 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
Instance-level Randomization: Toward More Stable LLM Evaluations
Sep 16, 2025



Evaluations of large language models (LLMs) suffer from instability, where small changes of random factors such as few-shot examples can lead to drastic fluctuations of scores and even model rankings. Moreover, different LLMs can have different preferences for a certain setting of random factors. As a result, using a fixed setting of random factors, which is often adopted as the paradigm of current evaluations, can lead to potential unfair comparisons between LLMs. To mitigate the volatility of evaluations, we first theoretically analyze the sources of variance induced by changes in random factors. Targeting these specific sources, we then propose the instance-level randomization (ILR) method to reduce variance and enhance fairness in model comparisons. Instead of using a fixed setting across the whole benchmark in a single experiment, we randomize all factors that affect evaluation scores for every single instance, run multiple experiments and report the averaged score. Theoretical analyses and empirical results demonstrate that ILR can reduce the variance and unfair comparisons caused by random factors, as well as achieve similar robustness level with less than half computational cost compared with previous methods.
Bipartite Flat-Graph Network for Nested Named Entity Recognition
May 01, 2020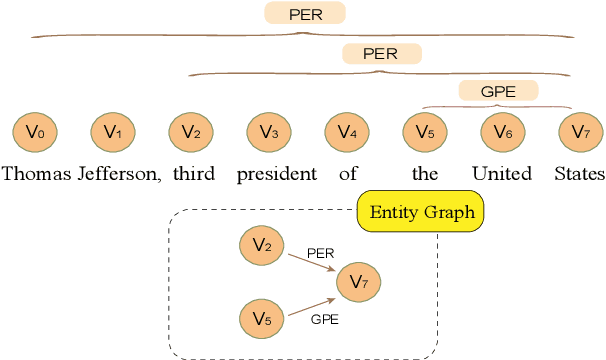
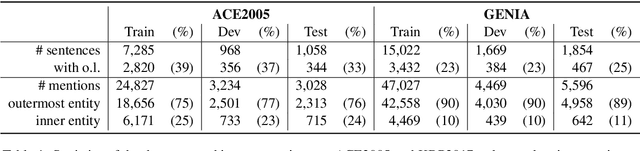
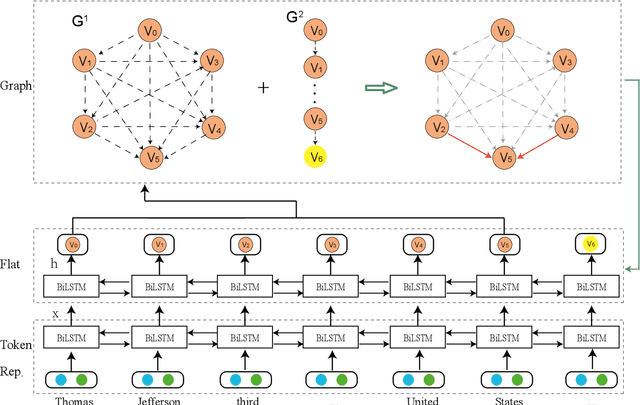
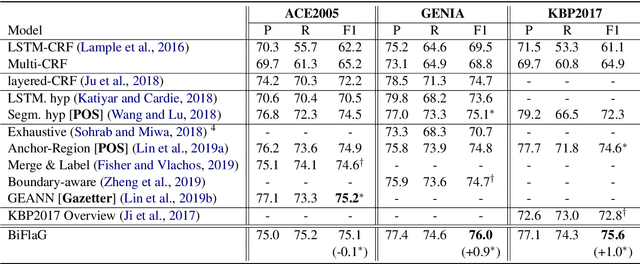
In this paper, we propose a novel bipartite flat-graph network (BiFlaG) for nested named entity recognition (NER), which contains two subgraph modules: a flat NER module for outermost entities and a graph module for all the entities located in inner layers. Bidirectional LSTM (BiLSTM) and graph convolutional network (GCN) are adopted to jointly learn flat entities and their inner dependencies. Different from previous models, which only consider the unidirectional delivery of information from innermost layers to outer ones (or outside-to-inside), our model effectively captures the bidirectional interaction between them. We first use the entities recognized by the flat NER module to construct an entity graph, which is fed to the next graph module. The richer representation learned from graph module carries the dependencies of inner entities and can be exploited to improve outermost entity predictions. Experimental results on three standard nested NER datasets demonstrate that our BiFlaG outperforms previous state-of-the-art models.
Hierarchical Contextualized Representation for Named Entity Recognition
Nov 19, 2019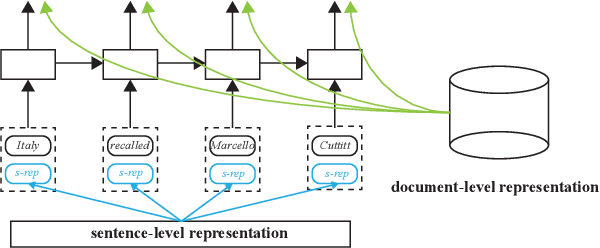

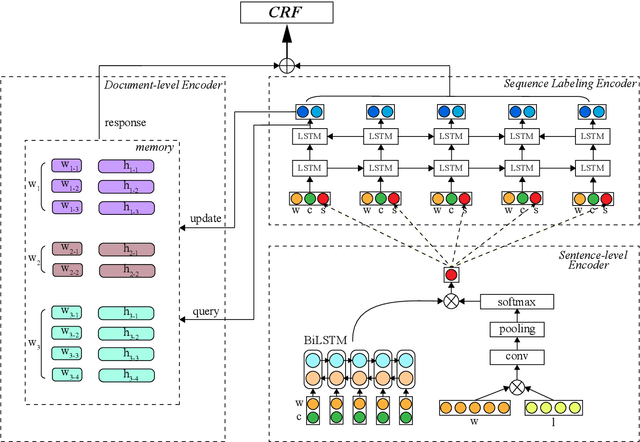
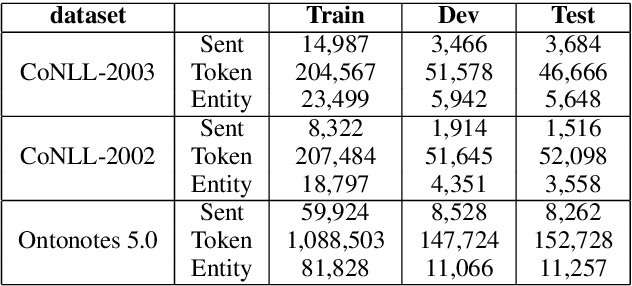
Named entity recognition (NER) models are typically based on the architecture of Bi-directional LSTM (BiLSTM). The constraints of sequential nature and the modeling of single input prevent the full utilization of global information from larger scope, not only in the entire sentence, but also in the entire document (dataset). In this paper, we address these two deficiencies and propose a model augmented with hierarchical contextualized representation: sentence-level representation and document-level representation. In sentence-level, we take different contributions of words in a single sentence into consideration to enhance the sentence representation learned from an independent BiLSTM via label embedding attention mechanism. In document-level, the key-value memory network is adopted to record the document-aware information for each unique word which is sensitive to similarity of context information. Our two-level hierarchical contextualized representations are fused with each input token embedding and corresponding hidden state of BiLSTM, respectively. The experimental results on three benchmark NER datasets (CoNLL-2003 and Ontonotes 5.0 English datasets, CoNLL-2002 Spanish dataset) show that we establish new state-of-the-art results.
Open Named Entity Modeling from Embedding Distribution
Aug 31, 2019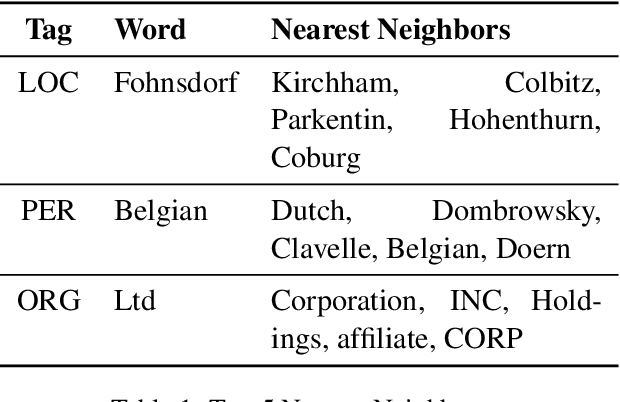
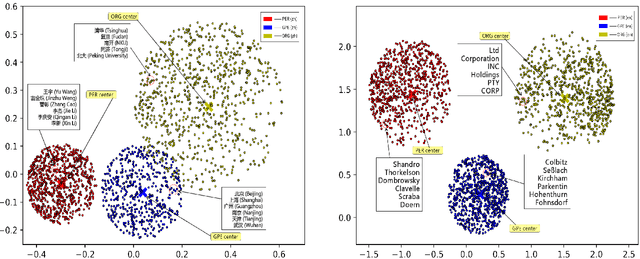

In this paper, we report our discovery on named entity distribution in general word embedding space, which helps an open definition on multilingual named entity definition rather than previous closed and constraint definition on named entities through a named entity dictionary, which is usually derived from huaman labor and replies on schedual update. Our initial visualization of monolingual word embeddings indicates named entities tend to gather together despite of named entity types and language difference, which enable us to model all named entities using a specific geometric structure inside embedding space,namely, the named entity hypersphere. For monolingual case, the proposed named entity model gives an open description on diverse named entity types and different languages. For cross-lingual case, mapping the proposed named entity model provides a novel way to build named entity dataset for resource-poor languages. At last, the proposed named entity model may be shown as a very useful clue to significantly enhance state-of-the-art named entity recognition systems generally.
Named Entity Recognition Only from Word Embeddings
Aug 31, 2019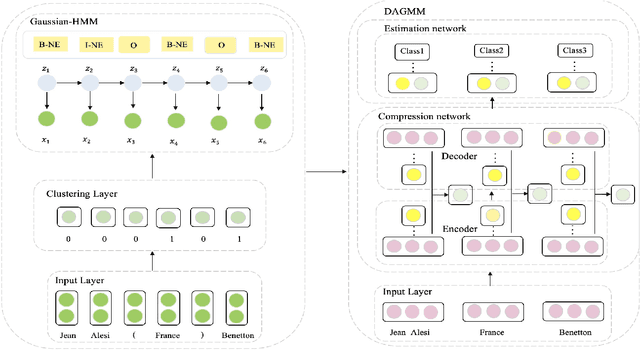
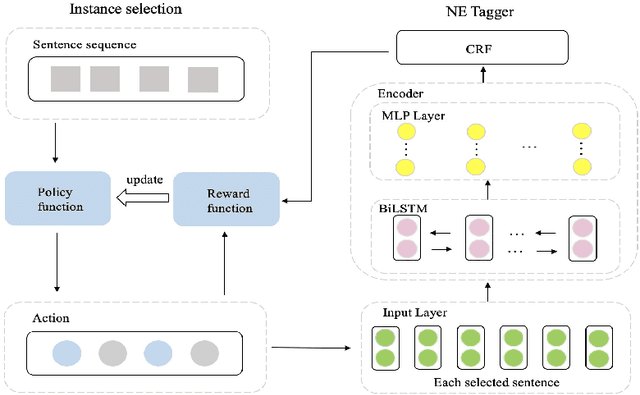

Deep neural network models have helped named entity (NE) recognition achieve amazing performance without handcrafting features. However, existing systems require large amounts of human annotated training data. Efforts have been made to replace human annotations with external knowledge (e.g., NE dictionary, part-of-speech tags), while it is another challenge to obtain such effective resources. In this work, we propose a fully unsupervised NE recognition model which only needs to take informative clues from pre-trained word embeddings. We first apply Gaussian Hidden Markov Model and Deep Autoencoding Gaussian Mixture Model on word embeddings for entity span detection and type prediction, and then further design an instance selector based on reinforcement learning to distinguish positive sentences from noisy sentences and refine these coarse-grained annotations through neural networks. Extensive experiments on CoNLL benchmark datasets demonstrate that our proposed light NE recognition model achieves remarkable performance without using any annotated lexicon or corpus.