collection of Gaussians with position and other attributes such as scale, rotation, opacity, and color. Frames capture fine details, permit views from any arbitrary perspective, but are an order of magnitude, or more, larger than 2D video frames. A line of recent work has explored how to compress dynamic 3DGS frames, but these approaches are often slow, in part because their compression techniques are not amenable to efficient acceleration. GS-NFS accelerates dynamic 3DGS compression and decompression on a GPU, to the point where it can encode and decode at full frame rate. It achieves this by developing novel GPU-based parallelizations of existing algorithms for encoding both positions and attributes of Gaussians. As a result, it is 1-2 orders of magnitude faster than the state-of-the-art in encoding and decoding a frame, while offering competitive compression performance and rendering quality.
iDriving: Toward Safe and Efficient Infrastructure-directed Autonomous Driving
Jul 18, 2022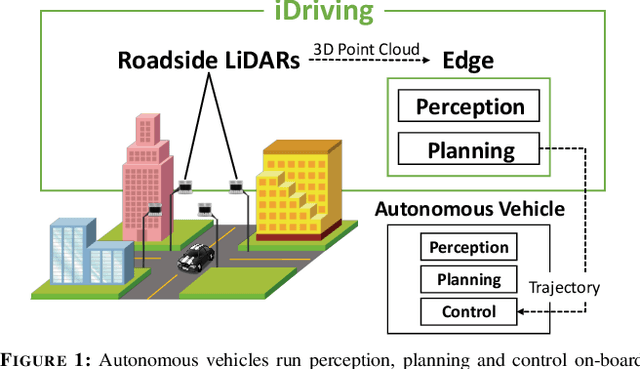
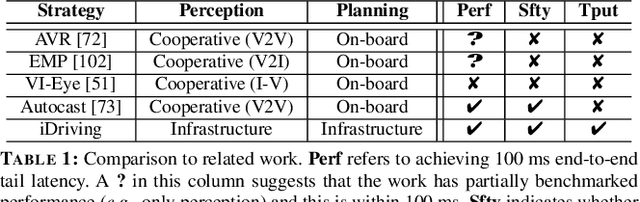
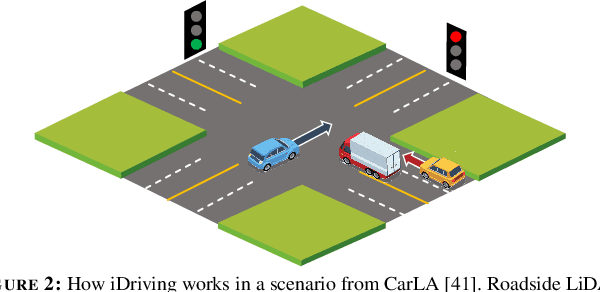
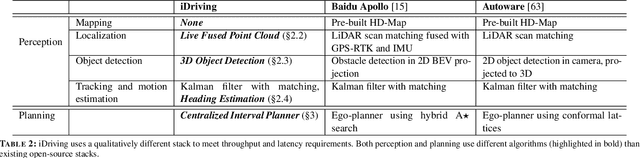
Autonomous driving will become pervasive in the coming decades. iDriving improves the safety of autonomous driving at intersections and increases efficiency by improving traffic throughput at intersections. In iDriving, roadside infrastructure remotely drives an autonomous vehicle at an intersection by offloading perception and planning from the vehicle to roadside infrastructure. To achieve this, iDriving must be able to process voluminous sensor data at full frame rate with a tail latency of less than 100 ms, without sacrificing accuracy. We describe algorithms and optimizations that enable it to achieve this goal using an accurate and lightweight perception component that reasons on composite views derived from overlapping sensors, and a planner that jointly plans trajectories for multiple vehicles. In our evaluations, iDriving always ensures safe passage of vehicles, while autonomous driving can only do so 27% of the time. iDriving also results in 5x lower wait times than other approaches because it enables traffic-light free intersections.
ARES: Accurate, Autonomous, Near Real-time 3D Reconstruction using Drones
Apr 20, 2021
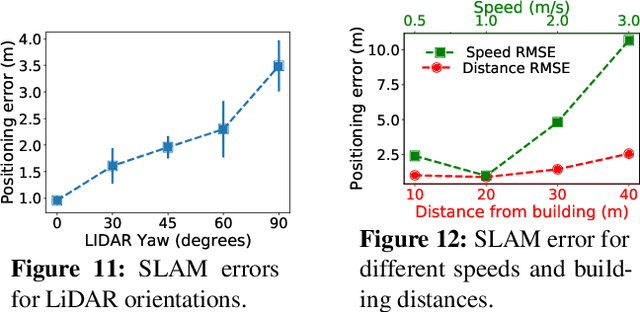
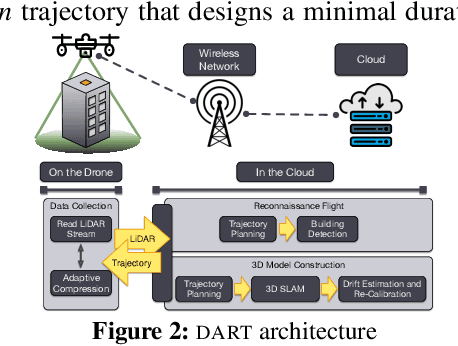
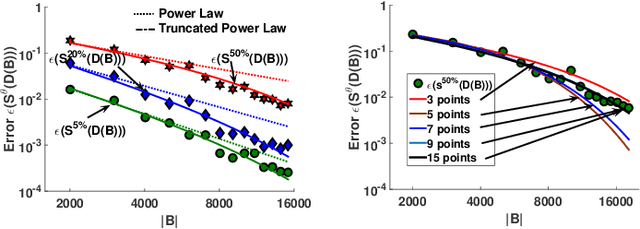
Drones will revolutionize 3D modeling. A 3D model represents an accurate reconstruction of an object or structure. This paper explores the design and implementation of ARES, which provides near real-time, accurate reconstruction of 3D models using a drone-mounted LiDAR; such a capability can be useful to document construction or check aircraft integrity between flights. Accurate reconstruction requires high drone positioning accuracy, and, because GPS can be in accurate, ARES uses SLAM. However, in doing so it must deal with several competing constraints: drone battery and compute resources, SLAM error accumulation, and LiDAR resolution. ARES uses careful trajectory design to find a sweet spot in this constraint space, a fast reconnaissance flight to narrow the search area for structures, and offloads expensive computations to the cloud by streaming compressed LiDAR data over LTE. ARES reconstructs large structures to within 10s of cms and incurs less than 100 ms compute latency.
Minimum Cost Active Labeling
Jun 24, 2020
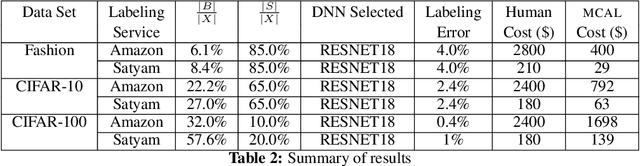
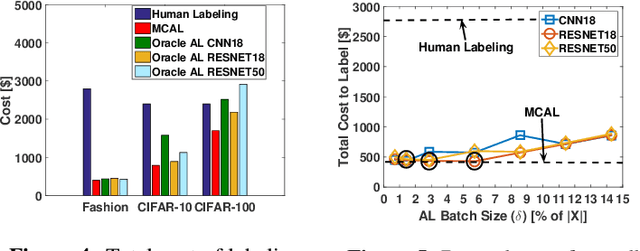
Labeling a data set completely is important for groundtruth generation. In this paper, we consider the problem of minimum-cost labeling: classifying all images in a large data set with a target accuracy bound at minimum dollar cost. Human labeling can be prohibitive, so we train a classifier to accurately label part of the data set. However, training the classifier can be expensive too, particularly with active learning. Our min-cost labeling uses a variant of active learning to learn a model to predict the optimal training set size for the classifier that minimizes overall cost, then uses active learning to train the classifier to maximize the number of samples the classifier can correctly label. We validate our approach on well-known public data sets such as Fashion, CIFAR-10, and CIFAR-100. In some cases, our approach has 6X lower overall cost relative to human labeling, and is always cheaper than the cheapest active learning strategy.
On Localizing a Camera from a Single Image
Mar 24, 2020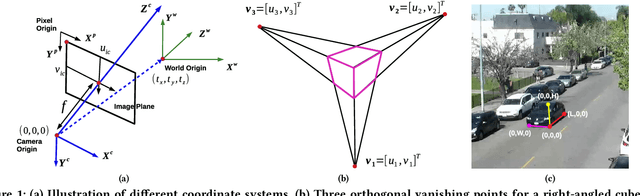



Public cameras often have limited metadata describing their attributes. A key missing attribute is the precise location of the camera, using which it is possible to precisely pinpoint the location of events seen in the camera. In this paper, we explore the following question: under what conditions is it possible to estimate the location of a camera from a single image taken by the camera? We show that, using a judicious combination of projective geometry, neural networks, and crowd-sourced annotations from human workers, it is possible to position 95% of the images in our test data set to within 12 m. This performance is two orders of magnitude better than PoseNet, a state-of-the-art neural network that, when trained on a large corpus of images in an area, can estimate the pose of a single image. Finally, we show that the camera's inferred position and intrinsic parameters can help design a number of virtual sensors, all of which are reasonably accurate.
Grab: Fast and Accurate Sensor Processing for Cashier-Free Shopping
Jan 04, 2020
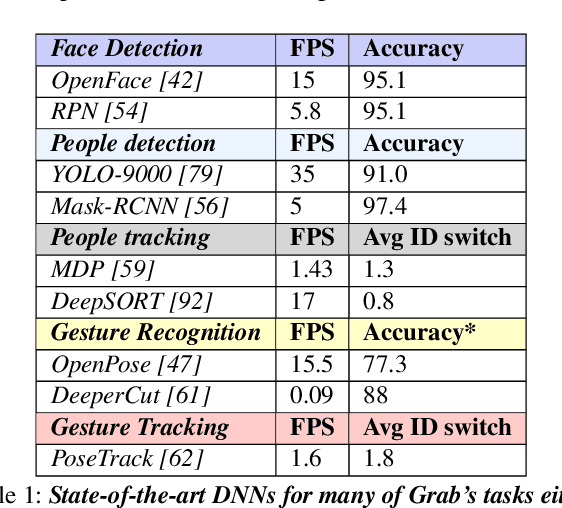
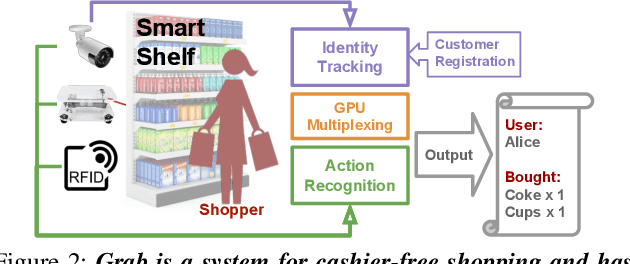
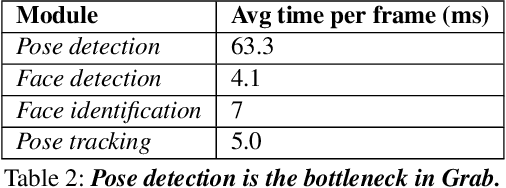
Cashier-free shopping systems like Amazon Go improve shopping experience, but can require significant store redesign. In this paper, we propose Grab, a practical system that leverages existing infrastructure and devices to enable cashier-free shopping. Grab needs to accurately identify and track customers, and associate each shopper with items he or she retrieves from shelves. To do this, it uses a keypoint-based pose tracker as a building block for identification and tracking, develops robust feature-based face trackers, and algorithms for associating and tracking arm movements. It also uses a probabilistic framework to fuse readings from camera, weight and RFID sensors in order to accurately assess which shopper picks up which item. In experiments from a pilot deployment in a retail store, Grab can achieve over 90% precision and recall even when 40% of shopping actions are designed to confuse the system. Moreover, Grab has optimizations that help reduce investment in computing infrastructure four-fold.
Satyam: Democratizing Groundtruth for Machine Vision
Nov 08, 2018
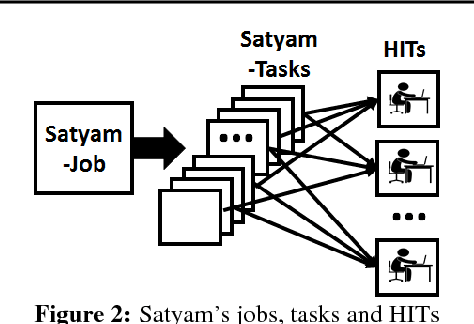
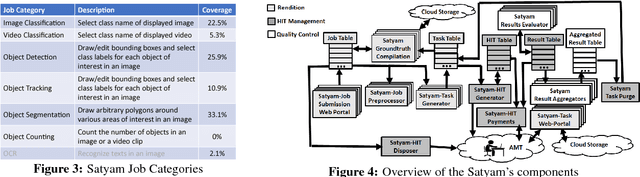

The democratization of machine learning (ML) has led to ML-based machine vision systems for autonomous driving, traffic monitoring, and video surveillance. However, true democratization cannot be achieved without greatly simplifying the process of collecting groundtruth for training and testing these systems. This groundtruth collection is necessary to ensure good performance under varying conditions. In this paper, we present the design and evaluation of Satyam, a first-of-its-kind system that enables a layperson to launch groundtruth collection tasks for machine vision with minimal effort. Satyam leverages a crowdtasking platform, Amazon Mechanical Turk, and automates several challenging aspects of groundtruth collection: creating and launching of custom web-UI tasks for obtaining the desired groundtruth, controlling result quality in the face of spammers and untrained workers, adapting prices to match task complexity, filtering spammers and workers with poor performance, and processing worker payments. We validate Satyam using several popular benchmark vision datasets, and demonstrate that groundtruth obtained by Satyam is comparable to that obtained from trained experts and provides matching ML performance when used for training.