 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimum Cost Active Labeling
Paper and Code

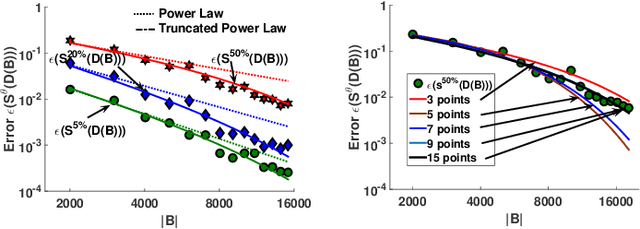
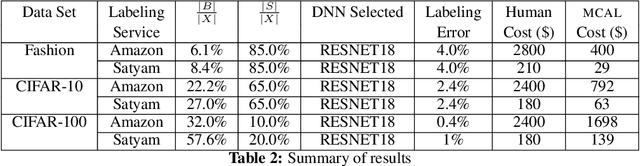
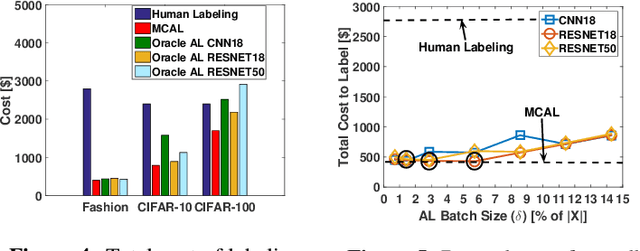
Labeling a data set completely is important for groundtruth generation. In this paper, we consider the problem of minimum-cost labeling: classifying all images in a large data set with a target accuracy bound at minimum dollar cost. Human labeling can be prohibitive, so we train a classifier to accurately label part of the data set. However, training the classifier can be expensive too, particularly with active learning. Our min-cost labeling uses a variant of active learning to learn a model to predict the optimal training set size for the classifier that minimizes overall cost, then uses active learning to train the classifier to maximize the number of samples the classifier can correctly label. We validate our approach on well-known public data sets such as Fashion, CIFAR-10, and CIFAR-100. In some cases, our approach has 6X lower overall cost relative to human labeling, and is always cheaper than the cheapest active learning strategy.